 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++




There are thousands of job boards on the internet. It is time-consuming to search for a job on each job board. Google Jobs is a job search engine that aggregates job listings from various sources, including job boards, company career pages, and staffing agencies.

Scraping Google Jobs Results helps you find comprehensive job listings, customized searches - focus on specific job titles, locations, companies, or job types to find the most relevant positions.
Furthermore, you can receive real-time updates on new job listings that match your criteria, analyze job market trends, salary ranges, and demand for specific skills by scraping and processing job data.
Why use an API?
- No need to create a parser from scratch and maintain it.
- Bypass blocks from Google: solve CAPTCHA or solve IP blocks.
- Pay for proxies and CAPTCHA solvers.
- Don't need to use browser automation.
SerpApi handles everything on the backend, with fast response times under ~2.5 seconds (~1.2 seconds with Ludicrous speed) per request and without browser automation, which is much faster. Response times and status rates are shown under SerpApi Status page.

Setting up a SerpApi account
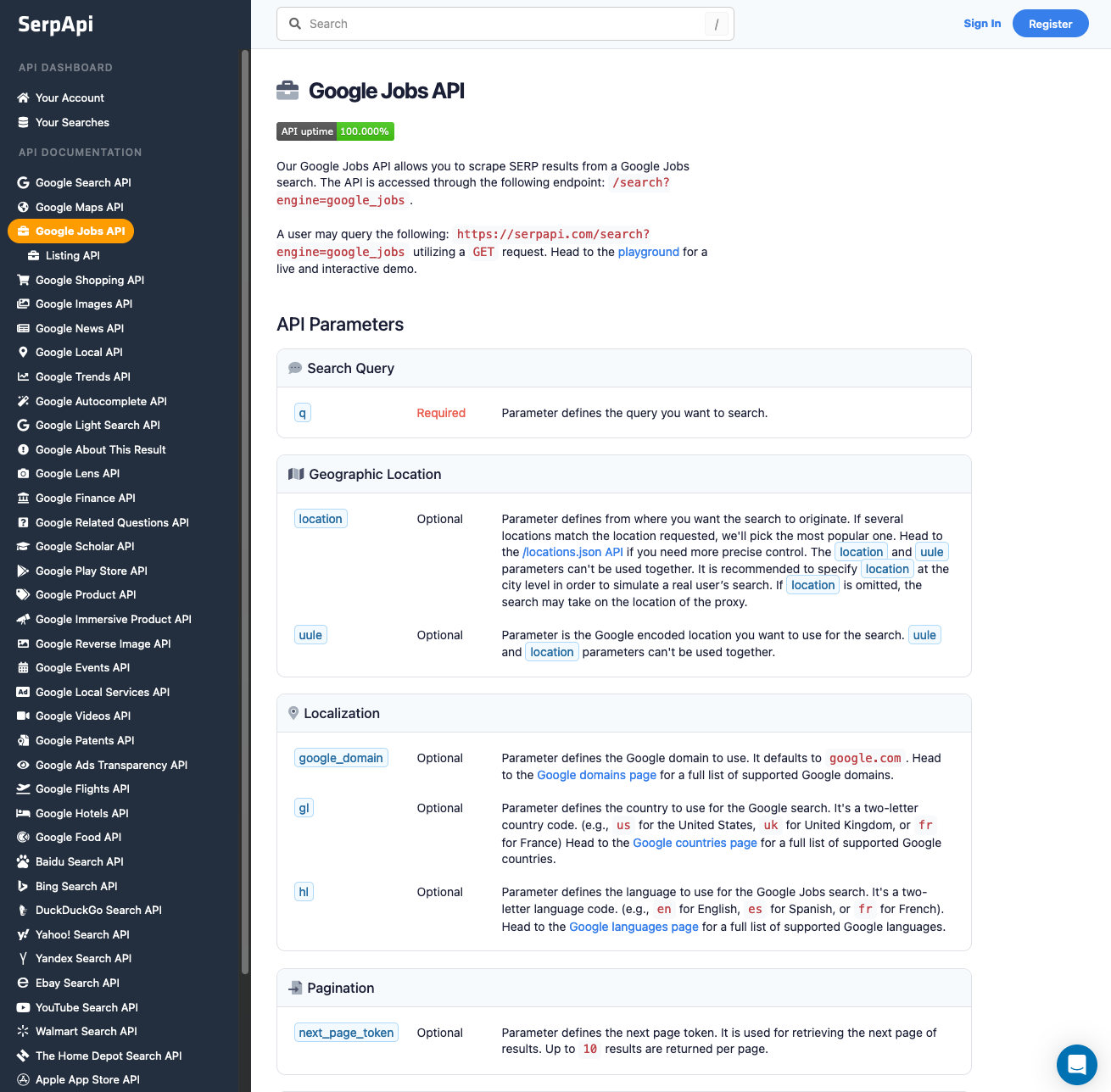
SerpApi offers a free plan for newly created accounts. Head to the sign-up page to register an account and complete your first search with our interactive playground. When you want to do more searches with us, please visit the pricing page.
Once you are familiar with all results, you can use SERP APIs with your API Key.
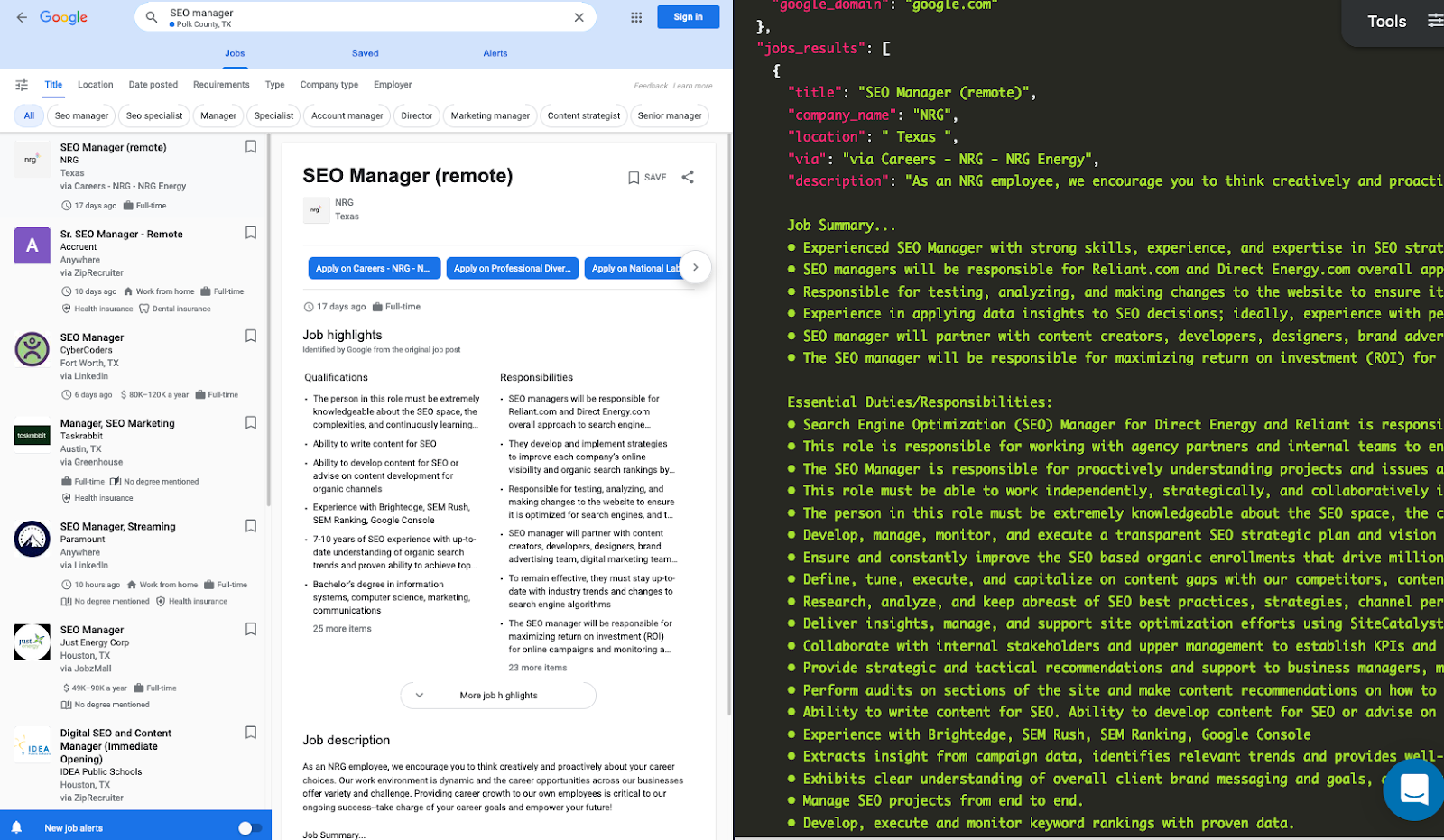
Scrape your first Google Jobs results with SerpApi
Head to the Google Jobs Results from the documentation on SerpApi for details.
In this tutorial, we will scrape job results when searching with "SEO manager" keyword. The data contains: "title", "company", "location", "description", "logo", and more. You can also scrape more information with SerpApi.
Python tutorial
First, you need to install the SerpApi client library.
pip install google-search-resultsSet up the SerpApi credentials and search.
from serpapi import GoogleSearch
import os, json
params = {
'api_key': 'YOUR_API_KEY', # your serpapi api
'engine': 'google_jobs', # SerpApi search engine
'gl': 'us',
'hl': 'en',
'q': 'SEO manager'
}
The parameters gl and hl represents the country and languages to use for the Google Jobs search. And this q is the search query you want to search.
To retrieve Google Jobs Results for a given search term, you can use the following code:
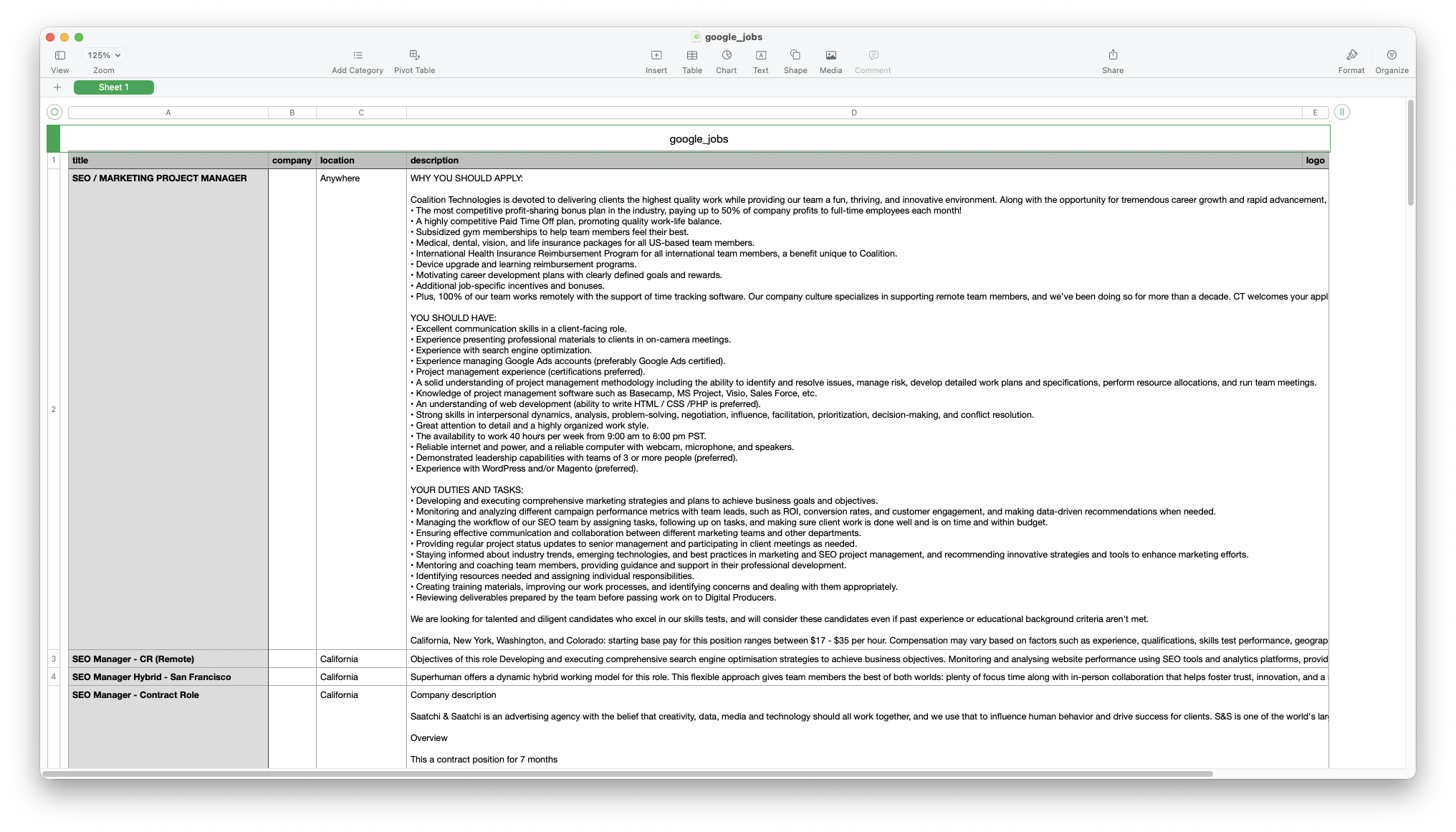
results = GoogleSearch(params).get_dict()['jobs_results']You can store Jobs Results JSON data in databases or export it to a CSV file.
import csv
header = ['title', 'company', 'location', 'description', 'logo']
with open('google_jobs.csv', 'w', encoding='UTF8', newline='') as f:
writer = csv.writer(f)
writer.writerow(header)
for item in results:
print(item)
writer.writerow([item.get('title'), item.get('company'), item.get('location'), item.get('description'), item.get('logo')])
JavaScript Tutorial (Node.js)
First, we need to install google-search-results-nodejs:
npm i google-search-results-nodejsThen, declare SerpApi from google-search-results-nodejs library and define new search instance with your API key from SerpApi:
const SerpApi = require("google-search-results-nodejs");
const search = new SerpApi.GoogleSearch(API_KEY);Next, write a search query and the necessary parameters for making a request:
const searchString = "SEO manager"; // what we want to search
const params = {
engine: "google_jobs", // search engine
q: searchString, // search query
hl: "en", // Parameter defines the language to use for the Google search
uule: "w+CAIQICIKY2FsaWZvcm5pYQ", // encoded location
};uule parameter is an encoded location parameter. You can make it using UULE Generator for Google.Wrap the search method from the SerpApi library in a promise to further work with the search results:
const getJson = () => {
return new Promise((resolve) => {
search.json(params, resolve);
});
};And finally, we declare the function getResult to loop through all pages of job results using Google's pagination method next_page_token
const getResults = async () => {
const results = []; // array to store all scraped jobs
...
};
Why an array?
We will collect results from multiple pages until no further results are available.
Next, we need to use while loop to fetch all pages. Inside the loop:
- We call the API
- Add the job results
- Look for
next_page_token - Stop the loop when there is no next page
while (true) {
const json = await getJson();
if (!json.jobs_results || json.jobs_results.length === 0) break;
results.push(...json.jobs_results);
const nextToken = json.serpapi_pagination?.next_page_token;
if (!nextToken) break;
params.next_page_token = nextToken;
}
return results;After we run the getResults function and print all the received information in the console with the console.dir method, which allows you to use an object with the necessary parameters to change default output options:
getResults().then((result) => console.dir(result, { depth: null }));
The example of the first result output in JSON format:
[
{
"title": "SEO / MARKETING PROJECT MANAGER",
"company_name": "Coalition Technologies",
"location": "Anywhere",
"via": "Indeed",
"share_link": "https://www.google.com/search?ibp=htl;jobs&q=SEO+manager&htidocid=MGL1DlRMDYIJ9S1TAAAAAA%3D%3D&hl=en-US&shndl=37&shmd=H4sIAAAAAAAA_xWMsQrCMBQAce0nOL3BSbARQQedSgnFiq3U7iUJzyQS80pfhv6LP2tdbriDy76r7PSULQi4F91N9temgkfX1rLsF9MUlexgBzVpYFSTcUARKiIbcH1xKY18FoI55JaTSt7khj6CImqaxZs0_zGwUxOOQSUcDsf9nI_RbjclqeCTX3Y9GhcpkPXI4COUS3jRFL36AY0OyBueAAAA&shmds=v1_AdeF8KjbnyFz4FzqsHm60hu6qka1jqoLYTCYhPYelMLNNggF9A&shem=bdslc,damc&source=sh/x/job/li/m1/1#fpstate=tldetail&htivrt=jobs&htiq=SEO+manager&htidocid=MGL1DlRMDYIJ9S1TAAAAAA%3D%3D",
"thumbnail": "https://serpapi.com/searches/6938c00da3ce841d0a59c1a2/images/449d886478e4414c3cef1330654d493a57f630269a9ef9d9924b5c21c43399a2.jpeg",
"extensions": [
"6 days ago",
"17–35 an hour",
"Work from home",
"Full-time",
"No degree mentioned",
"Dental insurance",
"Health insurance",
"Paid time off"
],
"detected_extensions": {
"posted_at": "6 days ago",
"salary": "17–35 an hour",
"work_from_home": true,
"schedule_type": "Full-time",
"qualifications": "No degree mentioned",
"dental_coverage": true,
"health_insurance": true,
"paid_time_off": true
},
"description": "WHY YOU SHOULD APPLY:\n\nCoalition Technologies is devoted to delivering clients the highest quality work while providing our team a fun, thriving, and innovative environment. Along with the opportunity for tremendous career growth and rapid advancement, CT offers:\n• The most competitive profit-sharing bonus plan in the industry, paying up to 50% of company profits to full-time employees each month!\n• A highly competitive Paid Time Off plan, promoting quality work-life balance.\n• Subsidized gym memberships to help team members feel their best.\n• Medical, dental, vision, and life insurance packages for all US-based team members.\n• International Health Insurance Reimbursement Program for all international team members, a benefit unique to Coalition.\n• Device upgrade and learning reimbursement programs.\n• Motivating career development plans with clearly defined goals and rewards.\n• Additional job-specific incentives and bonuses.\n• Plus, 100% of our team works remotely with the support of time tracking software. Our company culture specializes in supporting remote team members, and we’ve been doing so for more than a decade. CT welcomes your application, wherever in the world it's coming from!\n\nYOU SHOULD HAVE:\n• Excellent communication skills in a client-facing role.\n• Experience presenting professional materials to clients in on-camera meetings.\n• Experience with search engine optimization.\n• Experience managing Google Ads accounts (preferably Google Ads certified).\n• Project management experience (certifications preferred).\n• A solid understanding of project management methodology including the ability to identify and resolve issues, manage risk, develop detailed work plans and specifications, perform resource allocations, and run team meetings.\n• Knowledge of project management software such as Basecamp, MS Project, Visio, Sales Force, etc.\n• An understanding of web development (ability to write HTML / CSS /PHP is preferred).\n• Strong skills in interpersonal dynamics, analysis, problem-solving, negotiation, influence, facilitation, prioritization, decision-making, and conflict resolution.\n• Great attention to detail and a highly organized work style.\n• The availability to work 40 hours per week from 9:00 am to 6:00 pm PST.\n• Reliable internet and power, and a reliable computer with webcam, microphone, and speakers.\n• Demonstrated leadership capabilities with teams of 3 or more people (preferred).\n• Experience with WordPress and/or Magento (preferred).\n\nYOUR DUTIES AND TASKS:\n• Developing and executing comprehensive marketing strategies and plans to achieve business goals and objectives.\n• Monitoring and analyzing different campaign performance metrics with team leads, such as ROI, conversion rates, and customer engagement, and making data-driven recommendations when needed.\n• Managing the workflow of our SEO team by assigning tasks, following up on tasks, and making sure client work is done well and is on time and within budget.\n• Ensuring effective communication and collaboration between different marketing teams and other departments.\n• Providing regular project status updates to senior management and participating in client meetings as needed.\n• Staying informed about industry trends, emerging technologies, and best practices in marketing and SEO project management, and recommending innovative strategies and tools to enhance marketing efforts.\n• Mentoring and coaching team members, providing guidance and support in their professional development.\n• Identifying resources needed and assigning individual responsibilities.\n• Creating training materials, improving our work processes, and identifying concerns and dealing with them appropriately.\n• Reviewing deliverables prepared by the team before passing work on to Digital Producers.\n\nWe are looking for talented and diligent candidates who excel in our skills tests, and will consider these candidates even if past experience or educational background criteria aren't met.\n\nCalifornia, New York, Washington, and Colorado: starting base pay for this position ranges between $17 - $35 per hour. Compensation may vary based on factors such as experience, qualifications, skills test performance, geographic location, and seniority of the position offered. Outside of California, New York, Washington, and Colorado compensation may fall outside the above ranges.",
"job_highlights": [
{
"title": "Qualifications",
"items": [
"Excellent communication skills in a client-facing role",
"Experience presenting professional materials to clients in on-camera meetings",
"Experience with search engine optimization",
"Experience managing Google Ads accounts (preferably Google Ads certified)",
"A solid understanding of project management methodology including the ability to identify and resolve issues, manage risk, develop detailed work plans and specifications, perform resource allocations, and run team meetings",
"Knowledge of project management software such as Basecamp, MS Project, Visio, Sales Force, etc",
"Strong skills in interpersonal dynamics, analysis, problem-solving, negotiation, influence, facilitation, prioritization, decision-making, and conflict resolution",
"Great attention to detail and a highly organized work style",
"The availability to work 40 hours per week from 9:00 am to 6:00 pm PST",
"Reliable internet and power, and a reliable computer with webcam, microphone, and speakers",
"We are looking for talented and diligent candidates who excel in our skills tests, and will consider these candidates even if past experience or educational background criteria aren't met"
]
},
{
"title": "Benefits",
"items": [
"The most competitive profit-sharing bonus plan in the industry, paying up to 50% of company profits to full-time employees each month!",
"A highly competitive Paid Time Off plan, promoting quality work-life balance",
"Subsidized gym memberships to help team members feel their best",
"Medical, dental, vision, and life insurance packages for all US-based team members",
"International Health Insurance Reimbursement Program for all international team members, a benefit unique to Coalition",
"Device upgrade and learning reimbursement programs",
"Motivating career development plans with clearly defined goals and rewards",
"Additional job-specific incentives and bonuses",
"Plus, 100% of our team works remotely with the support of time tracking software",
"California, New York, Washington, and Colorado: starting base pay for this position ranges between $17 - $35 per hour",
"Compensation may vary based on factors such as experience, qualifications, skills test performance, geographic location, and seniority of the position offered"
]
},
{
"title": "Responsibilities",
"items": [
"Developing and executing comprehensive marketing strategies and plans to achieve business goals and objectives",
"Monitoring and analyzing different campaign performance metrics with team leads, such as ROI, conversion rates, and customer engagement, and making data-driven recommendations when needed",
"Managing the workflow of our SEO team by assigning tasks, following up on tasks, and making sure client work is done well and is on time and within budget",
"Ensuring effective communication and collaboration between different marketing teams and other departments",
"Providing regular project status updates to senior management and participating in client meetings as needed",
"Staying informed about industry trends, emerging technologies, and best practices in marketing and SEO project management, and recommending innovative strategies and tools to enhance marketing efforts",
"Mentoring and coaching team members, providing guidance and support in their professional development",
"Identifying resources needed and assigning individual responsibilities",
"Creating training materials, improving our work processes, and identifying concerns and dealing with them appropriately",
"Reviewing deliverables prepared by the team before passing work on to Digital Producers"
]
}
],
"apply_options": [
{
"title": "Indeed",
"link": "https://www.indeed.com/viewjob?jk=8da37b6b944ed7c9&utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Teal",
"link": "https://www.tealhq.com/job/seo-marketing-project-manager_1fd318fe-84dc-4fab-8718-4804cac34189?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Glassdoor",
"link": "https://www.glassdoor.com/job-listing/seo-marketing-project-manager-ct-JV_KO0,29_KE30,32.htm?jl=1009958481004&utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Ladders",
"link": "https://www.theladders.com/job-listing/707673798828335825/seo-marketing-project-manager.htm?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Talents By Vaia",
"link": "https://talents.vaia.com/companies/coalition-technologies/seo-marketing-project-manager-28754884/?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Qureos",
"link": "https://app.qureos.com/jobs/seo-marketing-project-manager-1764846504670?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "BeBee",
"link": "https://us.bebee.com/job/691a89882c474926ab71dae2e946ec89?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
}
],
"job_id": "eyJqb2JfdGl0bGUiOiJTRU8gLyBNQVJLRVRJTkcgUFJPSkVDVCBNQU5BR0VSIiwiY29tcGFueV9uYW1lIjoiQ29hbGl0aW9uIFRlY2hub2xvZ2llcyIsImFkZHJlc3NfY2l0eSI6IkNhbGlmb3JuaWEiLCJodGlkb2NpZCI6Ik1HTDFEbFJNRFlJSjlTMVRBQUFBQUE9PSIsInV1bGUiOiJ3K0NBSVFJQ0lLWTJGc2FXWnZjbTVwWVEiLCJobCI6ImVuIn0="
},
...
...
...
]This example uses Python and Node.js, but you can also use your favorite programming languages, like Ruby, Java, PHP and more.
Related Post
Check out blog post below if you want to learn more about advanced filter to get specific jobs directly from your query:

If you have any questions, please feel free to contact me.