 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

Back in August 2021 Google started tweaking a few meta tags as long as search intent was met. Although this might occasionally hit the nail on the head, most of the time that contributes to warding off one's webpage overall visibility.
Since the rewriting event, several powerful tools have been released in a bid to identify potential tweaks straight away. Even though you hardly would bite the hand that feeds you, the bespoke SEO featuring tools often conceal unfathomable fees which may in turn discourage users from accessing the features.
In this post I am going to talk you through a Python framework powered by a free SerpApi aimed to deliver a clear representation about meta data automated amendments Google might run on your website.
As you will notice, the script is designed to compare a fistful of page titles and meta descriptions to what is shown in the SERPs. This is achievable only through a Screaming Frog crawl and, of course, SerpApi.
Hence in case you needed to wriggle out the most expensive SEO tools on the market you would find this framework at your fingertips.
Requirements & Assumptions
In order to detect SERP feature tweaks, the Python script needs to be empowered by a few resources.
- Access to Google Colab or Jupiter Notebook. Due to the overall readiness of the former, I suggest using Colab.
- A SerpApi key which you can get after subscribing to a SerpApi plan of your best convenience
- Either a Screaming Frog internal HTML crawl or a CSV file listing only the URLs you would like to inspect.
Beware SerpApi grants 100 free searches per month, therefore this framework might not be recommended if you are intended to work with large datasets.
Detect Google SERP Title and Snippet Rewriting
For the purpose of this task, we first need to install the SerpApi Python library called Google Search Results and Polyfuzz.
Do not forget to append an exclamation mark before the pip if you are using Google Colab
!pip install google-search-results!
!pip install polyfuzzPolyfuzz is a pivotal library for this project as it is going to be employed to calculate the comparison similarity scores of each URL.
Once the libraries are installed, we need to import them onto our environment including Pandas. This step is equally crucial as it enables us to create an empty data frame to ultimately fill up with the outcome of the title tags rewriting analysis.
import pandas as pd
from serpapi import GoogleSearch
from polyfuzz import PolyFuzzImport the crawl CSV into a Pandas data frame
Import your list of URLs with either a CSV file or an internal_html Screaming Frog crawl, and make sure you only use a single column named "URL".
Once you have uploaded the list, we are going to filter out rows that are not marked as "indexable". Other than that, to make sure to run the comparisons between URLs we need to replace the NaN (no value) values with a string.
You will notice a comment hashmark at the end of the read_csv function but you can remove it or change it to the number of URLs you want to process.
Given that many meta descriptions are more characters than what is displayed in the SERP, what you want to aim for is capping the number of characters to 150 as it will deliver a better clue of the total rewriting.
df = pd.read_csv("YOUR_CSV_FILE")[["Address","Indexability","Title 1","Meta Description 1","H1-1"]] #[:5]
df = df[df["Indexability"] == "Indexable"]
df = df.fillna('None')
df.drop(['Indexability'], axis=1, inplace=True)
df["Meta Description 1"] = df["Meta Description 1"].apply(lambda x: x[:150]) I suggest testing the script with a small subset of URLs to prevent your entire API credits from blowing up in one go.
Create Empty Lists to Store Data
At this point we create 4 different empty data frames. The first two of them will contain the factual SERP title tag and meta description, whereas the others will pinpoint the feasible differences prompted by the search algorithms snippet rewriting.
serp_title_list = []
serp_desc_list = []
serp_title_list_diff = []
serp_desc_list_diff = []Send each URL to the SerpAPI
Time to use SerpApi.
We need to loop through the crawled list of URLs to send each of them to the API, which will make a query the title and meta description snippet.
Make sure you set up the language ("hl") and the location ("gl") required for the desired output. Then paste your SerpApi key.
for index, row in df.iterrows():
params = {
"q": row["Address"],
"hl": "en",
"gl": "gb",
"api_key": "YOUR_API_KEY"
}
search = GoogleSearch(params)
results = search.get_dict()
serp_title = results["organic_results"][0]["title"]
serp_desc = results["organic_results"][0]["snippet"][:150]
serp_title_list.append(serp_title)
serp_desc_list.append(serp_desc)Next, we are going to add the earned titles and meta snippets to our new data frame.
df["SERP Title"] = serp_title_list
df["SERP Meta"] = serp_desc_listCalculate a Similarity Score with Polyfuzz
Here is where the magic happens.
Now that we have our data frame ready to be filled up with the findings, we need to finally scrape and parse the data.
Polyfuzz is going to help us by calculating the accuracy level in which both the original title tags and meta descriptions match with their factual SERP counterpart.
Please note that the scores range from 0-1.
The closer to 1, the better the match.
model = PolyFuzz("EditDistance")
model.match(serp_title_list, df["Title 1"].tolist())
df2 = model.get_matches()
model.match(serp_desc_list, df["Meta Description 1"].tolist())
df3 = model.get_matches()
model.match(serp_title_list, df["H1-1"].tolist())
df4 = model.get_matches()Next, we need to import the retrieved similarity scores into a list. Needless to say, we are going to leverage the Pandas library.
df["SERP Title Accuracy Level"] = df2["Similarity"].tolist()
df["SERP Meta Accuracy Level"] = df3["Similarity"].tolist()
df["SERP H1 Accuracy Level"] = df4["Similarity"].tolist()If we were to prompt the output at this stage, we would receive a ton of messy data. Due to that, we need to sort and format data.
To put that into context, we are going to sort by descending order the SERP title difference that has been detected. Ultimately we are going to round the similarity scores for Title, Meta and H1 accuracy.
df = df.sort_values(by='SERP Title Accuracy Level', ascending=True)
df["SERP Title Accuracy Level"] = df["SERP Title Accuracy Level"].round(3)
df["SERP Meta Accuracy Level"] = df["SERP Meta Accuracy Level"].round(3)
df["SERP H1 Accuracy Level"] = df["SERP H1 Accuracy Level"].round(3)Finally we can prompt the machine to return the output of the workload.
df.to_csv("title-snippet-rewrites.csv")
#dfBy default, you will be able to download the CSV file that we created in the process. However, if you wished the code retrieves an output for visualization only, you can only type df by removing the comment hashmark.
Should you opt to download the CSV file, you will end up with something similar to the following screen grab.
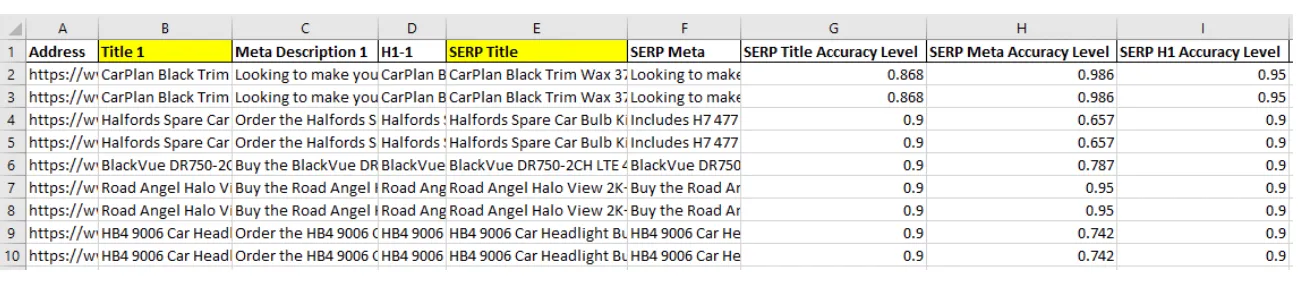
Conclusion
Taking advantage of data science often results as extremely beneficial to SEOs. Building your own tools concurs to speed up boring manual processes and help you save money that you could invest on your personal development.
Although this comes with a few downsides concerning the amount of data you can process, Python frameworks such as the Title Tag Rewriting with SerpApi will come as the best of both worlds anytime you want to make sure Google does not rewrite your meta tags.
Create a free SerpApi account today, and find out how easy it is to power your SEO workflows