 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

Every few months, the SEO world discovers a new file you're supposed to put at the root of your website. It's enough of a pattern that the IndieWeb wiki tracks them, and most of them don't matter.
So when Jeremy Howard proposed llms.txt in September 2024, a healthy dose of skepticism was warranted. The studies came in, and they weren't kind: roughly 10% adoption in 2026 (and that's heavily inflated by automatically pre-installed Wordpress and Drupal plugins), zero measurable impact on AI citations, and Google explicitly saying they don't use it.
We just added it anyway. Not because we think the studies are wrong, but because we think they're measuring the wrong thing.
What is llms.txt?
llms.txt is a simple idea from Howard, co-founder of fast.ai: put a Markdown file at yoursite.com/llms.txt that gives LLMs a curated entry point to your site. The problem it solves is real enough: "context windows are too small to handle most websites in their entirety," so you give agents a table of contents instead of making them parse your entire site.
Here's the beginning of ours:
# SerpApi
> SerpApi provides a real-time JSON API for accessing structured
> search engine results from Google, Bing, Baidu, and more.
> Trusted by Nvidia, Shopify, Perplexity, Adobe, Samsung, KPMG,
> Ahrefs, Grubhub, AI21 Labs, United Nations, Thomson Reuters,
> Morgan Stanley, and thousands of other companies.
- Website: https://serpapi.com
- Sign up: https://serpapi.com/users/sign_up
- API: https://serpapi.com/search
- Example: `GET https://serpapi.com/search?q=Coffee&engine=google&api_key=YOUR_API_KEY`
- Supported engines: Google, Apple App Store, Baidu, Bing, Amazon,
DuckDuckGo, eBay, Facebook, Naver, OpenTable, The Home Depot,
Tripadvisor, Walmart, Yahoo!, Yandex, Yelp, YouTube
## Pricing
- [Plans and Pricing](https://serpapi.com/pricing.md): Choose your plan...
## Integrations
- [Language Libraries and Tools](https://serpapi.com/integrations.md):
Official libraries for Ruby, Python, JavaScript, Golang, PHP,
Java, Rust, and .Net, plus MCP support
## API Documentation
- [Google Search API](https://serpapi.com/search-api.md): Scrape Google search results...
- [Google AI Mode API](https://serpapi.com/google-ai-mode-api.md): Scrape Google AI Mode...
- [Amazon Search API](https://serpapi.com/amazon-search-api.md): Scrape Amazon products...
...60+ endpoints
That's an excerpt from our actual llms.txt. It links to 60+ API endpoint docs, integration guides, use cases, and pricing, all in Markdown. As Howard puts it: "Site authors know best, and can provide a list of content that an LLM should use."
The spec explicitly complements existing standards: "While sitemap.xml lists all pages for search engines, llms.txt offers a curated overview for LLMs. It can complement robots.txt by providing context for allowed content." Think of it this way: robots.txt tells crawlers what not to access, while llms.txt tells agents what is available and where to find it. One is a bouncer, the other is a table of contents.
The critics are right (about the wrong thing)
Criticism of llms.txt is well-documented and, within its own frame, largely correct:
- SE Ranking's 300k-domain study found no statistical correlation between having an llms.txt and being cited by AI systems.
- Rankability's scan of the top 100 websites found a zero adoption rate among market leaders.
- ALM Corp's analysis of 10 sites showed no measurable difference in AI citations after adding the file.
- Google has confirmed they do not use llms.txt for crawling, indexing, or AI Overviews.
All of this research asks the same question: "Does llms.txt help you get cited more by AI search engines?" And the answer is clearly no. If you're adding llms.txt as an SEO strategy, a way to show up more in Google's AI Overview or Perplexity or ChatGPT, save yourself the trouble. The data is unambiguous.
But that was never the only use case, and for us it's not even the interesting one.
It's about agents, not search engines
Think about what happens when a developer tells their AI coding agent, "use SerpApi to search Google." The agent needs to figure out what SerpApi is, find the right API endpoint, understand the required parameters, and ideally see a working example. That's a documentation problem, not a search ranking problem.
Without llms.txt, the agent fetches our HTML documentation pages. What comes back is what DerivateX's comprehensive guide describes bluntly:
When an AI tool retrieves a webpage today, it does not read it the way a human does. It sends a request, receives raw HTML, and then has to extract meaning from a document filled with navigation menus, cookie consent banners, JavaScript bundles, advertising scripts, and footer links. For a system working within a fixed context window, all that structural noise competes directly with the content that actually matters.
Our HTML documentation pages are pretty good, if we say so ourselves. They have interactive demos, sample output, syntax-highlighted code blocks, and navigation between related endpoints. All of that is valuable for a developer reading in a browser. But for an LLM working within a context window, it includes a lot of unnecessary noise.
DerivateX cites a 10x token reduction when an agent reads Markdown instead of parsing HTML. They identify the strongest validated use case for llms.txt as developer tooling: helping AI coding assistants "fetch the right pages with less token waste" when they're already pointed at your domain. Their verdict:
llms.txt is infrastructure, not strategy.
That framing resonated with us, so we measured our own pages.
The actual numbers
We compared the raw byte size of our documentation pages served as Markdown (via our .md endpoints) versus their standard HTML versions. Here's a sample:
| Page | Markdown | HTML | Reduction |
|---|---|---|---|
| Google Search API | 19.6 KB | 354.9 KB | 18× |
| Google AI Mode API | 7.7 KB | 358.0 KB | 46× |
| Google AI Overview API | 3.2 KB | 224.1 KB | 70× |
| Integrations | 2.3 KB | 63.3 KB | 28× |
| Pricing | 8.4 KB | 143.8 KB | 17× |
| Google Shopping API | 8.3 KB | 225.5 KB | 27× |
| Amazon Search API | 24.9 KB | 275.6 KB | 11× |
| Google Maps API | 12.9 KB | 240.8 KB | 19× |
The average across all our markdown-enabled pages is 32×. Even our worst case, the Amazon Search API with its extensive result examples, still comes in at 11×. The best case, Google AI Overview API, is 70× smaller in Markdown.
To give you a sense of what that means in practice: a typical LLM tokenizer processes roughly 4 bytes per token for English prose. But HTML markup tokenizes far less efficiently. HTML tags, attribute names, and inline scripts all generate tokens that carry no informational value. An agent reading our Google AI Mode HTML page burns approximately 79,000 tokens on content that isn't relevant, while the Markdown version clocks in at around 1,800 tokens of pure, usable content.
The llms.txt index file itself is under 16 KB. A complete map of 60+ API endpoints, integration guides, use cases, and pricing, in a single file smaller than most hero images.
What this looks like for an agent
Without llms.txt, an agent fetches serpapi.com/search-api and gets 354 KB of HTML: a <head> tag containing a bunch of scripts, Open Graph meta tags and font preloads, a sidebar navigation with roughly 400 links covering every API endpoint and sub-result type, an interactive demo with live playground output, and a footer with status and support links. Somewhere in the middle, the actual API documentation. By the time the agent extracts the parameter table from the DOM, a good chunk of its context window is full, and if the window is tight (and it always is when the agent is juggling multiple tool calls), the response format examples at the bottom of the page may get truncated entirely.
With llms.txt, the same agent fetches 16 KB of clean Markdown. Within the first 20 lines it knows what SerpApi does, has a working API example, and sees a structured index of every endpoint. It picks search-api.md, fetches it, and gets a Markdown document with YAML frontmatter, a parameter table, and a full JSON response example. No 400-link sidebar, no interactive playground, no javascript, just documentation. That's the two orders of magnitude reduction in practice.
This works for all sorts of tasks. A developer building a price comparison tool gets the agent reading the Google Shopping API and Amazon Search API docs and writing correct integration code on the first try, using the right engine parameter and parsing the documented JSON structure. A developer monitoring AI search results gets the agent discovering the Google AI Mode API, probably an endpoint they didn't know existed, and finding subsequent_request_token for multi-turn conversations. A developer asking "how much would 50,000 searches per month cost?" gets the agent reading pricing.md, parsing a structured plan table, and explaining the options.
Try getting that last one from a pricing page built with React components and interactive sliders.
A real life example with OpenCode
Let's try to get the weather in Dublin, Ireland (spoiler: it's what you'd expect) with Claude, via OpenCode. We'll point it at our llms.txt and give it our API key, and ask it to Google for us. But we'll leave how to do that completely to its own discovery. This is a brand new session, without an AGENTS.md file or any knowledege of our codebase.
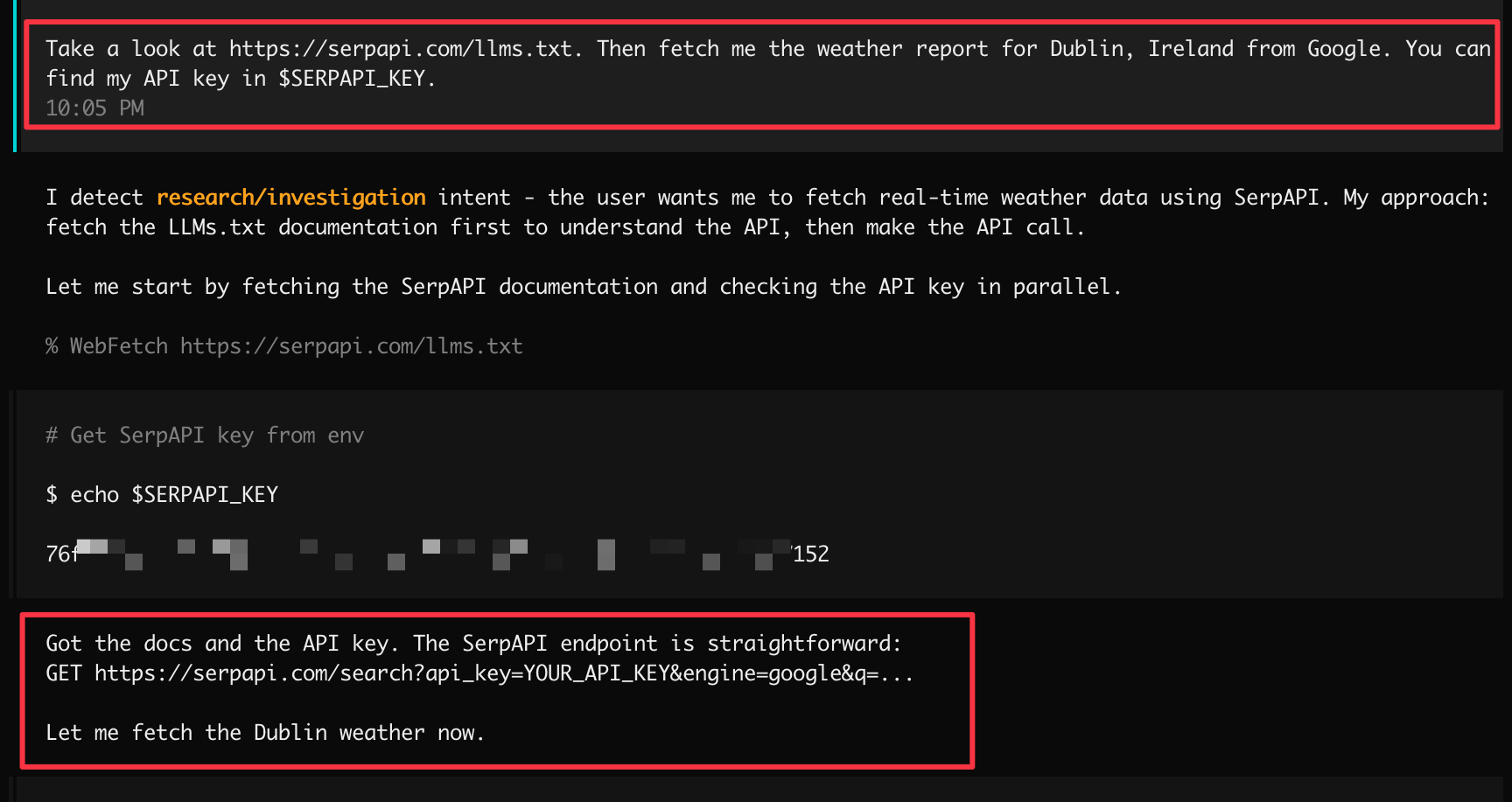
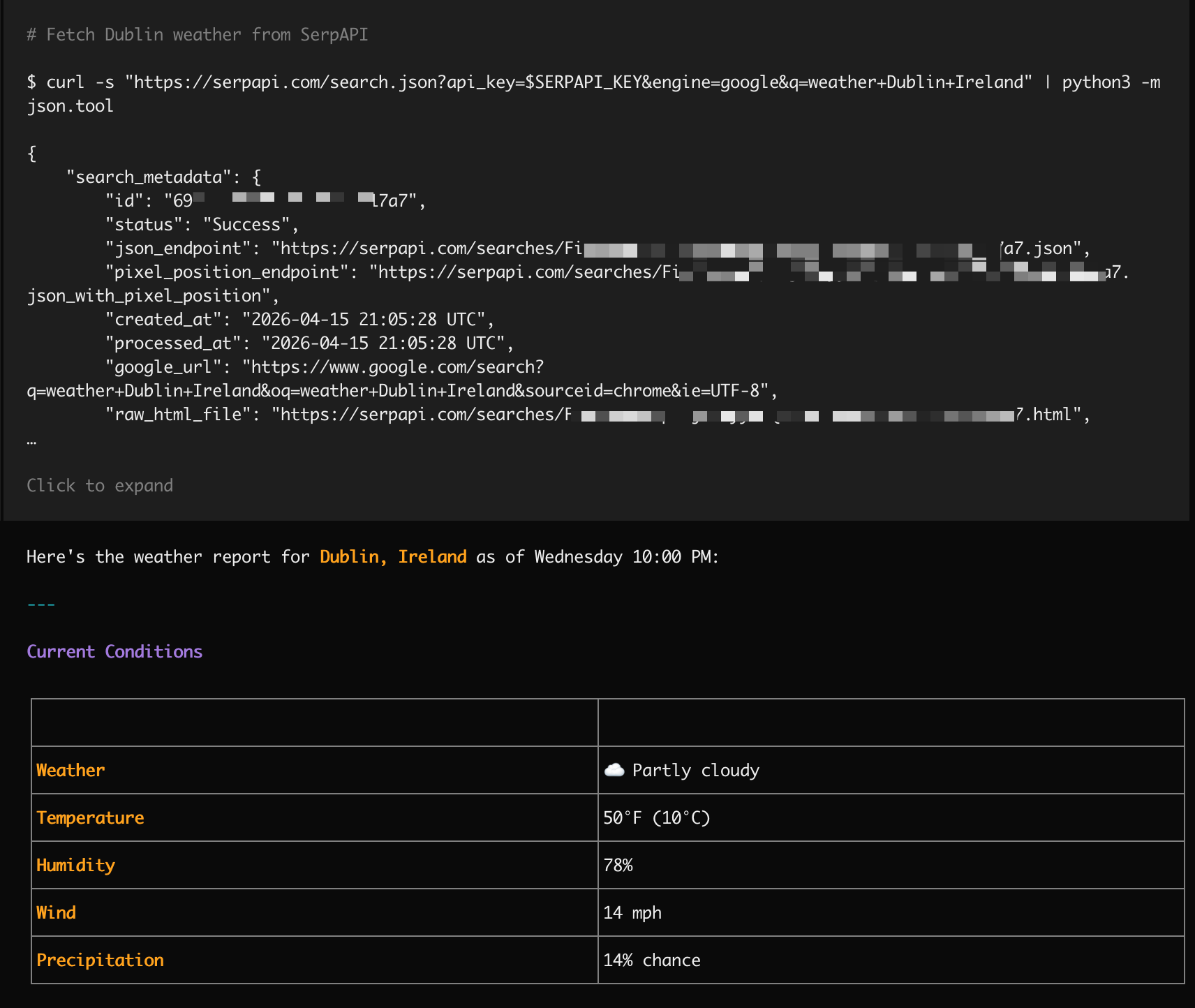
And voila - Claude just goes off and one-shots it:
The MCP connection
Our llms.txt works in tandem with our MCP integration. The workflow is straightforward:
- An agent reads
serpapi.com/llms.txtand understands our API surface. - It discovers we have an MCP server at
mcp.serpapi.com. - It connects and calls our
searchtool directly. - It gets structured JSON back, with organic results, knowledge graph, local packs, shopping data, ready to use.
llms.txt is the discovery layer, MCP is the execution layer. Together they let an AI agent go from "I've never heard of SerpApi" to "here are the top Google results for your query" in seconds.
Side note: If you're using Claude Code, we just released our own Claude Code plugin.
Low cost, low risk, real upside
We're not going to pretend llms.txt will boost our rankings in Google AI Overviews. The data says it won't, and we trust the data. We also don't expect it to become a universal standard overnight. With roughly 10% industry adoption and no major search engine endorsement, betting on llms.txt as a growth strategy would be naive.
But the cost is near zero; a Markdown file and a few route definitions. There's no risk; it doesn't interfere with existing SEO, crawling, or indexing. And the upside is real; when an AI agent is tasked with integrating a search API and lands on our domain, it immediately understands our entire product surface and can write working integration code.
We're not alone in thinking this way. Yoast added llms.txt generation to their WordPress plugin, with the same argument: "This file isn’t for search engines. It’s for AI assistants trying to give accurate answers based on your content". Drupal's LLM Support recipe provides full spec coverage. The ecosystem is quietly building tooling around this. Not because it's an SEO hack, but because it solves a real content-delivery problem for AI systems.
The critics evaluating (and dismissing) llms.txt as an SEO silver bullet are right to be skeptical. But dismissing it entirely means overlooking the one place where it actually works: helping AI agents understand developer tools. We're not sure it'll matter in two years, or whether something better will come along and replace it. But right now, for what we do, it works.
If you're a developer whose agent just read our llms.txt to integrate SerpApi into your project, that's the whole point.
