 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

Intro
Currently, we don't have an API that supports extracting data from the Yahoo! Finance page.
This blog post is to show you way how you can do it yourself as we noticed quite a few questions on Stackoverflow about scraping Yahoo! Finance and decided to create a blog about it. The provided DIY solution can be used for personal use.
What will be scraped

Difference between existing Yahoo! Finance parsers
Since Yahoo! Finance deprecated their API there're a lot of custom solutions out there. The differences between those parsers and the one you'll see below are:
- Firstly, this blog post is more educational rather than a complete solution.
- Secondly, all/most of the existing Yahoo! Finance parsers (at least those that I looked at) extract only ticket(s) data, without news results that Yahoo! Finance has.
Process
You can access and navigate through header stock results, news results json string data at jsonblob here.
Dadroit was used to preview json and copy paths to a specific key, value. Here's what UI looks like:
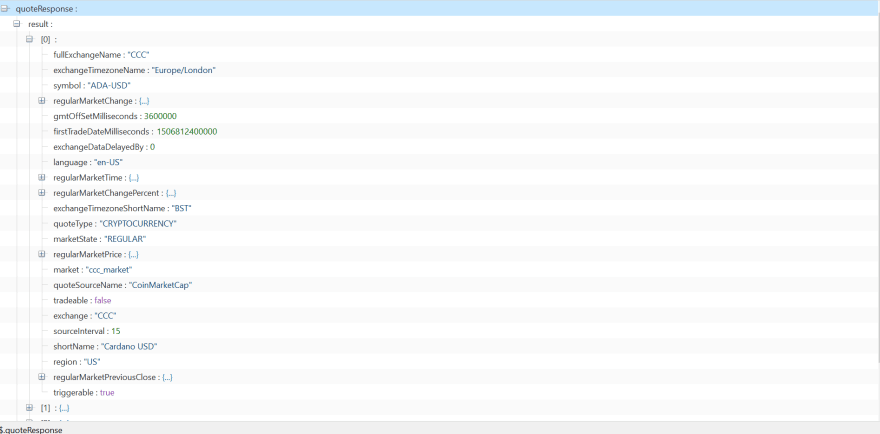
Get header stock results
Firstly, we need to locate where the data is located since we can't just use CSS selectors to extract the data because it is dynamically updating from the server.
The way I found where the data is located is very simple. Just copied the stock name and pasted it in the source code and checked if there's a match under the <script> tags.

After several matches were found in the same place under the <script> tag I began to look where the <script> tag starts and ends in order to extract the correct one using regular expression. Here's the start of the needed <script> tag.
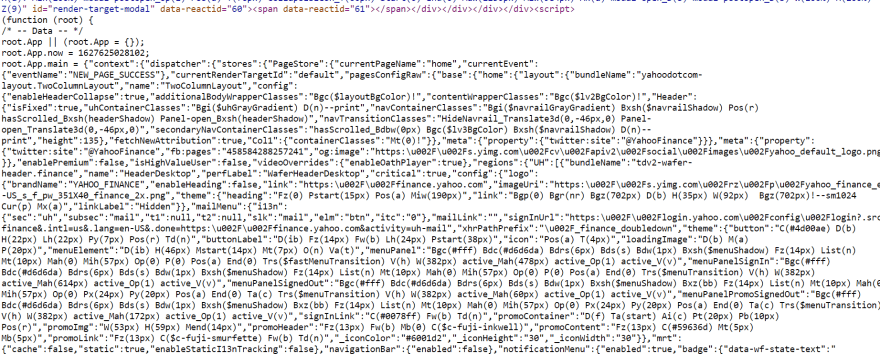
And the end of the <script> tag.

Then, regular expression comes into play to extract JSON string from the <script> tag. Here's a screenshot to see what is being captured (link to regular expression):
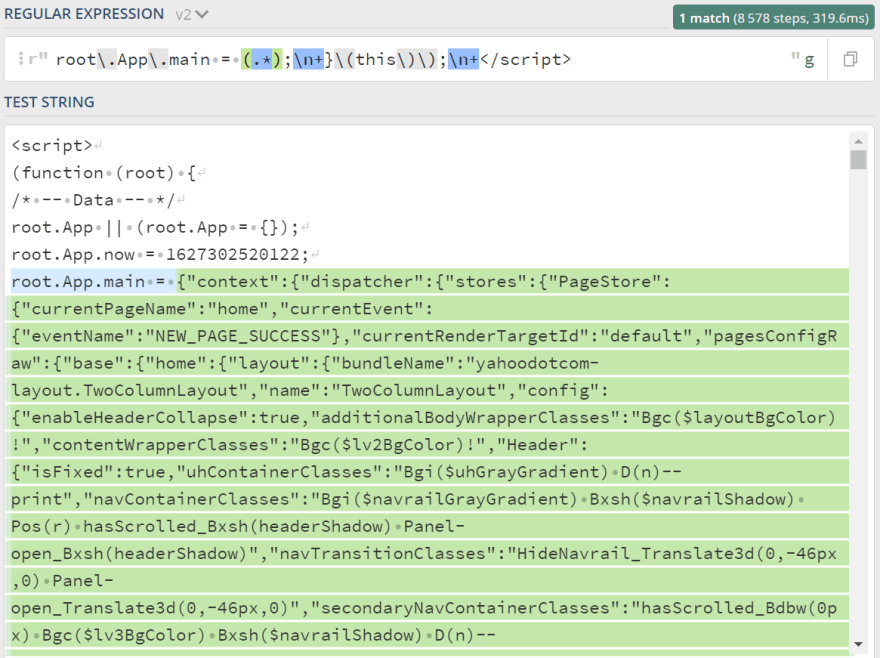
Note: There's obviously a better regex that could be used, I used the easiest, a very basic one.
Next is to extract the data and convert it to iterable JSON string since re.findall() returns a list, ''.join() making it a string to use json.loads() in the next step.
matched_string = ''.join(re.findall(r'root\.App\.main = (.*);\n+}\(this\)\);\n+</script>', str(all_script_tags)))
matched_string_json = json.loads(matched_string)After that, the for key, value in dict(...).items() option was used to make the code shorter and easier.
.items() returns a key, value pair so I don't have to specify which stock symbol to iterate over.
It will iterate over each available stock from the response instead and will substitute the correct stock key symbol with appropriate value data.
for key, value in dict(matched_string_json['context']['dispatcher']['stores']['StreamDataStore']['quoteData']).items():
# extracting header stocks data
# iterating over "value" variable
Because json response contains unique stock key symbols and creating a different function for each stock symbol will lead to a lot of code, and if some symbol will be changed in the future, it will throw an error.

If you want to iterate over specific stocks, then you can skip this step and write few functions just to iterate over specific stock results.
Example of Header stock response:
{
"sourceInterval": 30,
"exchange": "NYB",
"regularMarketTime": {
"raw": 1627325996,
"fmt": "2:59PM EDT"
},
"shortName": "10-Yr Bond",
"exchangeTimezoneName": "America/New_York",
"regularMarketChange": {
"raw": 0,
"fmt": "0.0000"
},
"regularMarketPreviousClose": {
"raw": 1.276,
"fmt": "1.2760"
},
"exchangeTimezoneShortName": "EDT",
"exchangeDataDelayedBy": 30,
"priceHint": 4,
"regularMarketPrice": {
"raw": 1.276,
"fmt": "1.2760"
},
"triggerable": false,
"gmtOffSetMilliseconds": -14400000,
"firstTradeDateMilliseconds": -252356400000,
"region": "US",
"marketState": "REGULAR",
"quoteType": "INDEX",
"symbol": "^TNX",
"language": "en-US",
"market": "us24_market",
"regularMarketChangePercent": {
"raw": 0,
"fmt": "0.00%"
},
"fullExchangeName": "NYBOT",
"tradeable": false
}
Get Top News Results
for top_news_result_index, top_news in enumerate(matched_string_json_stream):
# extracting data
Get Top News Video Results
for top_news_video_index, top_news_video in enumerate(matched_string_json_video):
# extracting data
Get Multiuse News Results
for multiuse_index, multiuse_news in enumerate(matched_string_json_multiuse):
# extracting data
Get Scrolling News Results
for yahoo_news_index in matched_string_json['context']['dispatcher']['stores']['StreamStore']['streams']['mega.c']['data']['stream_items']:
# extracting data
Get Right Side Stocks Results
In the dev tools network tab, you can see requests being sent to the server with GET method, thus you can call them directly to get a json string.
In total, there're 11 URLs (might be changed in the future) but you can make a 1 request call with additional symbols added to the URL string without need to make 11 URL calls async. Look at yahoo_finance_urls.py.
Note: User-Agent needs to be used, otherwise, it will throw a 403 forbidden. What is my user-agent
The approach was the same as in the previous section of the post, where the received response was converted to a json string for further manipulation.
Headers tab

Preview tab

File Structure
Yahoo_Finance_Main.py
├── Yahoo_Finance_Header_Stocks_News.py
├── Yahoo_Finance_Right_Side_Stocks.py
└── Yahoo_Finance_Urls.py
Full Code
yahoo_finance_main.py
from yahoo_finance_right_side_stocks import yahoo_get_right_side_stocks
from yahoo_finance_header_stocks_news import (
yahoo_get_header_stock_data,
yahoo_get_top_news_data,
yahoo_get_top_news_video_results,
yahoo_get_multiuse_news_results,
yahoo_get_news_results,
)
yahoo_get_header_stock_data()
yahoo_get_top_news_data()
yahoo_get_top_news_video_results()
yahoo_get_multiuse_news_results()
yahoo_get_news_results()
yahoo_get_right_side_stocks()
yahoo_finance_header_stocks_news.py
import requests, lxml, json, re, datetime
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
"(KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
html = requests.get('https://finance.yahoo.com/', headers=headers)
soup = BeautifulSoup(html.text, 'lxml')
all_script_tags = soup.select('script')
# https://regex101.com/r/IJloEU/2
matched_string = ''.join(re.findall(r'root\.App\.main = (.*);\n+}\(this\)\);\n+</script>', str(all_script_tags)))
matched_string_json = json.loads(matched_string)
def yahoo_get_header_stock_data():
for key, value in dict(matched_string_json['context']['dispatcher']['stores']['StreamDataStore']['quoteData']).items():
symbol = value['symbol']
exchange = value['exchange']
full_exchange_name = value['fullExchangeName']
try:
short_name = value['shortName']
except:
short_name = 'no shorten name'
exchange_time_zone_name = value['exchangeTimezoneName']
regular_market_change = value['regularMarketChange']['fmt']
regular_market_previous_close = value['regularMarketPreviousClose']['fmt']
regular_market_price = value['regularMarketPrice']['fmt']
regular_market_change_percent = value['regularMarketChangePercent']['fmt']
market_state = value['marketState']
market = value['market']
quote_type = value['quoteType']
print(f'Symbol: {symbol}\n'
f'Short name: {short_name}\n'
f'Exchange: {exchange}\n'
f'Full exchange name: {full_exchange_name}\n'
f'Exchange timezone: {exchange_time_zone_name}\n'
f'Market state: {market_state}\n'
f'Market name: {market}\n'
f'Quote type: {quote_type}\n'
f'Market price: {regular_market_price}\n'
f'Market change: {regular_market_change}\n'
f'Market % change: {regular_market_change_percent}\n'
f'Market previous close: {regular_market_previous_close}\n')
def yahoo_get_top_news_data():
matched_string_json_stream = matched_string_json['context']['dispatcher']['stores']['ThreeAmigosStore']['data']['ntk']['stream']
for top_news_result_index, top_news in enumerate(matched_string_json_stream):
teaser = top_news['editorialContent']['teaser']
title = top_news['editorialContent']['title']
try:
source = top_news['editorialContent']['content']['provider']['displayName']
except:
source = None
try:
source_site_link = top_news['editorialContent']['content']['provider']['url']
except:
source_site_link = None
try:
canonical_url = top_news['editorialContent']['content']['canonicalUrl']['url']
except:
canonical_url = None
try:
canonical_url_website = top_news['editorialContent']['content']['canonicalUrl']['site']
except:
canonical_url_website = None
try:
click_through_url = top_news['editorialContent']['content']['clickThroughUrl']['url']
except:
click_through_url = None
try:
click_through_url_website = top_news['editorialContent']['content']['clickThroughUrl']['site']
except:
click_through_url_website = None
print(f'News result number: {top_news_result_index}\n'
f'Teaser: {teaser}\n'
f'Title: {title}\n'
f'Source: {source}\n'
f'Source website: {source_site_link}\n'
f'Canonical URL: {canonical_url}\n'
f'Canonical URL source: {canonical_url_website}\n'
f'Click through URL: {click_through_url}\n'
f'Click through website: {click_through_url_website}\n')
for resolution in top_news['editorialContent']['thumbnail']['resolutions']:
thumbnail_size = resolution['tag']
thumbnail_link = resolution['url']
print(f'{thumbnail_size} {thumbnail_link}')
def yahoo_get_top_news_video_results():
matched_string_json_video = matched_string_json['context']['dispatcher']['stores']['ThreeAmigosStore']['data']['videos']['stream']
for top_news_video_index, top_news_video in enumerate(matched_string_json_video):
video_title = top_news_video['content']['title']
video_summary = top_news_video['content']['summary']
video_duration_not_fixed = top_news_video['content']['duration']
# seconds converted to minutes
video_duration_fixed_time = datetime.timedelta(seconds=video_duration_not_fixed)
video_publication_date = top_news_video['content']['pubDate']
vide_provider_name = top_news_video['content']['provider']['displayName']
video_canonical_url = top_news_video['content']['canonicalUrl']['url']
video_click_through_url = top_news_video['content']['clickThroughUrl']['url']
print(f'Video number: {top_news_video_index}\n'
f'Title: {video_title}\nSummary: {video_summary}\n'
f'Duration: {video_duration_fixed_time}\n'
f'Publication date: {video_publication_date}\n'
f'Provider: {vide_provider_name}\n'
f'Canonical URL: {video_canonical_url}\n'
f'Click through URL: {video_click_through_url}\n')
for resolution in top_news_video['content']['thumbnail']['resolutions']:
thumbnail_size = resolution['tag']
thumbnail_link = resolution['url']
print(f'{thumbnail_size} {thumbnail_link}')
def yahoo_get_multiuse_news_results():
matched_string_json_multiuse = matched_string_json['context']['dispatcher']['stores']['ThreeAmigosStore']['data']['multiuse']['stream']
for multiuse_index, multiuse_news in enumerate(matched_string_json_multiuse):
multiuse_title = multiuse_news['content']['title']
multiuse_content_type = multiuse_news['content']['contentType']
multiuse_summary = multiuse_news['content']['summary']
multiuse_provider_name = multiuse_news['content']['provider']['displayName']
multiuse_provider_url = multiuse_news['content']['provider']['url']
multiuse_canonical_url = multiuse_news['content']['canonicalUrl']['url']
multiuse_click_through_url = multiuse_news['content']['clickThroughUrl']['url']
print(f'Multiuse news number: {multiuse_index}\n'
f'Title: {multiuse_title}\n'
f'Content type: {multiuse_content_type}\n'
f'Summary: {multiuse_summary}\n'
f'Provider: {multiuse_provider_name}\n'
f'Provider URL: {multiuse_provider_url}\n'
f'Canonical URL: {multiuse_canonical_url}\n'
f'Click through URL: {multiuse_click_through_url}\n')
for resolution in multiuse_news['content']['thumbnail']['resolutions']:
thumbnail_size = resolution['tag']
thumbnail_link = resolution['url']
print(f'{thumbnail_size} {thumbnail_link}')
def yahoo_get_news_results():
for yahoo_news_index in matched_string_json['context']['dispatcher']['stores']['StreamStore']['streams']['mega.c']['data']['stream_items']:
title = yahoo_news_index['title']
summary = yahoo_news_index['summary']
news_property = yahoo_news_index['property']
source = yahoo_news_index['publisher']
original_publication_url = yahoo_news_index['url']
yahoo_url = f"https://finance.yahoo.com{yahoo_news_index['link']}"
try:
thumbnail_medium = yahoo_news_index['images']['img:440x246']['url']
except:
thumbnail_medium = None
try:
thumbnail_small = yahoo_news_index['images']['img:220x123']['url']
except:
thumbnail_small = None
print(f'Title: {title}\n'
f'Summary: {summary}\n'
f'Property: {news_property}\n'
f'Source: {source}\n'
f'Original URL: {original_publication_url}\n'
f'Yahoo URL: {yahoo_url}\n'
f'Medium thumbnail: {thumbnail_medium}\n'
f'Small thumbnail: {thumbnail_small}\n')
yahoo_finance_urls.py
Note: Stock symbols are changing each day, and that's the reason why they're currently hardcoded to give some sort of "flexibility" to change to whatever stock symbol is needed.
These stock symbols can be intercepted since they are loaded over time, but at the moment I haven't figured out how to make it work.
import requests
def yahoo_finance_right_stock_urls():
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
"(KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
'''
Symbols below will not be exactly the same as on Yahoo Finance Home Page.
If you want to track specific tickets, leave it as it is and it will work,
otherwise "symbols" need to be changed to the one on the Yahoo Finance Home page.
In the further blog posts this might be changed to auto ticket detection.
'''
symbols = ','.join([
"BTC-USD",
"ETH-USD",
"USDT-USD",
"BNB-USD",
"ADA-USD",
"ETSY",
"FSLY",
"GM",
"ROKU",
"UBER",
"AMD",
"HOOD",
"AMC",
"F",
"GM",
"AZZVF",
"HOOD",
"EXPI",
"COUR",
"NVAX",
"ZY",
"CDLX",
"OCFT",
"CAR",
"CGRY",
"HSSIX",
"HSSCX",
"FFBFX",
"PRGTX",
"HSSAX",
"QQQ",
"BTCUSD",
"ETHUSD",
"EURUSD=X",
"JPY=X",
"GBPUSD=X"
"HSSIX",
"HSSCX",
"FFBFX",
"PRGTX",
"HSSAX"
"ES=F",
"YM=F",
"NQ=F",
"RTY=F",
"ZB=F",
"GE220121C00010000",
"GE220121C00012000",
"GE220121C00015000",
"GE220121P00007000",
"GE220121P00010000",
"LLNW210806C00001000",
"OBSV210820C00010000",
"OBSV210820C00012500",
"OBSV210820C00015000"
])
params = {
'formatted': "true",
'crumb': 'FI5oDlMl7HO',
'lang': 'en-US',
'region': 'US',
'symbols': f"{symbols}",
'fields': 'symbol,shortName,longName,regularMarketPrice,regularMarketChange,regularMarketChangePercent',
'corsDomain': 'finance.yahoo.com'
}
yahoo_urls = requests.get('https://query2.finance.yahoo.com/v7/finance/quote', params = params, headers = headers).text
return yahoo_urls
Extracting Right Side Stocks
import json
from yahoo_finance_urls import yahoo_finance_right_stock_urls
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
"(KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
def yahoo_get_right_side_stocks():
for right_side_stock_result in json.loads(yahoo_finance_right_stock_urls())['quoteResponse']['result']:
stock_symbol = right_side_stock_result['symbol']
short_name = right_side_stock_result['shortName']
region = right_side_stock_result['region']
regular_market_time = right_side_stock_result['regularMarketTime']['fmt']
exchange_time_zone_name = right_side_stock_result['exchangeTimezoneName']
market_state = right_side_stock_result['marketState']
quote_type = right_side_stock_result['quoteType']
try:
quote_source_name = right_side_stock_result['quoteSourceName']
except:
quote_source_name = None
market = right_side_stock_result['market']
regular_market_price = right_side_stock_result['regularMarketPrice']['fmt']
regular_market_change = right_side_stock_result['regularMarketChange']['fmt']
regular_market_change_percent = right_side_stock_result['regularMarketChangePercent']['fmt']
print(f'Quote type: {quote_type}\n'
f'Quote source name: {quote_source_name}\n'
f'Symbol: {stock_symbol}\n'
f'Short name: {short_name}\n'
f'Region: {region}\n'
f'Regular market time: {regular_market_time}\n'
f'Exchange time zone: {exchange_time_zone_name}\n'
f'Market: {market}\n'
f'Market state: {market_state}\n'
f'Market price: {regular_market_price}\n'
f'Price change: {regular_market_change}\n'
f'Price % change: {regular_market_change_percent}\n')
