 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++


Bing Images, also known as Bing Image Search, is a powerful search engine for photos, artwork, logos, screenshots, and other visual content across the web. It can also filter results based on prominent colors, image type, aspect ratio, dimensions, and much more.
With the Bing Images API from SerpApi, those same search results are accessible in simple JSON format, ready for any programming language or environment. SerpApi handles the HTML parsing, proxy network, captcha puzzles, and other challenges, so you can focus on your actual business or project, instead of maintaining a scraping tool.
Check out our other Bing search APIs for for scraping organic search results, videos, news, and more!
What can you scrape from Bing Images?
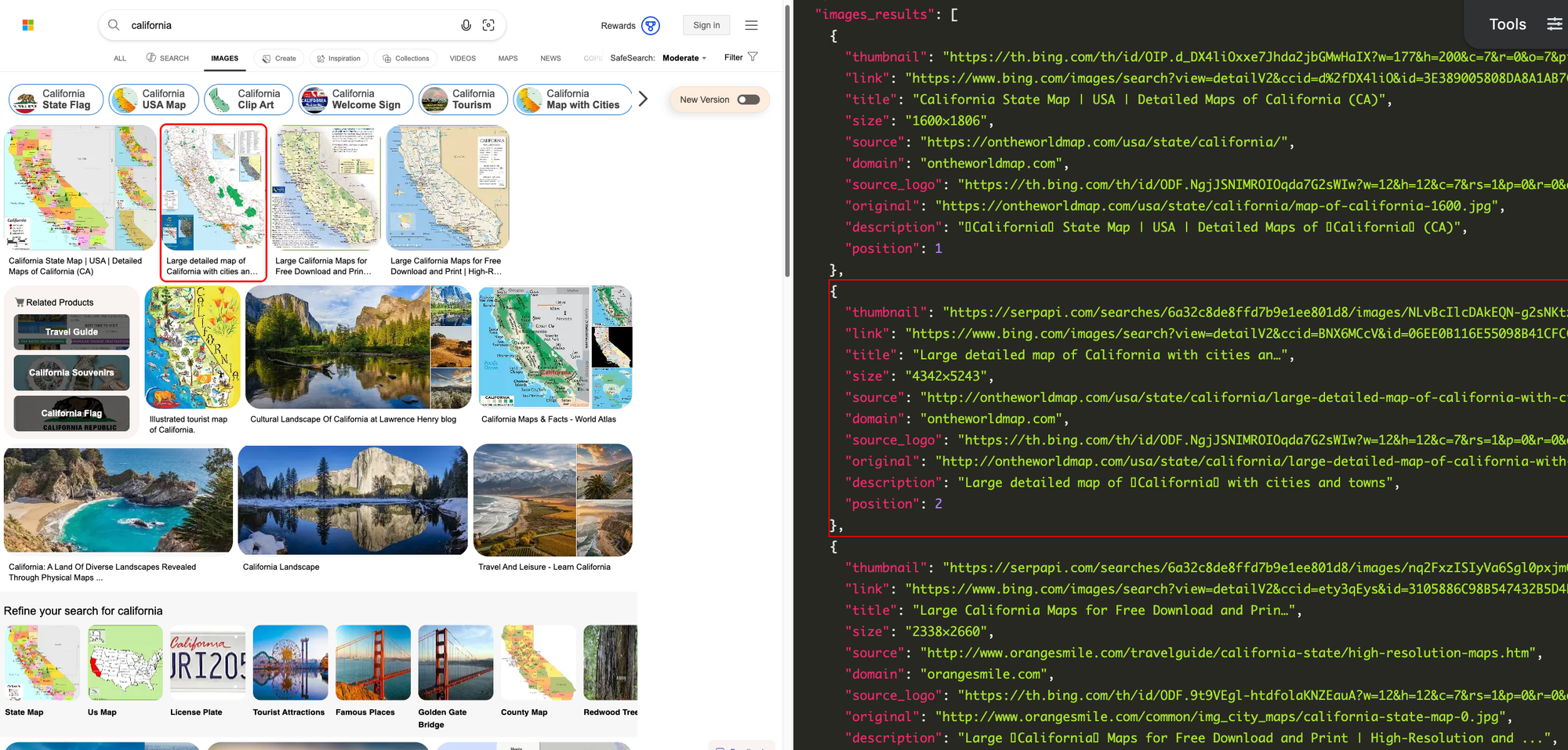
Here's everything you can pull from each image result, using the Bing Images API from SerpApi:
- Thumbnail: The URL for the thumbnail image, hosted on Bing's servers.
- Title: The detected title for the image, usually extracted from the title of the source page.
- Bing link: The URL for the image's full details page on Bing.
- Original link: The URL to the image file on its original domain.
- Size: The pixel dimensions of the image, measured in width × height (e.g.
873×492or1920x1080). - Domain: The web domain where the image is hosted (e.g.
apple.com). - Source: The URL for the icon (favicon) of the image's source domain, hosted on Bing's servers.
- Description: A text snippet for the image, extracted from its original source.
- Position: The image's position on the search results page, starting from the top of the page (e.g.
1or7).
The results may also include Bing's suggested searches and refined searches for the query, provided as text strings and Bing URLs.
Getting started with SerpApi
Before getting started with the Bing Images API, you need a free SerpApi account. That also includes access to other engines, like the Google Images API, Yahoo Images API, and Yandex Images API. You can upgrade to a paid account later if you need more search capacity, faster speeds, or other features.
First, you need to create an account and verify your email and other details. After that, get the API key from your account dashboard.
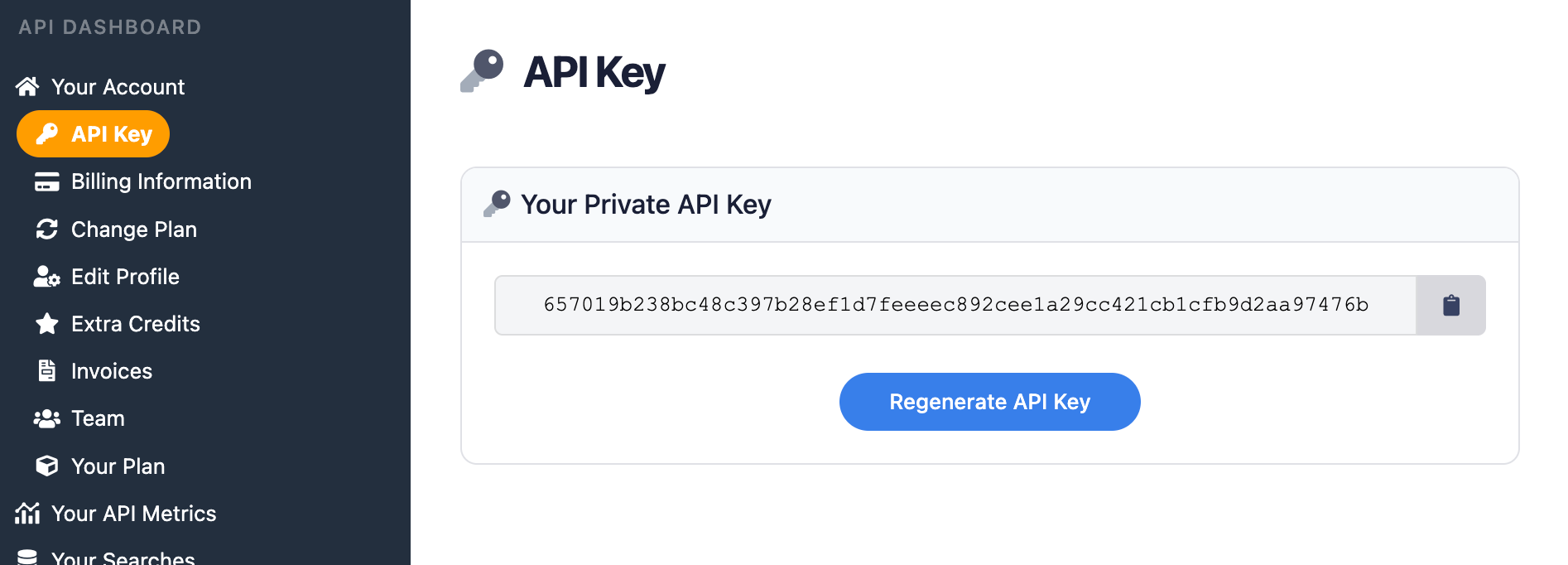
Make sure to store your API key in a safe location if you are sharing or publishing your code. If the key is leaked or stolen, you can make a new one from the SerpApi account dashboard.
Install the SerpApi library (optional)
You can use SerpApi's official libraries for Python, JavaScript, Ruby, Java, and other languages. They provide a simple wrapper around the API requests.
The libraries are not required, though. You can still make API calls with cURL, fetch() in Node.js, or anything else that can send GET requests and process a JSON response.
Review the Bing Images API documentation
Each API at SerpApi has extensive documentation that covers all the supported parameters and filters, code examples for popular languages, and example JSON responses. We're covering some of the basic usage in this post, but you can see more details at the Bing Images API page.
The only required parameter is q for the search query, but you can optionally specify the search region, pagination, search filters, and other settings.
How to scrape Bing Images results
If you have your API key, you're ready to start pulling data from Bing Images searches. The results will be identical across all libraries and GET requests, so use whichever method you want.
GET request
This will search for "New York" from the US region, using the Bing Images API in simple GET request:
https://serpapi.com/search.json?engine=bing_images&q=new+york&mkt=en-us&api_key=API_KEY_GOES_HEREThis is the same search again, but filtered to only images that Bing has detected as a photo, with a public domain license:
https://serpapi.com/search.json?engine=bing_images&q=new+york&mkt=en-us&photo=photo&license=L1&api_key=API_KEY_GOES_HEREYou can also use SerpApi's JSON Restrictor feature to trim the API response to specific values. This searches for "Dallas" and only returns the source page and original image URL for each result:
https://serpapi.com/search.json?engine=bing_images&q=dallas&mkt=en-us&json_restrictor=images_results[]{source,original}&api_key=API_KEY_GOES_HEREThis can be helpful if you're using an LLM with a limited context window, or if you just need more efficient parsing.
Python
Here's how you can search for "Empire State Building" from the US region, using the official SerpApi Python library, and display the title and original URL for each result:
import serpapi
client = serpapi.Client(api_key=YOUR_KEY_GOES_HERE)
response = client.search({
"engine": "bing_images",
"q": "empire state building",
"mkt": "en-us"
})
for item in response["images_results"]:
print(f"{item['title']} - {item['original']}\n")This runs the same search, but only displays the image with the highest (original) resolution, by checking the size value on each result:
import serpapi
client = serpapi.Client(api_key=YOUR_KEY_GOES_HERE)
response = client.search({
"engine": "bing_images",
"q": "empire state building",
"mkt": "en-us"
})
highestRes = ""
for item in response["images_results"]:
# Create a starting point
if not highestRes:
highestRes = item
else:
# Get individual width and height from "size" string
this_a, this_b = map(float, item["size"].split("×"))
current_a, current_b = map(float, highestRes["size"].split("×"))
# Multiply width and height on both this item and current comparison point
if (this_a * this_b) > (current_a * current_b):
highestRes = item
# Print the highest-resolution result
print(highestRes)Ruby
This runs an image search for "Chicago" in the US region using the SerpApi Ruby gem, then prints the full data for each result:
require "serpapi"
# Run the first search and get the ID
client = SerpApi::Client.new(
engine: "bing_images",
q: "chicago",
mkt: "en-us",
api_key: YOUR_KEY_GOES_HERE
)
for result in client.search[:images_results] do
p result
endHere's how you can search for only extra large (wallpaper) images with a public domain (L1) license, and display the original URL for each item:
require "serpapi"
# Run the first search and get the ID
client = SerpApi::Client.new(
engine: "bing_images",
q: "chicago",
mkt: "en-us",
imagesize: "wallpaper",
license: "L1",
api_key: YOUR_KEY_GOES_HERE
)
for result in client.search[:images_results] do
p result[:original]
endJavaScript and Node.js
This uses the official SerpApi JavaScript library to search for "Seattle" images, in the US region with black and white colors, and prints each result:
import { getJson } from 'serpapi';
const search = await getJson({
engine: "bing_images",
q: "seattle",
mkt: "en-us",
color2: "bw",
api_key: YOUR_KEY_GOES_HERE
});
for (const item in search?.images_results) {
console.log(search.images_results[item]);
}This searches for "Atlanta" in the US region, and only prints the highest-resolution image result, by iterating over the size value for each image:
import { getJson } from 'serpapi';
const search = await getJson({
engine: "bing_images",
q: "atlanta",
mkt: "en-us",
api_key: YOUR_KEY_GOES_HERE
});
let highestRes;
for (const item in search?.images_results) {
if (!highestRes) {
// Create a starting point
highestRes = search.images_results[item];
} else if ("size" in search.images_results[item]) {
// Get individual width and height from "size" string
const [this_w, this_h] = search.images_results[item].size.split(/[×x*]/).map(Number);
const [highest_w, highest_h] = highestRes.size.split(/[×x*]/).map(Number);
// Replace the comparison point if this item is cheaper
if ((this_w * this_h) > (highest_w * highest_h)) {
highestRes = search.images_results[item];
}
}
}
console.log(highestRes);cURL
Here's how you can search for "California" images with the Bing Images API in a cURL request:
curl --get https://serpapi.com/search \
-d api_key="YOUR_KEY_GOES_HERE" \
-d engine="bing_images" \
-d q="california" \
-d mkt="en-us"Other languages and no-code solutions
You can still use the API directly with GET requests, even if there isn't an official SerpApi integration for your preferred environment or language. SerpApi also works with Make.com, N8N, and other tools.
Conclusion
Bing Images can help you find photos, illustrations, and other visual content from across the web. With the Bing Images API from SerpApi, you can pull all those results into any automation or programming language.
If you're not getting the best results from Bing, SerpApi also provides a Google Images API, Yahoo Images API, and Yandex Images API. You can access them with the same account and search credits as Bing Images, and even run the same search across multiple engines to get more diverse results.
If you need help using SerpApi, please contact us.
