 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

Web scraping is the process of pulling out data from websites. If you're familiar with JavaScript, you're in luck! JavaScript offers us some excellent tools to make web scraping easier.
In this tutorial, we'll dive into the basics of web scraping using JavaScript (Node.js), guiding you step-by-step to become confident in fetching and collecting data from the web. If you're new to scraping, we've got you covered!
After this blog post, you can build your web scraper to collect data from static or dynamic websites (Javascript rendered).

Multiple ways to scrape a website with Javascript
There are many ways you can scrape a website using Javascript. In this post, we will cover:
1. Scrape static site programmatically with Cheerio
If the targeted website provides all the content in the initial load, we can use a simple HTTP Client to fetch the raw HTML data and then go through the DOM with an HTML parser like Cheerio.
2. Scraping dynamic content with Puppeteer
Many websites load their content dynamically using Javascript (AJAX). Some information needs human interaction before we can consume it, like scrolling or clicking on a button. We need a headless browser like Puppeteer.
3. One-time scrape with jQuery
jQuery is a very powerful tool. Even Cheerio implements a subset of core jQuery. If you need to scrape something for one time only, you can do this directly in your browser using jQuery.
We'll dig deep into each of these methods in this post,
Step-by-step tutorial on web scraping in Javascript or Node.js with Cheerio
We need two primary tools to perform web scraping in Javascript: HTTP Client and HTML Parser.
- An HTTP API Client to fetch web pages.
e.g. https request standard library, Axios, Got, Needle, SuperAgent, node-fetch, etc - An HTML parser to extract data from the fetched pages.
e.g. jsdom, parse5, and Cheerio
There are many tools out there, but in this guide, we pick Cheerio and Axios.
Cheerio: The fast, flexible & elegant library for parsing and manipulating HTML and XML.
Axios: Axios is a promise-based HTTP Client for Node.js and the browser.
This first tutorial will teach us how to get data from Google Images results.
Step 1: Preparation
Make sure you have Node.js installed. You can download Nodejs here.
Then, let's initialize a new project:
mkdir web-scraping-javascript
cd web-scraping-javascript
npm init -y
Now, install axios and cheerio:
npm install axios cheerio
Step 2: Request the data with an HTTP Client
Please create a new js file; you can call it anything you want. For example main.js.
First, let's request the Google Image endpoint with Axios.
const axios = require('axios');
async function scrapeSite(keyword) {
const url = `https://www.google.com/search?q=${keyword}&tbm=isch`;
const { data } = await axios.get(url);
return data
}
const keyword = "coffee"; // change with any keyword you want
scrapeSite(keyword).then(result => {
console.log(result)
}).catch(err => console.log(err));
Now run it in your Terminal or Command Prompt with:
node main.jsYou'll see the raw HTML file returned from the targeted website.
Step 3: Parse the raw HTML data
As you can see, the raw HTML data above is not easy to read. We need to parse this data and make it easily accessible. To do that, we'll use Cheerio.
Cheerio parses markup and provides an API for traversing/manipulating the resulting data structure.
Let's update our scrapeSite method. We'll pass the raw HTML data to Cheerio's load method.
const axios = require('axios');
const cheerio = require('cheerio'); // new addition
async function scrapeSite(keyword) {
const url = `https://www.google.com/search?q=${keyword}&tbm=isch`;
const { data } = await axios.get(url);
const $ = cheerio.load(data); // new addition
return $ // new addition
}
const keyword = "coffee"; // change with any keyword you want
scrapeSite(keyword).then(result => {
console.log(result)
}).catch(err => console.log(err));$ sign will return a Cheerio object, similar to an array of DOM elements. Now, we can traverse the DOM easily. For example, to get all the span tags in this data:
const spans = [];
$('span').each((_idx, el) => {
const span = $(el).text();
spans.push(span);
});
return spans;Step 4: Collect only the data you need
Now that we can traverse the DOM, let's return to our original task: Scrape the Google image results. Let's say we want to collect the thumbnail image and the text.
First, we need to find the pattern in the DOM where this information is located. I do this by copy-pasting the original raw HTML output to a text editor and observing it.
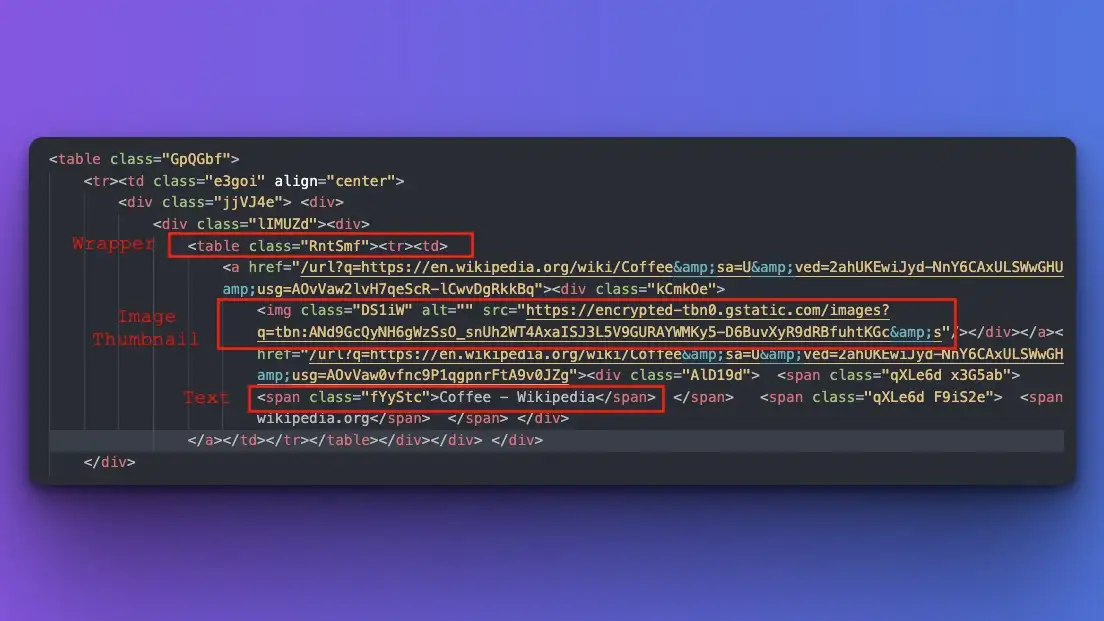
As you can see:
- The image is wrapped on a particular table.
- The image thumbnail is located on the src attribute of the img tag.
- The text is located inside the first span.
Let's collect this data programmatically.
async function scrapeSite(keyword) {
const url = `https://www.google.com/search?gl=us&q=${keyword}&tbm=isch`;
const { data } = await axios.get(url);
const $ = cheerio.load(data);
const results = [];
$('table.RntSmf').each((i, elem) => {
const imgSrc = $(elem).find('img').attr('src');
const text = $(elem).find('span:first-child').text();
results.push({ imgSrc, text });
});
return results;
}The results will look like this:
[
{
imgSrc: 'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQyNH6gWzSsO_snUh2WT4AxaISJ3L5V9GURAYWMKy5-D6BuvXyR9dRBfuhtKGc&s',
text: ' Coffee - Wikipedia Coffee - Wikipediaen.wikipedia.org'
},
{
imgSrc: 'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQ2UVWdcEoKviYWIJh8JsglDWKRy59ldgMhOabz5ArQ034cGxCe7wKjz-r2tw&s',
text: ' Beyond Caffeine: How the... Beyond Caffeine: How the...neurosciencenews.com'
},
{
imgSrc: 'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTglJK5cEyIUg0wT9tDzzJ4vALFfEzZX9LjkbM7XZaqq3WGtojL3OLEm3kN4w&s',
text: ' Coffee bean - Wikipedia Coffee bean - Wikipediaen.wikipedia.org'
},
...
]You can export the data to a CSV file or any database of your choice. Regardless, that's all we need to scrape the thumbnail image and the text information.
If you need more practice, read our Scrape Google Search in Nodejs post, where we scrape the "people also ask" section from Google search results.
But what about the original image source? It's hard to do this right now since we're limited by what Google returns to us via HTTP Client. We'll look at how to get this web page data using another tool in the next section.
FYI: If you need to collect all Google Image results, including the original image source, quickly, you can use our Google Images Results API.
Web scraping with Javascript and Puppeteer Tutorial
Cheerio is fantastic for quickly extracting data from static web pages that don’t change content or layout after they load. But what if a webpage changes content based on user actions, like those fancy websites where information appears only after you click a button or scroll? That’s a job for Puppeteer.
Puppeteer is not alone. There are other alternatives like Nightmare, Selenium, Cypress, PhantomJS or Playwright that are able to run a headless browser to perform actions like real website visitors.
What is Puppeteer?
Puppeteer is a tool that lets us control a Chrome browser through JavaScript. Imagine having a mini-version of Chrome that does everything you command it to do: click buttons, fill out forms, scroll pages, and so on.
Step 1: Preparation
Let's initialize a new project:
mkdir web-scraping-pptr
cd web-scraping-pptr
npm init -y
Now, install puppeteer
npm install puppeteer
Step 2: Hello world test with Puppeteer
Let's simulate if you're visiting the Google Image search page, typing cat as your keyword, and submit the form.
const puppeteer = require('puppeteer');
(async () => {
// Launch the browser and open a new blank page
const browser = await puppeteer.launch();
const page = await browser.newPage();
// Navigate the page to a URL
await page.goto('https://www.google.com/imghp?gl=us&hl=en');
// Set screen size
await page.setViewport({width: 1080, height: 1024});
// Typing and submitting the form
await page.type('textarea[name="q"]', 'cat');
await page.click('button[type="submit"]');
// console log the next page results
await page.waitForNavigation();
console.log('New page URL:', page.url());
await browser.close();
})();- We launch a Chrome/Chromium with the
launchmethod - Visiting a page with
gotomethod - Targeting particular DOM with selectors.
- Perform actions with
typeandclickAPI for typing and submitting a form.
It will print out the "cat search results page" from Google.
Step 3: Take a screenshot with Puppeteer
Do you know that you can also take screenshots of the page you visit with Puppeteer? Let's add this feature!
// Take screenshot of current page
await page.waitForNavigation();
await page.screenshot({path: 'google.png'});
You can name the image file with any name by replacing the google.png above. Don't forget to wait for the program to move to the next page first, with waitForNavigation .
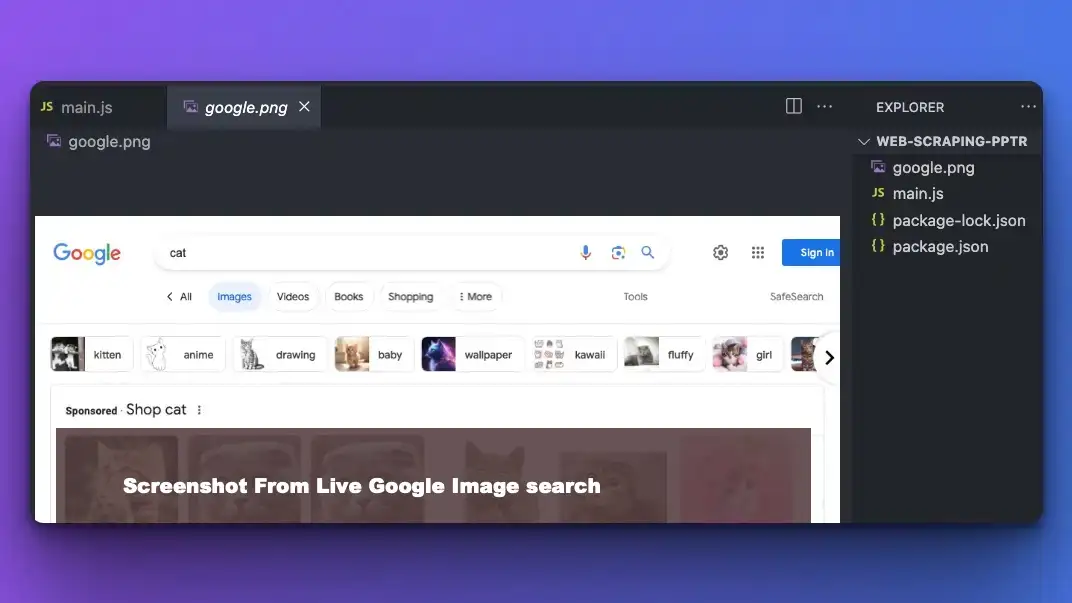
Step 4: Collect dynamic data with Puppeteer
We're back to our original question: "How to get the original image resource on Google image search?".
First, you must understand how to get this data while performing the live search. We have to click on one of the images first, and then we can see the original resource from there.
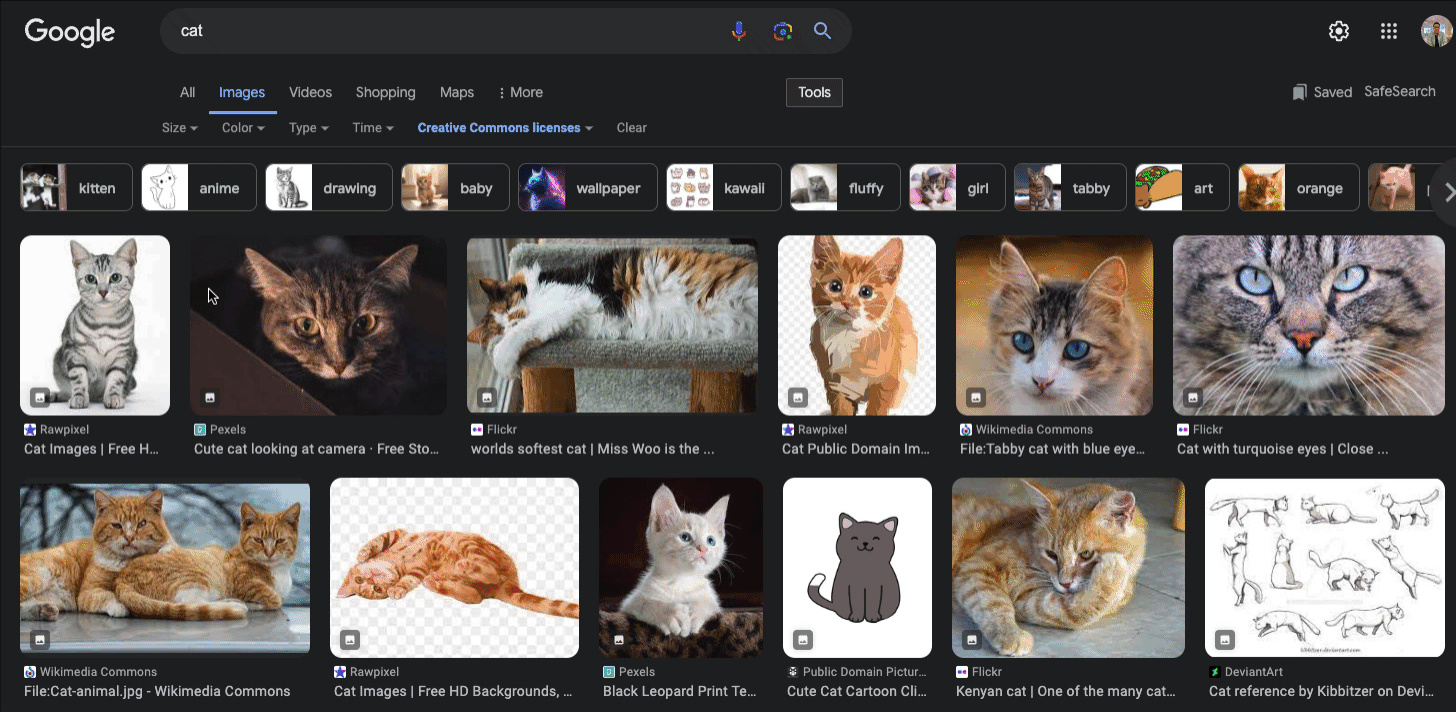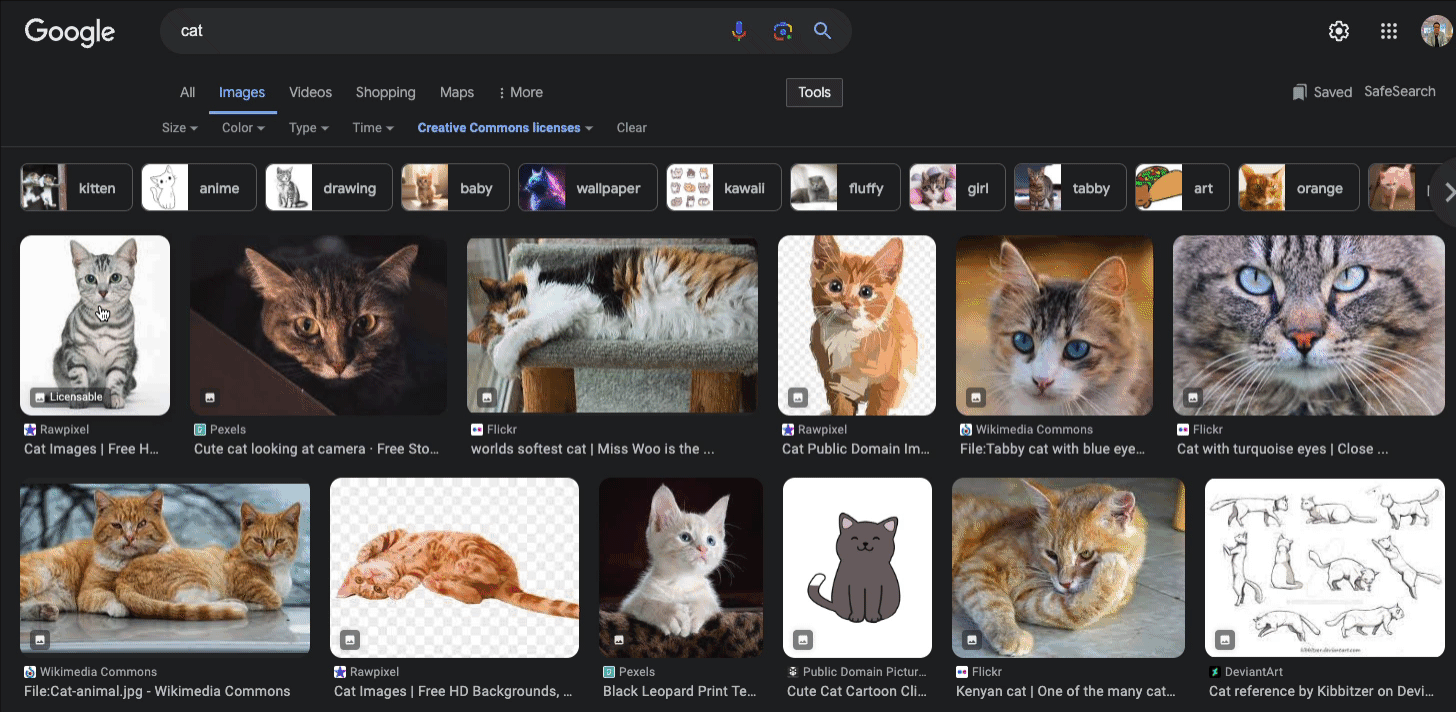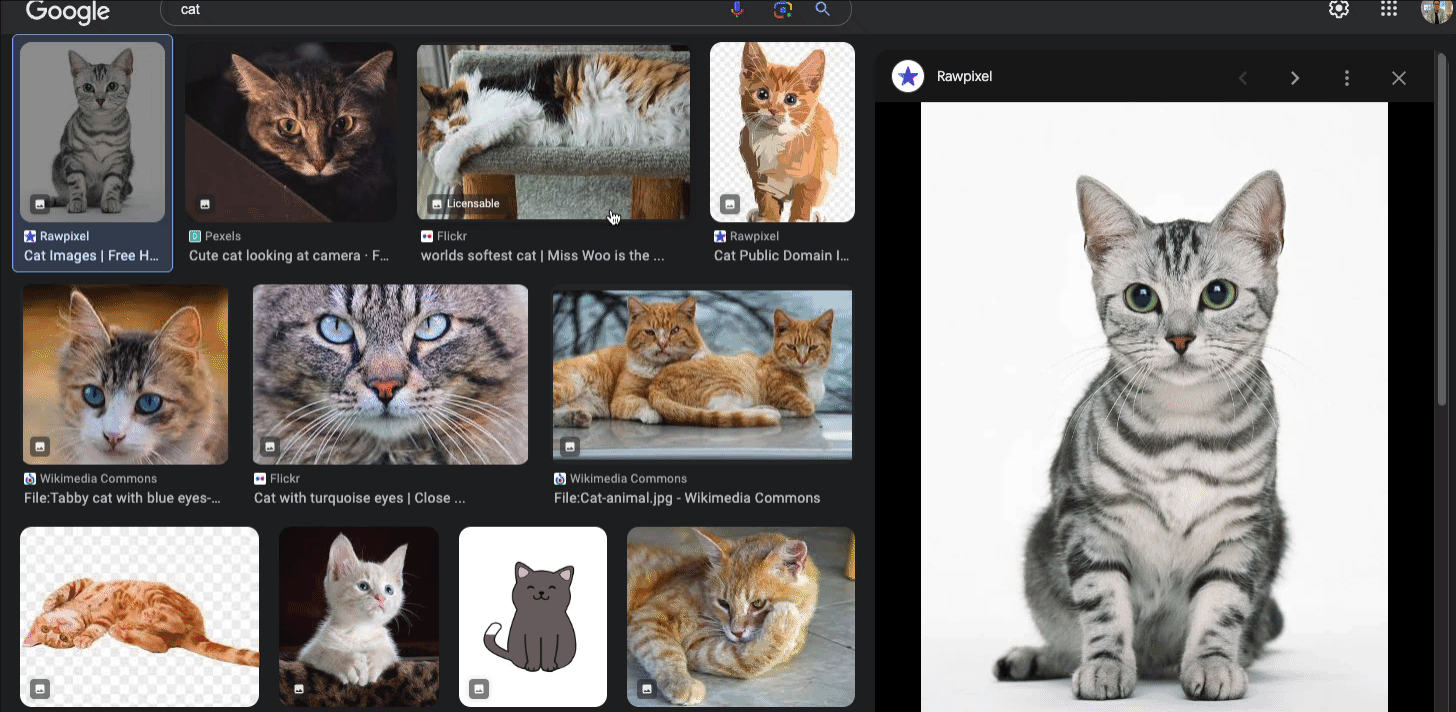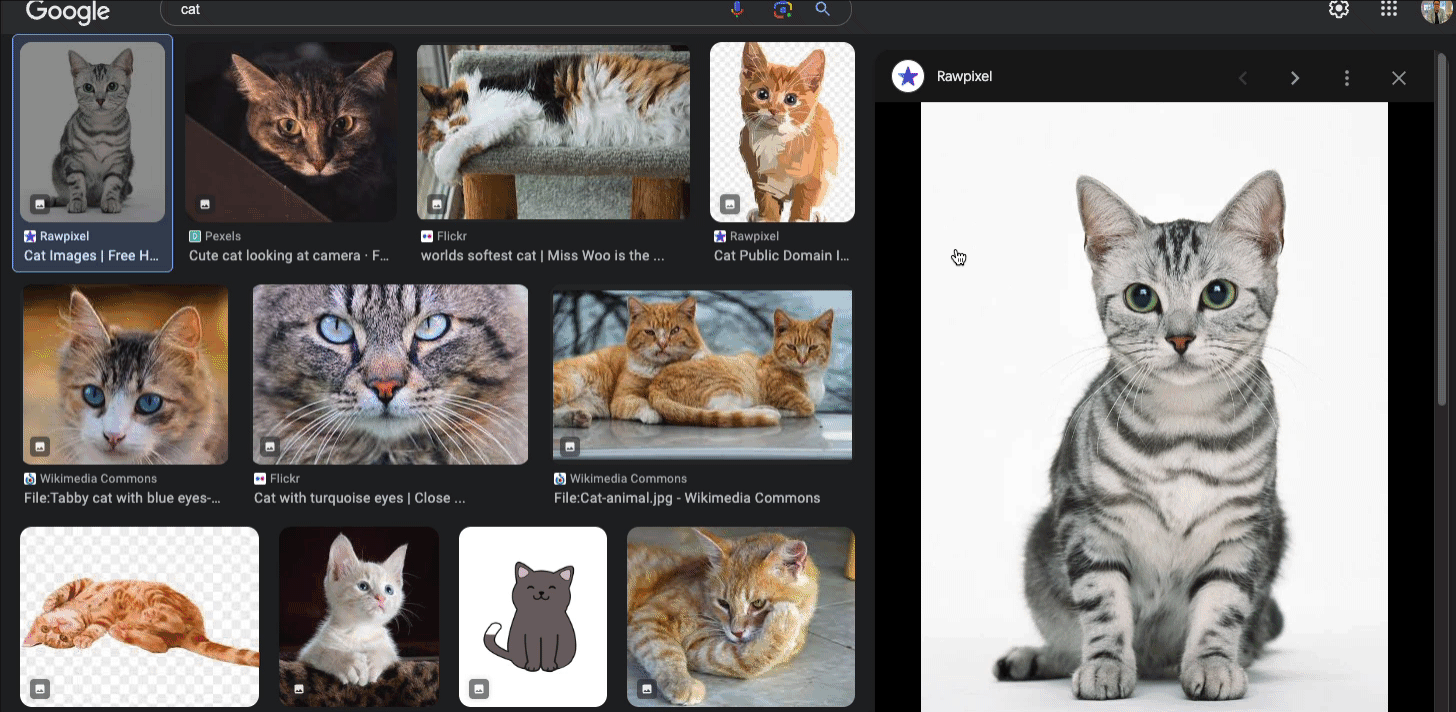
You also need to find the pattern, whatid the preview wrapper is on, and which class is used to display the original image.
The original image information is also available somewhere in the first raw HTML, but for learning purposes, we'll simulate the clicking action first.
Now, let's do this programmatically.
const puppeteer = require('puppeteer');
(async () => {
// Launch the browser and open a new blank page
const browser = await puppeteer.launch();
const page = await browser.newPage();
// Navigate the page to a URL
await page.goto('https://www.google.com/imghp?gl=us&hl=en');
// Set screen size
await page.setViewport({width: 1080, height: 1024});
// debug and print what we see now in raw html
// console.log(await page.content());
await page.type('textarea[name="q"]', 'cat');
await page.click('button[type="submit"]');
await page.waitForNavigation();
// Collect all images with certain class
const images = await page.$$('img.rg_i.Q4LuWd');
// Simulate click on the first image
await images[0].click();
// Wait for the preview div to load, identified with id: "islsp"
await page.waitForSelector('#islsp');
await page.waitForSelector('#islsp img.sFlh5c.pT0Scc.iPVvYb');
// Get the img src from img sFlh5c pT0Scc iPVvYb inside this div
const imgSrc = await page.evaluate(() => {
return document.querySelector('#islsp img.sFlh5c.pT0Scc.iPVvYb').src;
});
console.log(imgSrc);
await browser.close();
})();The class names that Google used could be different from time to time, watch out for this from your raw HTML first.
In the code above:
- We collect all preview images first inside this rg_i.Q4LuWd class.
- Click on the first image (feel free to loop this action to collect all the images)
- Wait for the large image previewer with this ID: islsp
- Wait for the original image on this class to load sFlh5c.pT0Scc.iPVvYb
Now, you can see the original image source for the first image. You can loop this action to collect all the images.
If you want to learn more about Puppeteer, we have a post on how to web scrape dynamic website with Puppeteer.
After seeing the ability to control the browser just like a real visitor, all of these cases are now possible with Web Scraping:
- Log in or register an account
- Fill out form
- Paginate by clicking on the page number or scrolling
- etc.
If you want to collect complete data from Google Search, Google Images, Google Maps, or other search engines, you can use simple APIs from SerpApi. It can save you so much time, rather than building your web scraper to get all this data.
Reading recommendation:
Web scraping with jQuery
As we've seen, web scraping typically involves sending HTTP requests to a target website, parsing the HTML response, and extracting the data you need. While there are specialized libraries in JavaScript, like Puppeteer or Cheerio, that are designed for web scraping and headless browser interactions, jQuery presents a lightweight and straightforward alternative for simpler tasks. This is particularly true if you work directly within a web browser, where jQuery excels at navigating and manipulating the DOM.
Let's practice this on a web page. Open one of toscrape.com pages, where we can collect quotes. jQuery is run in the client's browser, so we need to visit the URL https://quotes.toscrape.com/scroll with an actual browser. Then, right-click and open the developer tools. Now, you can copy and paste this code:
$(document).ready(function () {
// Ensure the '.quotes' element is present
if ($('.quotes').length > 0) {
// Scroll to the bottom of the page
$(window).scrollTop($(document).height());
// Check if '#loading' is hidden
var checkLoading = setInterval(function () {
if ($('#loading').css('display') === 'none') {
// Clear the interval once '#loading' is hidden
clearInterval(checkLoading);
// Collect quotes and log them
var quotes = $('.quote').map(function () {
return {
text: $(this).find('.text').text(),
author: $(this).find('.author').text(),
tags: $(this).find('.tags').text()
};
}).get();
console.log(quotes);
}
}, 100); // Check every 100 milliseconds
} else {
console.error("'.quotes' element not found");
}
});You will see all the available quotes, including the one after scrolling (pagination).
You can even go further by scraping a dynamic website without using any library.
Is Python or JavaScript better for web scraping?
Both Python and JavaScript are capable and popular languages for web scraping, but they have different strengths:
Python Strengths:
- Libraries: Python has a rich ecosystem of libraries like BeautifulSoup, Scrapy, and Requests, making web scraping straightforward.
- Maturity: Tools like BeautifulSoup provide a robust framework for building complex crawlers.
- Integration: Python easily integrates with data analysis and machine learning libraries, which can be helpful if scraping is just the first step in a data processing pipeline.
Best For Large-scale scraping projects, data analysis, or when you want to integrate scraping with other Python-based tasks.
JavaScript (Node.js) Strengths:
- Dynamic Content: Tools like Puppeteer and Playwright are excellent for scraping websites that heavily rely on JavaScript to display content.
- Real Browser Environment: Since it's the language of the web, JavaScript (using tools like Puppeteer) can often emulate user interactions more natively.
- Single Tech Stack: If you're already working with a JavaScript stack or dealing with a web development project, using JavaScript for scraping keeps everything in the same language.
Best For Websites that use a lot of JavaScript or if you're already comfortable with the JavaScript ecosystem.
If you're interested in using Python, read our post on How to scrape Google search results using Python and Python web scraping tutorial.
The "better" language often depends on the specific requirements of your project and your familiarity with the tools in each ecosystem. JavaScript might be more suitable if you're dealing with many dynamic websites. For more general web scraping, especially if combined with data processing, Python has a slight edge.
Feel free to read our beginner's guide on Web Scraping to learn the fundamentals.
Frequently asked questions
What is web scraping?
Web scraping is a way to grab information from websites programmatically. It's like having a helper who reads a website and writes down the important parts for you. It solves the problem of collecting a lot of data quickly.
Can I web scrape with Javascript?
Yes, you can! With JavaScript, especially in combination with Node.js, you can use tools like Puppeteer, Selenium, Axios, and Cheerio to scrape data from websites easily. It's great for both static and dynamic sites that change content using JavaScript.
Is web scraping legal?
The legality of web scraping varies by country and the specific website's terms of service. While some websites allow scraping, others prohibit it. With that being said, you don't need to worry about the legality if you're using SerpApi to collect these search results.
"SerpApi, LLC promotes ethical scraping practices by enforcing compliance with the terms of service of search engines and websites. By handling scraping operations responsibly and abiding by the rules, SerpApi helps users avoid legal repercussions and fosters a sustainable web scraping ecosystem." - source: Safeguarding Web Scraping Activities with SerpApi.
When to Use Puppeteer over Cheerio?
If the website content changes with interactions or has a lot of JavaScript running behind the scenes, Puppeteer is the tool you might want to consider.