 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

Dan Koe is one of those creators who always seems to say the right thing at the right time. His videos consistently resonate around productivity, purpose, self-education, and building a meaningful life.
At some point, I started wondering: Is there a repeatable pattern behind his content? Or is it mostly intuition?
More importantly, can a creator's content strategy actually be broken down into something systematic and reproducible?
So I ran a small experiment.
Repository: https://github.com/serpapi/creator-lens
Using SerpApi, I collected metadata, video details, and transcripts from Dan Koe’s YouTube channel(top 100 videos). Then I used DeepSeek to analyze the patterns behind the content.
CreatorLens Demo
Instead of simply watching the videos, I tried to reverse-engineer his strategy across four dimensions: content themes, title patterns, publishing cadence, and recurring core beliefs.
What I found was far more structured, and far more revealing than I expected.
The Engineering Approach
To test this idea, I built a small internal tool called CreatorLens. The workflow was intentionally simple:
1. Use SerpApi to collect YouTube data
2. Normalize the data
3. Send the structured payload to DeepSeek
4. Generate strategy insights through AI analysis
5. Visualize the result in a dashboard
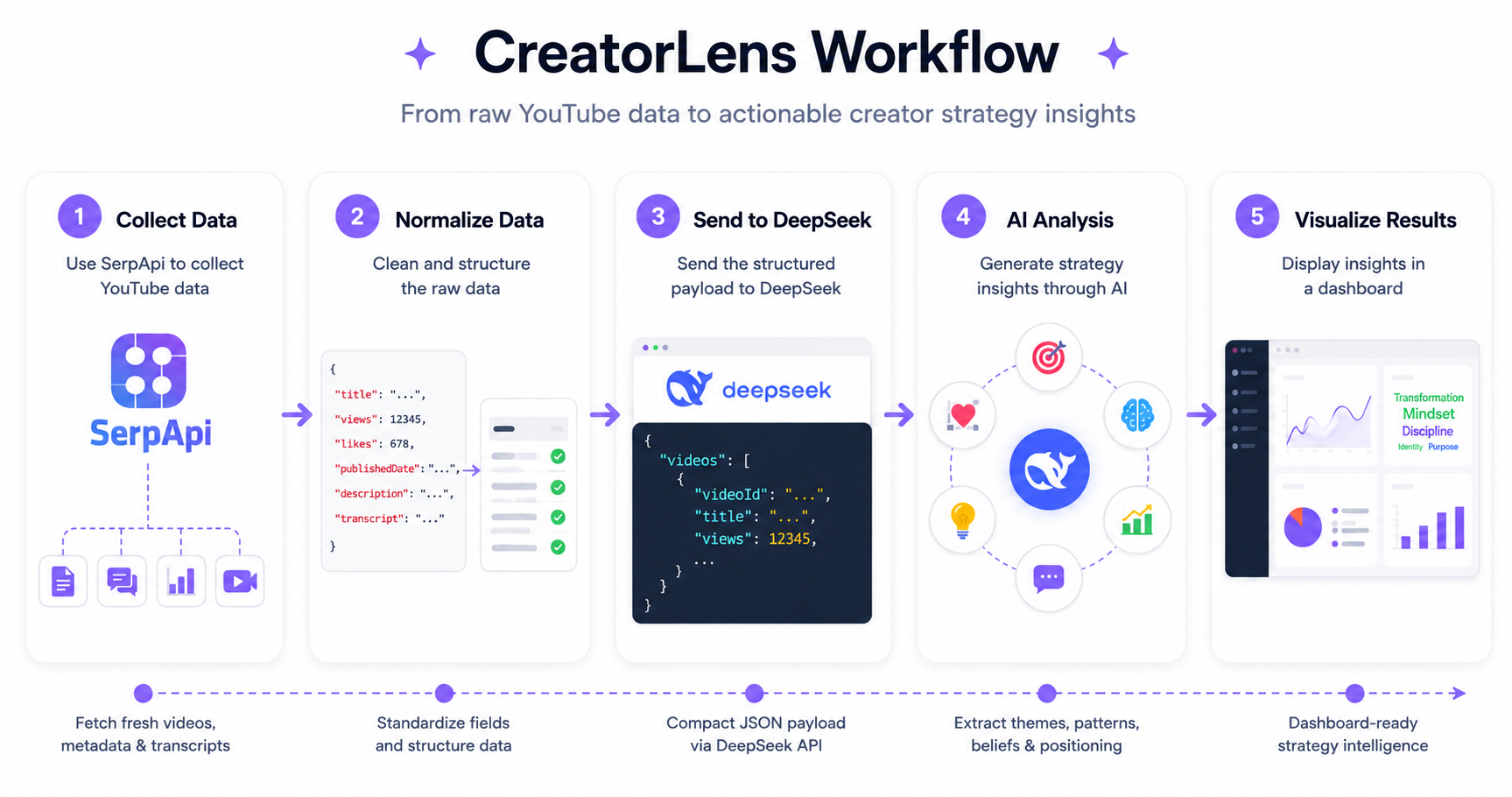
I didn’t use a database for this experiment. Instead, I wanted to see how far I could get with a lightweight, stateless pipeline built around APIs and structured prompts.
The stack looked like this:
User Input
↓
SerpApi YouTube Search API
↓
SerpApi YouTube Video API
↓
SerpApi YouTube Transcript API
↓
DeepSeek Analysis
↓
CreatorLens DashboardAt a high level, SerpApi handled the data layer — searching videos, fetching metadata, and retrieving transcripts. And DeepSeek handled the reasoning layer — identifying recurring themes, extracting title patterns, clustering audience pain points, summarizing core beliefs, and generating strategy frameworks.
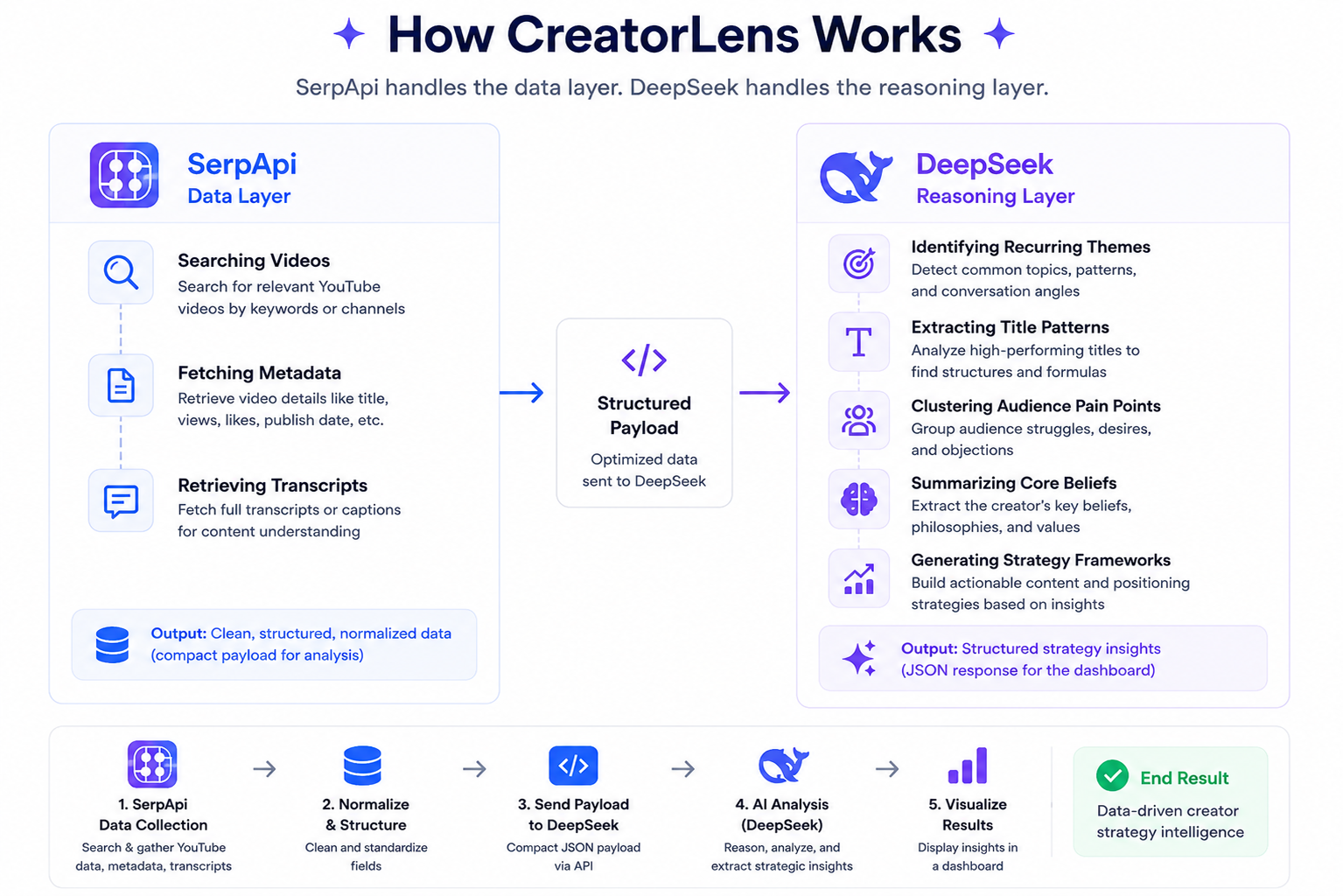
The interesting part wasn’t just collecting the data. It was turning unstructured YouTube content into something analyzable.
Collecting YouTube Data with SerpApi
The first challenge for me was turning a YouTube channel into structured, analyzable data.
Instead of manually opening videos one by one, I used SerpApi’s YouTube APIs to build a lightweight data pipeline. Just like what we mentioned before, the workflow looked like this:
YouTube Search API
→ fetch videos
YouTube Video API
→ enrich metadata
YouTube Transcript API
→ retrieve spoken content
DeepSeek
→ analyze creator strategyAs I wanted to keep the implementation itself simple and stateless, I built a single API route in Next.js that orchestrated the entire flow:
Search videos
→ fetch metadata
→ fetch transcripts
→ normalize data
→ send compact payload to DeepSeekTo keep the implementation clean, I wrapped the SerpApi JavaScript SDK into a small reusable helper:
import { getJson } from "serpapi";
function serpapi(params: Record<string, string>) {
return getJson({ ...params, api_key: API_KEY });
}From there, I split the data collection logic into three focused functions:
searchYouTubeVideos()
fetchVideoDetails()
fetchTranscript()Each function handled a different layer of the YouTube dataset.
Searching Videos
The first function, searchYouTubeVideos(), uses SerpApi’s YouTube Search API to retrieve videos from a creator.
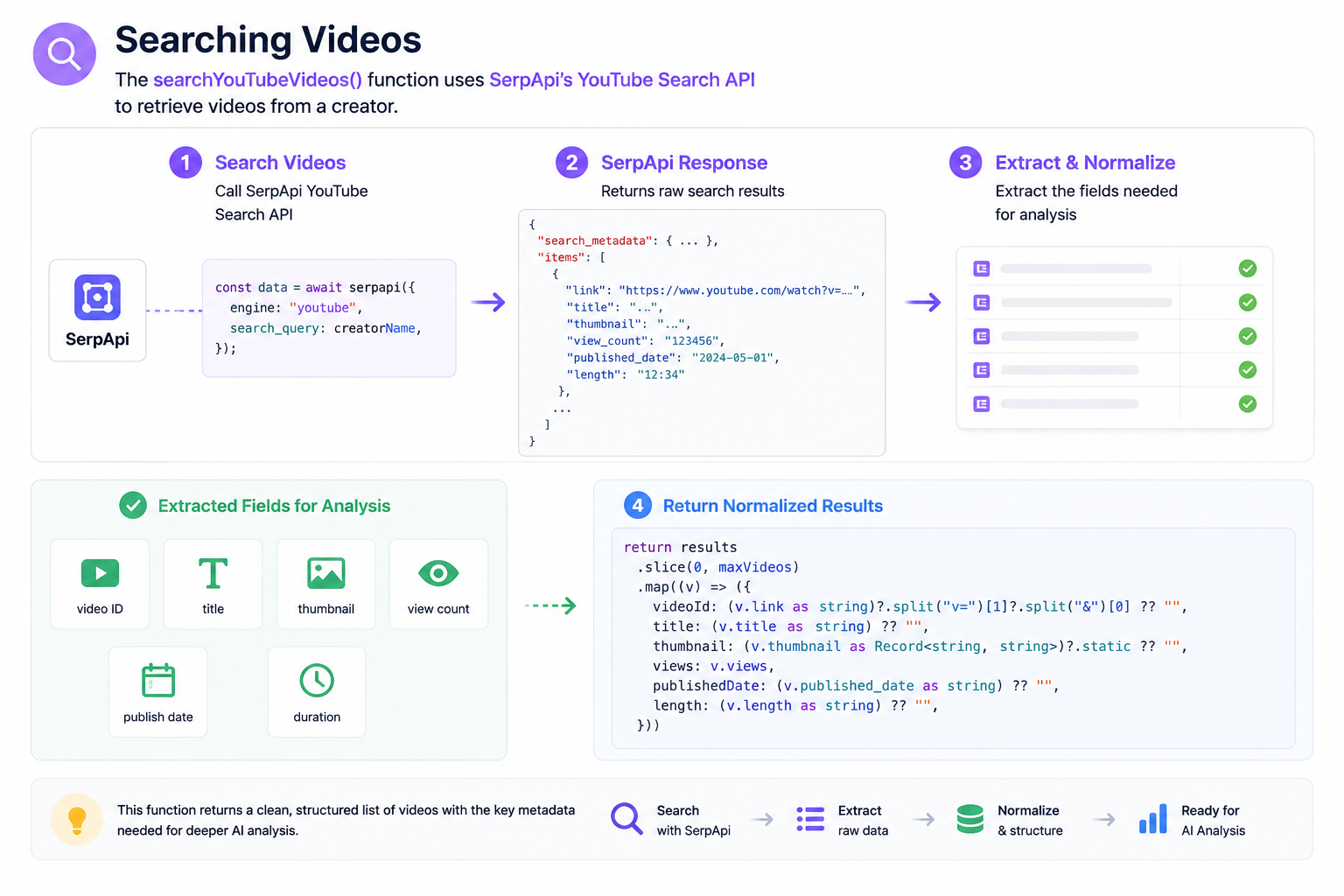
searchYoutubeVideos worksconst data = await serpapi({
engine: "youtube",
search_query: creatorName,
});From the response, I extracted the fields needed for analysis:
- video ID
- title
- thumbnail
- view count
- publish date
- duration
return results
.slice(0, maxVideos)
.map((v) => ({
videoId: (v.link as string)?.split("v=")[1]?.split("&")[0] ?? "",
title: (v.title as string) ?? "",
thumbnail: (v.thumbnail as Record<string, string>)?.static ?? "",
views: v.views,
publishedDate: (v.published_date as string) ?? "",
length: (v.length as string) ?? "",
}))I also added a small parseViews() helper to normalize values like:
"1.2M views"
"842K views"into actual numeric values.
Fetching Video Details
But the fields for each video is not enough for me to analyze, so I added the second function, fetchVideoDetails(). Through SerpApi’s YouTube Video API, it gives me additional metadata.
const data = await serpapi({
engine: "youtube_video",
v: videoId,
});This gives more detailed information like:
- description
- likes
- more accurate view counts
return {
description: (vr.description as string) ?? "",
views: parseViews(vr.views),
likes: parseViews(vr.likes),
};I also intentionally wrapped the function in try/catch so the pipeline can fail gracefully if a single request breaks.
Fetching Transcripts
The most important part of the pipeline was transcript retrieval.
Using SerpApi’s YouTube Transcript API:
const data = await serpapi({
engine: "youtube_video_transcript",
v: videoId,
});I extracted transcript snippets and joined them into plain text:
return snippets
.map((s) => s.text)
.join(" ");This is where the project shifted from simple analytics into actual strategy analysis.
Titles and metrics tell you what performed.
Transcripts reveal:
- recurring language and persuasion patterns
- mental models and emotional framing
- audience positioning
Composing Three Fetch Functions Into One Orchestration Layer
Finally, I combined all three functions into a single orchestration layer.
The goal of this function is simple: given a creator name, return a normalized list of videos with everything DeepSeek needs for analysis.
export async function fetchVideosWithDetails(
creatorName: string,
maxVideos = 10
): Promise<VideoData[]> {Internally, the pipeline does three things:
Creator name
→ search relevant YouTube videos
→ fetch video metadata
→ fetch video transcripts
→ return normalized VideoData[]For each video, metadata and transcript are fetched in parallel:
const [details, transcript] = await Promise.all([
fetchVideoDetails(v.videoId),
fetchTranscript(v.videoId),
]);This avoids unnecessary sequential API calls. The transcript does not depend on the metadata response, so both requests can run at the same time.
The final output is a structured VideoData[] array, where each item contains the video title, URL, metadata, and transcript. This gives DeepSeek a clean input format instead of forcing it to reason over scattered API responses.
At a high level, SerpApi handled the full data layer:
Creator Name
→ YouTube Search Results
→ Video Metadata
→ Transcripts
→ Structured DatasetOnce this dataset was ready, I could move from data collection to the analysis layer.
Using DeepSeek to Analyze Creator Strategy
Once the YouTube data was normalized into a structured dataset, the next challenge was turning raw video content into creator-level strategy insights.
My first attempt was the obvious one: truncate each transcript and send it directly to DeepSeek.
At first, this actually worked surprisingly well. But after testing longer videos, I started noticing an important limitation: important arguments, storytelling structure, and recurring ideas often appear later in the video. By aggressively slicing the transcript, the analysis became biased toward only the beginning of the content.
For example: a key insight might appear halfway through; the conclusion of an argument could be missing entirely; emotional framing develops gradually across the whole transcript.
So I tried the opposite approach — sending multiple full transcripts into a single DeepSeek prompt:
const payload = videos.map((v) => ({
title: v.title,
views: v.views,
description: v.description
transcript: v.transcript
}));That ran into different problems. Multiple long transcripts significantly increased latency and context usage, while introducing noisy spoken content — repeated phrases, sponsor segments, filler words. As the number of videos grew, reasoning quality degraded because too much irrelevant context competed for attention.
Either way, I was hitting the same wall: a context compression problem. Truncating loses signal; combining adds noise.

Switching to a Two-Step Analysis Pipeline
So I redesigned the workflow into a hierarchical pipeline: instead of compressing information before understanding it, DeepSeek would understand each video independently first, then perform pattern analysis on those summaries.
Step 1
Full transcript
→ DeepSeek
→ compact VideoSummary
Step 2
VideoSummary[]
→ DeepSeek
→ creator strategy analysisThis architecture improved analysis quality significantly because semantic compression happened after DeepSeek fully understood each individual video.
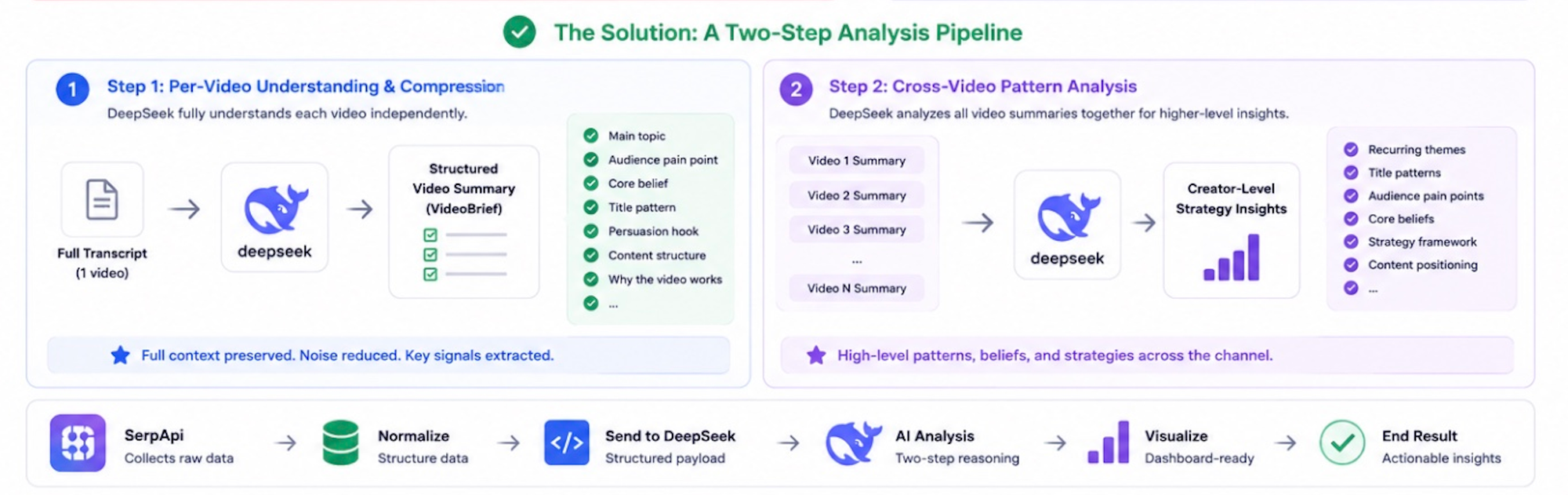
The first stage extracted structured insights from each transcript independently.
The second stage analyzed recurring strategic patterns across the entire channel using semantically dense summaries rather than raw text.
The pipeline also became easier to scale because per-video summarization could run in parallel.
Designing Structured AI Contracts
One important realization during development was that prompt engineering was less about “asking better questions” and more about designing reliable AI interfaces.
Instead of treating DeepSeek like a chatbot, I treated it more like a structured analysis engine with strict input and output contracts.
The prompts effectively became schema-driven interfaces between different stages of the pipeline.
Step 1 Prompt: Per-Video Semantic Compression
The first prompt focused on compressing a full YouTube video into a structured semantic representation.
export function buildVideoSummaryPrompt(
video: VideoData
): string {
const context = JSON.stringify({
videoId: video.videoId,
title: video.title,
views: video.views,
publishedDate: video.publishedDate,
description: video.description,
transcript: video.transcript,
});
return `
You are a content analyst.
Analyze the YouTube video below and return a compact JSON summary.
Video data:
${context}
Return ONLY valid JSON with exactly these fields:
{
"videoId": "",
"title": "",
"views": 0,
"publishedDate": "",
"mainTopic": "",
"keyPoints": [],
"titlePattern": "",
"hook": "",
"whyItWorks": "",
"audienceProblems": [],
"beliefs": []
}
`;
}Instead of generating conversational summaries, the model was forced to extract structured strategic signals such as:
- hooks
- title patterns
- audience pain points
- creator beliefs
- positioning strategies
- narrative structures
This transformed long transcripts into compact VideoSummary objects optimized for downstream reasoning.
Step 2 Prompt: Cross-Video Strategy Analysis
Once all videos were summarized, the second prompt analyzed creator-level patterns across the channel.
At this stage, DeepSeek no longer needed raw transcripts. Instead, it reasoned over structured semantic abstractions.
export function buildAnalysisPrompt(
summaries: VideoSummary[]
): string {
return `
You are a content strategy analyst.
Based on the per-video summaries below,
identify the creator's overall content strategy.
Video summaries:
${JSON.stringify(summaries, null, 2)}
Return ONLY valid JSON with exactly these fields:
{
"mainNiche": "",
"topContentThemes": [],
"titlePatterns": [],
"coreBeliefs": [],
"audiencePainPoints": [],
"publishingCadence": "",
"videoAnalysis": [],
"strategyReport": ""
}
`;
}This created a hierarchy of reasoning:
raw transcript
→ semantic summary
→ creator-level strategy analysisThe second-stage analysis became surprisingly effective at identifying patterns I wouldn't have caught by watching:
- Recurring hooks — emotional triggers reused across videos
- Identity-based positioning — how he frames the audience to themselves
- Reusable title formulas — structural templates behind high-performers
- Recurring beliefs — philosophical anchors that show up again and again
- Audience anxieties — the underlying fears the content addresses
- Publishing rhythm — cadence patterns across multi-year timeframes
At that point, the project stopped feeling like "YouTube analytics." It started feeling more like reverse-engineering a creator's communication system.
Parallelizing the Pipeline
Since each video could be summarized independently, the first stage was parallelized using Promise.all():
const summaries = await Promise.all(
videos.map((v) => summarizeVideo(v))
);This significantly improved throughput while avoiding unnecessary sequential API calls.
Even when analyzing many videos, the pipeline remained reasonably fast because transcript summarization happened concurrently.
Calling the DeepSeek API
For the implementation, I used DeepSeek’s chat completion API with JSON response formatting enabled.
const res = await fetch(DEEPSEEK_API_URL, {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${API_KEY}`,
},
body: JSON.stringify({
model: "deepseek-chat",
messages: [
{ role: "system", content: SYSTEM_MESSAGE },
{ role: "user", content: prompt },
],
response_format: {
type: "json_object",
},
}),
});I also added a strict system instruction:
const SYSTEM_MESSAGE =
"You are a JSON-only assistant. Always respond with valid JSON only.";Enabling:
response_format: {
type: "json_object",
}significantly reduced malformed outputs.
Parsing and Normalizing the AI Response
Even with structured prompting, LLM responses can still fail occasionally.
So instead of assuming the response would always be valid JSON, I added defensive parsing logic.
DeepSeek sometimes returned markdown wrappers such as:
```json
...
```So I stripped those wrappers before parsing:
function stripMarkdown(content: string): string {
const match = content.match(
/```(?:json)?\s*([\s\S]*?)```/
);
return match
? match[1].trim()
: content.trim();
}Then I safely parsed the response:
try {
return JSON.parse(cleaned);
} catch {
return {};
}Finally, I normalized all fields with fallback values:
mainNiche: parsed.mainNiche ?? "Unknown",
topContentThemes: parsed.topContentThemes ?? [],
titlePatterns: parsed.titlePatterns ?? [],This made the overall pipeline much more resilient.
Even if the model returned partial or malformed output, the dashboard could still render safely instead of crashing entirely.
What the Pipeline Found
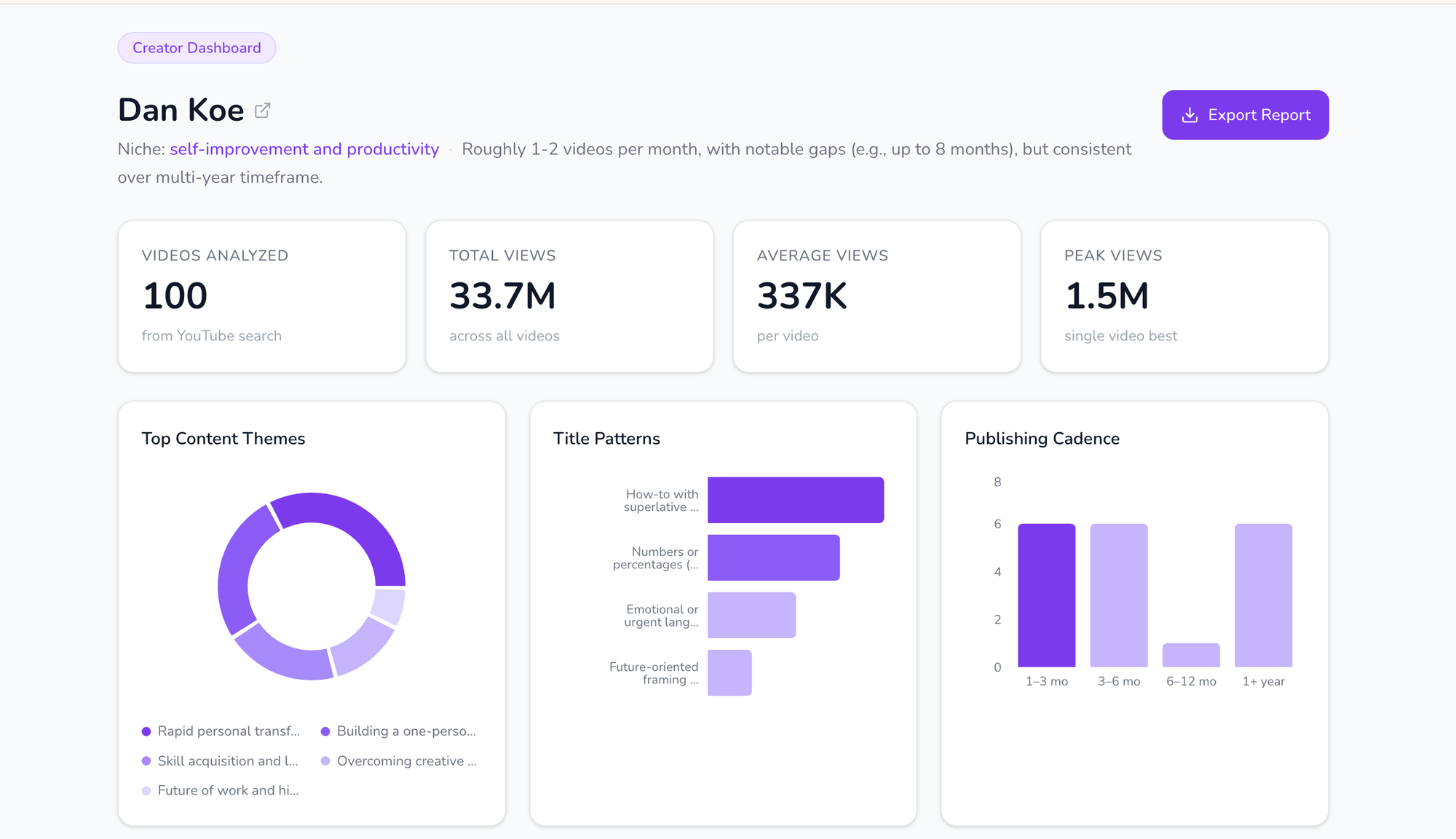
Running the full pipeline on Dan Koe's top 100 videos surfaced a strategy that was more systematic than I expected. Across 35.2M total views and 352K average views per video, four patterns kept reappearing.
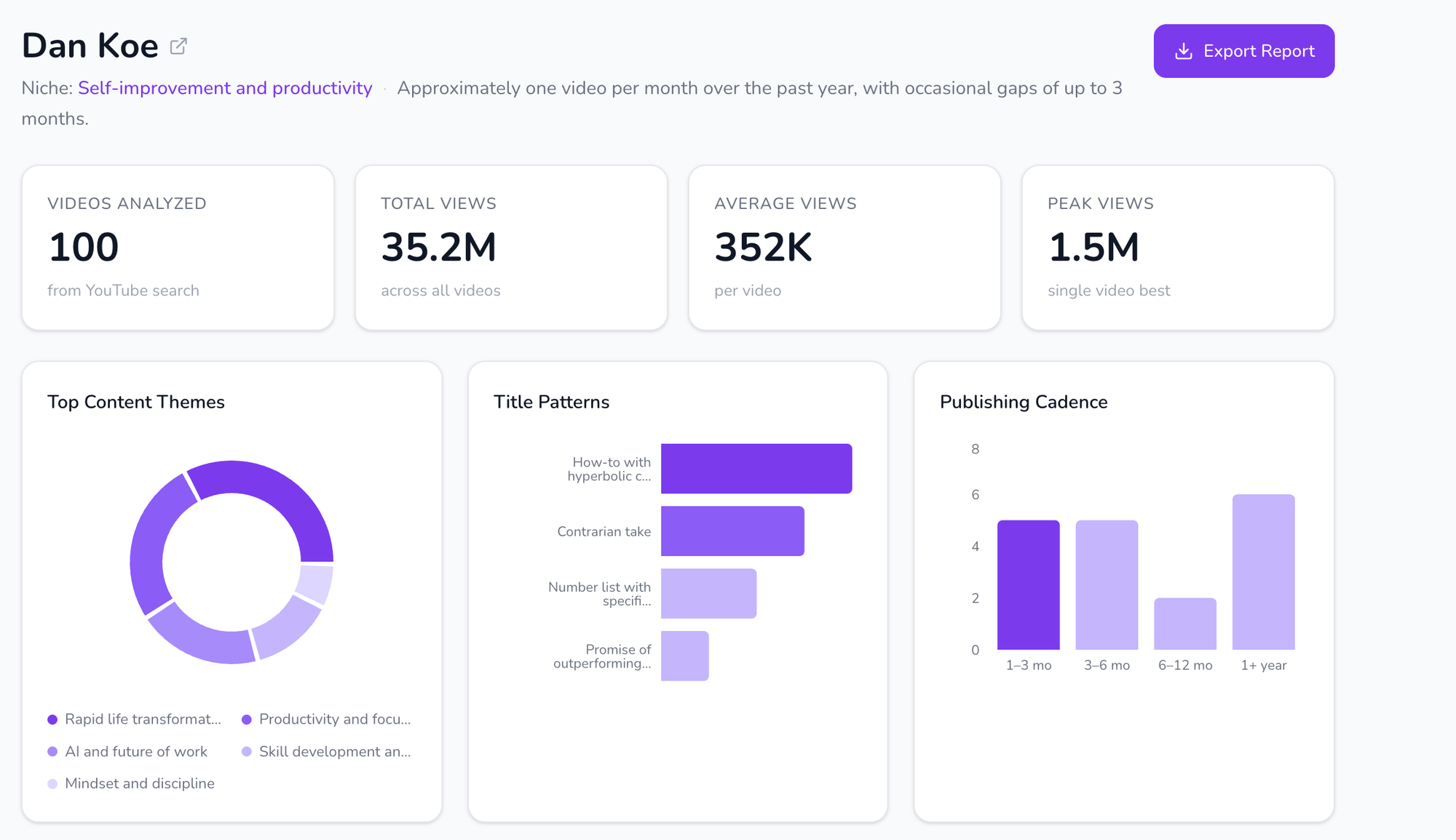
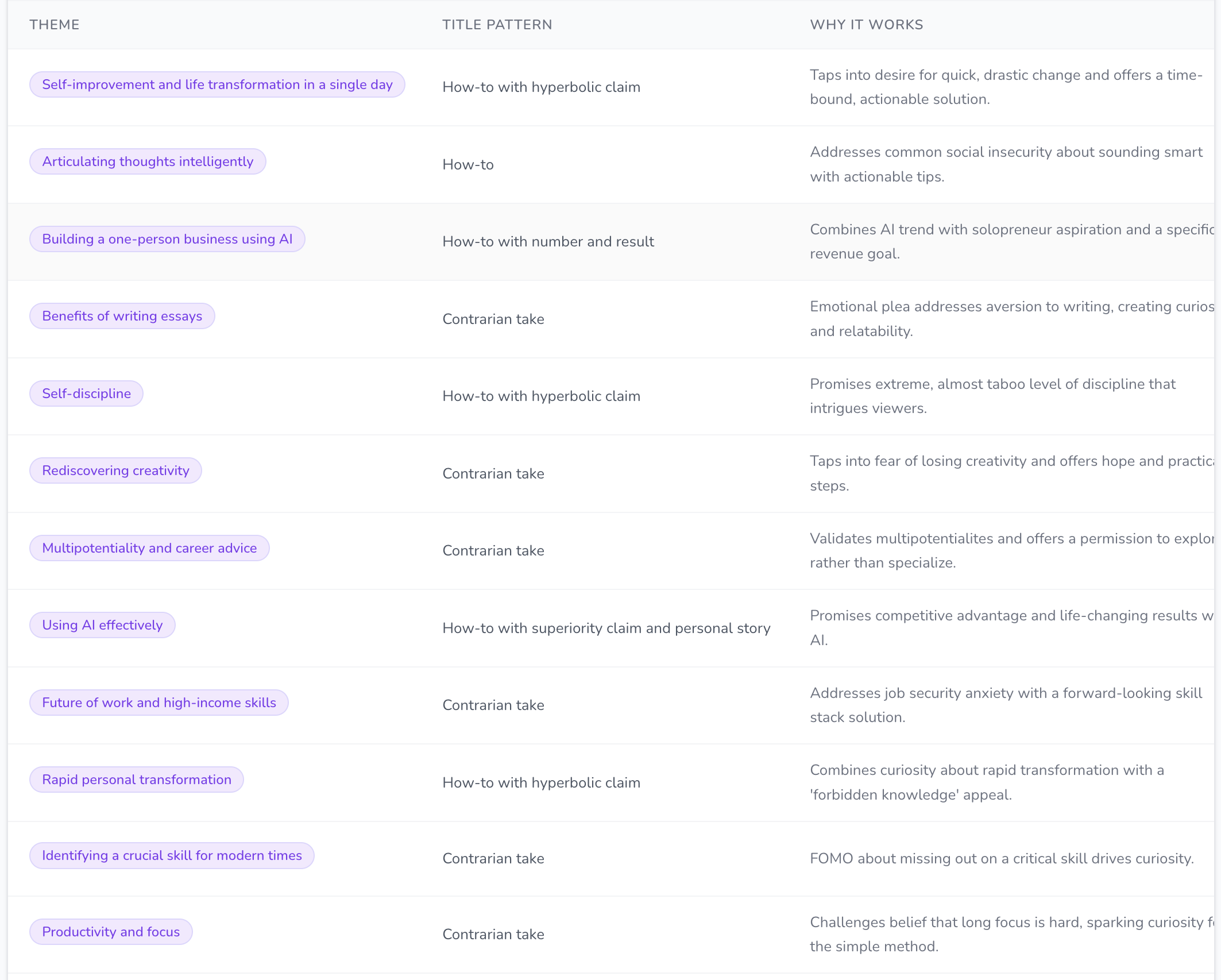
His real topic isn't AI, or productivity, or skills. It's transformation. The pipeline grouped his 100 videos into five clusters: rapid life transformation, productivity and focus, AI and the future of work, skill development, and mindset and discipline. On paper, five different subjects. In practice, five different costumes for the same promise: you can become someone else, and fast. A title like "How To Use AI Better Than 99% Of People" looks like an AI video. But strip the AI away and what's actually being sold is become elite. The subject rotates; the topic doesn't.
His titles run on two engines. Either he's promising you something impossibly fast — "How to fix your entire life in 1 day," "How To Become So Self-Disciplined It Feels Illegal" — or he's telling you you're doing it wrong: "I'm begging you to start writing essays," "You are learning the wrong skills." Desire on one side, fear on the other. And once you notice it, you start seeing it in every title. The mechanic underneath both is the same — the title plants a question your brain can't answer without watching. Fix my life in a day? How? Wrong skills? Which ones? That question is the hook. The click is just the brain trying to close the loop.
Publishing cadence is consistent but not frequent. Roughly one video per month, with occasional gaps of up to three months. He's not playing the volume game. Each video is a deliberate piece of content carrying high production value, which fits the audience he's building — viewers who want depth, not constant noise.
The core beliefs are remarkably stable across years. Four ideas appear again and again, regardless of topic: radical change is possible through focused action; personal agency and discipline are the keys to success; AI and modern tools can dramatically accelerate growth; continuous learning and adaptability are essential. These aren't claims Dan Koe argues for — they're claims he argues from. Every video assumes them and builds on them. That's what makes the content feel coherent across hundreds of videos: it's not a feed of topics, it's a worldview being expressed across many surfaces.
The most interesting finding wasn't any single one of these — it was the combination.
The framework underneath the channel is something like: identify a specific audience pain point (feeling stuck, lacking discipline, fearing obsolescence) → offer a contrarian or high-impact solution → package it with a hyperbolic or pattern-interrupt title → deliver actionable advice that reinforces the four core beliefs.
That's not intuition. That's a repeatable system. And it's exactly the kind of thing that's nearly impossible to see by watching the videos one at a time — but obvious once you compress 100 of them into structured summaries and analyze them together.
Final Thoughts
At first, I thought I was simply building a YouTube analytics tool.
But once transcripts, metadata, and structured AI analysis started working together, the project became something much more interesting: a creator strategy reverse-engineering engine.
One of the biggest insights from this experiment was that LLMs become significantly more powerful when they are treated as structured reasoning systems rather than conversational chatbots.
The largest improvement did not come from changing models.
It came from redesigning the architecture around reasoning workflows:
- full-context transcript understanding
- semantic compression
- hierarchical reasoning
- structured AI contracts
- resilient parsing
- parallel orchestration
For this experiment, I also intentionally kept the backend completely stateless.
There was:
- no database
- no queue system
- no background jobs
Every request fetched fresh YouTube data directly from SerpApi, normalized it in memory, performed multi-stage DeepSeek analysis, and returned a dashboard-ready response.That kept the architecture surprisingly simple while still producing rich creator-level insights.
More importantly, it reinforced something I’ve been thinking about recently:
Modern AI applications increasingly behave less like traditional CRUD software and more like orchestration pipelines built around reasoning models. And honestly, that was probably the most exciting part of the entire project.
If you want to build similar AI-powered analysis tools on top of real-time search and creator data, SerpApi provides a very clean developer experience for working with YouTube search, video metadata, and transcripts.
The demo app in this article uses the following APIs from SerpApi:
Give them a try in your own AI-native applications and analytical workflows.
