 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

I've always been surprised at how good chatGPT by OpenAI is on answering questions and the ability of Dall-e 3 to create stunning images. Now, with the new model, let's see how AI can handle our web scraping tasks, specifically on parsing search engine results. We all know the drill—parsing data from raw HTML can often be cumbersome. But what if there's a way to turn this painstaking process into a breeze?
Recently (November 2023), the OpenAI team had their first developer conference: DevDay (Feel free to watch it first). One of the exciting announcements is a larger context for GPT-4. The new GPT-4 Turbo model is more capable, cheaper, and supports a 128K context window.
Update (15th May 2024)
OpenAI announced a new model yesterday: GPT-4o which is much faster! You shoud see a new benchmark for the new model.

Our little experiment
In the past, we've compared some open-source and paid LLMs' ability to scrape "clean text" data into a simple format and developed an AI powered parser.
This time, we'll level up the challenge.
- Scrape directly from raw HTML data.
- Turn into a specific JSON format that we need.
- Use little development time.
Our Target:
- Scrape a nice structured website (as a warm-up).
- Return organic results from the Google search results page.
- Return the people-also-ask (related questions) section from Google SERP.
- Return local results data from Google MAPS.
Remember that the AI is only tasked with parsing the raw HTML data, not doing the web scraping itself.TLDR;
If you don't want to read the whole post, here is the summary of the pros and cons of our experiment using the OpenAI API (new GPT-4) model for web scraping:
Pros
- New model
gpt-4-1106-previewandgpt-4ois able to scrape raw HTML data perfectly. The larger token window makes it possible just to pass raw HTML to scrape. - OpenAI "function calling" can return the exact response format that we need.
- OpenAI "multiple function calling" can return data from multiple data points.
- The ability to scrape raw HTML is definitely a huge plus compared to the development time when parsing manually.
Cons
- The cost is still high compared to using other SERP API providers.
- Watch out for the cost when passing the whole raw HTML. We still need to trim to scrape only relevant parts. Otherwise, you have to pay a lot for the token usage.
- The speed is still too long to use it for production.
- For "hidden data" that is normally found at the script tag, extra AJAX request, or upon performing an action (e.g., clicking, scrolling), we still need to do it manually.
Tools and Preparation
- Since we're going to use OpenAI's API, make sure to register and have your api_key first. You might need your OpenAI org ID as well.
- I'm using Python for this experiment, but feel free to use any programming language you want.
- Since we want to return a consistent JSON format, we'll be using the new function calling feature from OpenAI, where we can define the response's keys and values with a nice format.
- We're going to use these models
gpt-4-1106-previewandgpt-4o
We've created a beginner-friendly post to understand function calling by OpenAI
Basic Code
Make sure to install the OpenAI library first. Since I'm using Python, I need
pip install openaiI'll also install requests package to get the raw HTML
pip install requests
Here's what our code base will look like:
import json
import requests
from openai import OpenAI
client = OpenAI(
organization='YOUR-OPENAI-ORG-ID',
api_key='YOUR-OPENAI-API-KEY'
)
targetUrl = 'https://books.toscrape.com/' # Target URL will always changes
response = requests.get(targetUrl)
html_text = response.textLevel 1: Scraping on nice/simple structured web page with AI
Let's warm up first. We'll target the https://books.toscrape.com/ site first since it has a very clean structure that makes it easy to read.
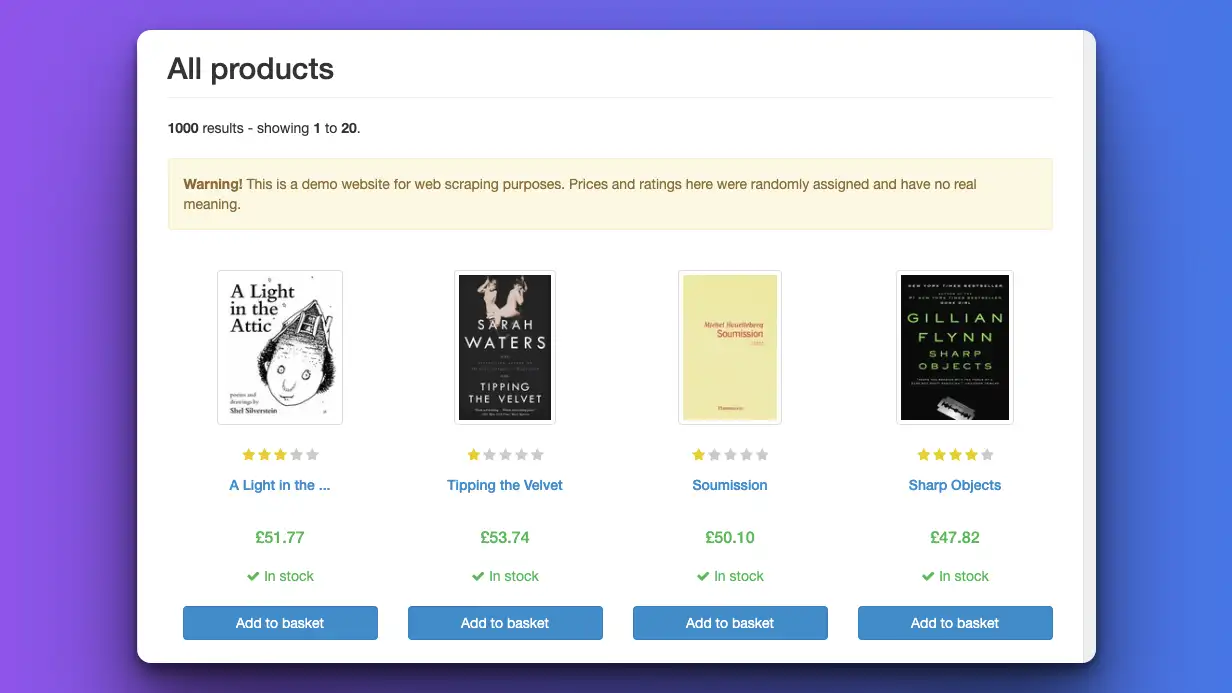
Here's what our code looks like (with explanations below):
# Chat Completion API from OpenAI
completion = client.chat.completions.create(
model="gpt-4-1106-preview", # Feel free to change the model to gpt-3.5-turbo-1106 or gpt-4o
messages=[
{"role": "system", "content": "You are a master at scraping and parsing raw HTML."},
{"role": "user", "content": html_text}
],
tools=[
{
"type": "function",
"function": {
"name": "parse_data",
"description": "Parse raw HTML data nicely",
"parameters": {
'type': 'object',
'properties': {
'data': {
'type': 'array',
'items': {
'type': 'object',
'properties': {
'title': {'type': 'string'},
'rating': {'type': 'number'},
'price': {'type': 'number'}
}
}
}
}
}
}
}
],
tool_choice={
"type": "function",
"function": {"name": "parse_data"}
}
)
# Calling the data results
argument_str = completion.choices[0].message.tool_calls[0].function.arguments
argument_dict = json.loads(argument_str)
data = argument_dict['data']
# Print in a nice format
for book in data:
print(book['title'], book['rating'], book['price'])- We're using the
ChatCompletionAPI from OpenAI - Choose the OpenAI model
- Using the prompt "You are a master at scraping and parsing raw HTML" and passing the raw_html to be analyzed.
- At
toolsparameter, we're defining our imaginary function to parse the raw data. Don't forget to adjust the properties of parameters to return the exact format you want.
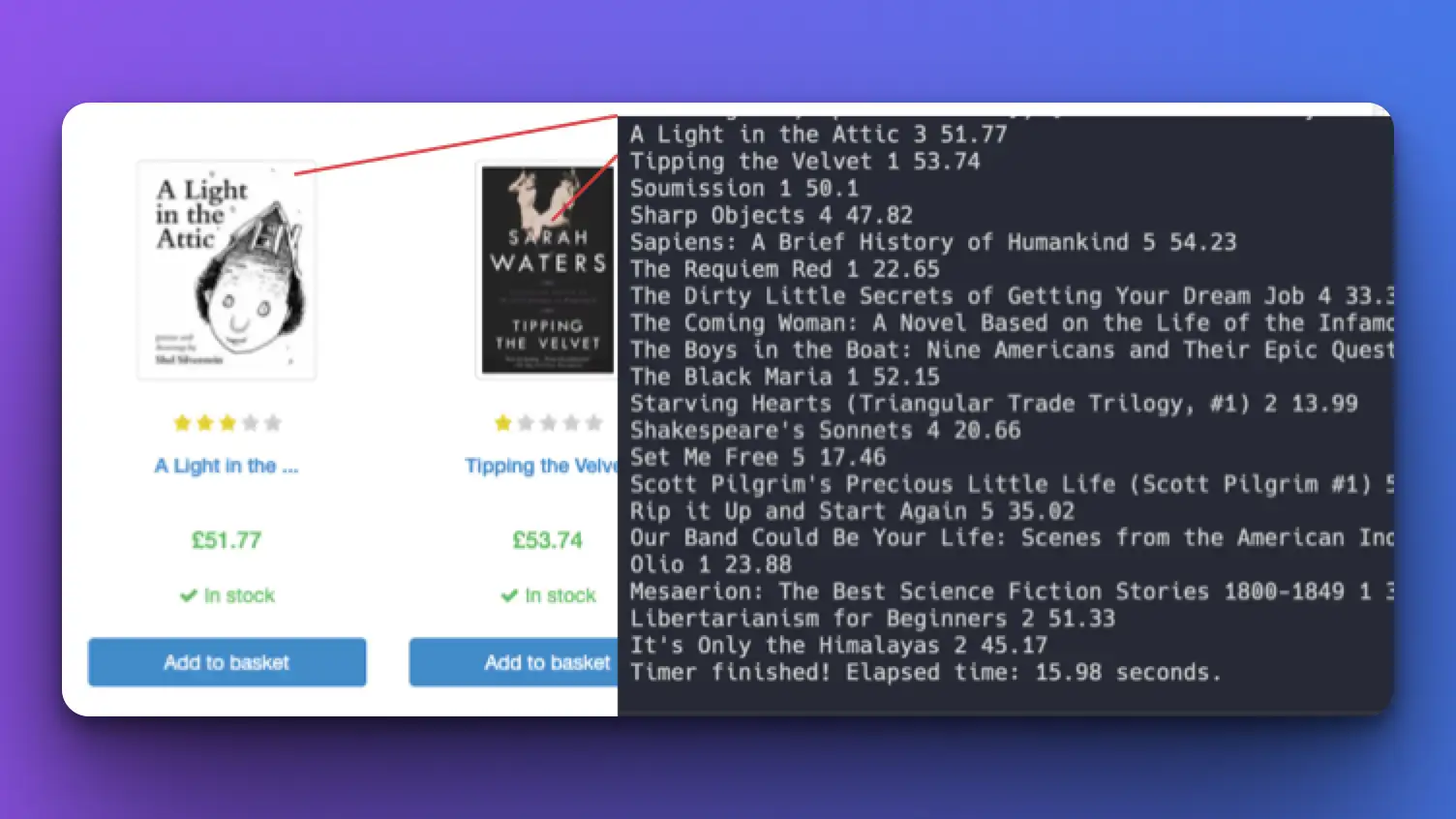
Here is the result
We're able to scrape the title, rating, and price (exactly the data we defined in the function parameters above) of each book.
Time to finish for GPT-4-1106-preview: ~15s
Time to finish for GPT-4o: ~10s - 11s
Using gpt-3.5
When switching to gpt-3.5-turbo-1106 , I have to adjust the prompt to be more specific:
messages: {"role": "system", "content": "You are a master at scraping and parsing raw HTML. Scrape ALL the book data results"},
# And the function description
"function": {
"name": "parse_data",
"description": "Get all books data from raw HTML data",
}Without mentioning "scrape ALL book data," it will just get the first few results.
Time to finish: ~9s
Level 2: Parse organic results from Google SERP with AI
The Google search results page is not like the previous site. It has a more complicated structure, unclear CSS class names, and includes a lot of unknown data in the raw HTML.
Target URL: 'https://www.google.com/search?q=coffee&gl=us'
WARNING! At first, I just parsed everything from Google raw HTML, it turns out it contains too many characters, which means more tokens and more costs!
So, after few tries, I decided to trim only the body part and remove the style and script tag contents.
I've adjusted the prompt and function parameters like this:
import re #additional import for regex
response = requests.get('https://www.google.com/search?q=coffee&gl=us')
html_text = response.text
# Remove unnecessary part to prevent HUGE TOKEN cost!
# Remove everything between <head> and </head>
html_text = re.sub(r'<head.*?>.*?</head>', '', html_text, flags=re.DOTALL)
# Remove all occurrences of content between <script> and </script>
html_text = re.sub(r'<script.*?>.*?</script>', '', html_text, flags=re.DOTALL)
# Remove all occurrences of content between <style> and </style>
html_text = re.sub(r'<style.*?>.*?</style>', '', html_text, flags=re.DOTALL)
completion = client.chat.completions.create(
model="gpt-4-1106-preview",
messages=[
{"role": "system", "content": "You are a master at scraping Google results data. Scrape top 10 organic results data from Google search result page."},
{"role": "user", "content": html_text}
],
tools=[
{
"type": "function",
"function": {
"name": "parse_data",
"description": "Parse organic results from Google SERP raw HTML data nicely",
"parameters": {
'type': 'object',
'properties': {
'data': {
'type': 'array',
'items': {
'type': 'object',
'properties': {
'title': {'type': 'string'},
'original_url': {'type': 'string'},
'snippet': {'type': 'string'},
'position': {'type': 'integer'}
}
}
}
}
}
}
}
],
tool_choice={
"type": "function",
"function": {"name": "parse_data"}
}
)
argument_str = completion.choices[0].message.tool_calls[0].function.arguments
argument_dict = json.loads(argument_str)
data = argument_dict['data']
for result in data:
print(result['title'])
print(result['original_url'] or '')
print(result['snippet'] or '')
print(result['position'])
print('---')- First, we trim only the selected part.
- Adjust the prompt to "You are a master at scraping Google results data. Scrape top 10 organic results data from Google search result page."
- Adjust the function parameters to any format you need.
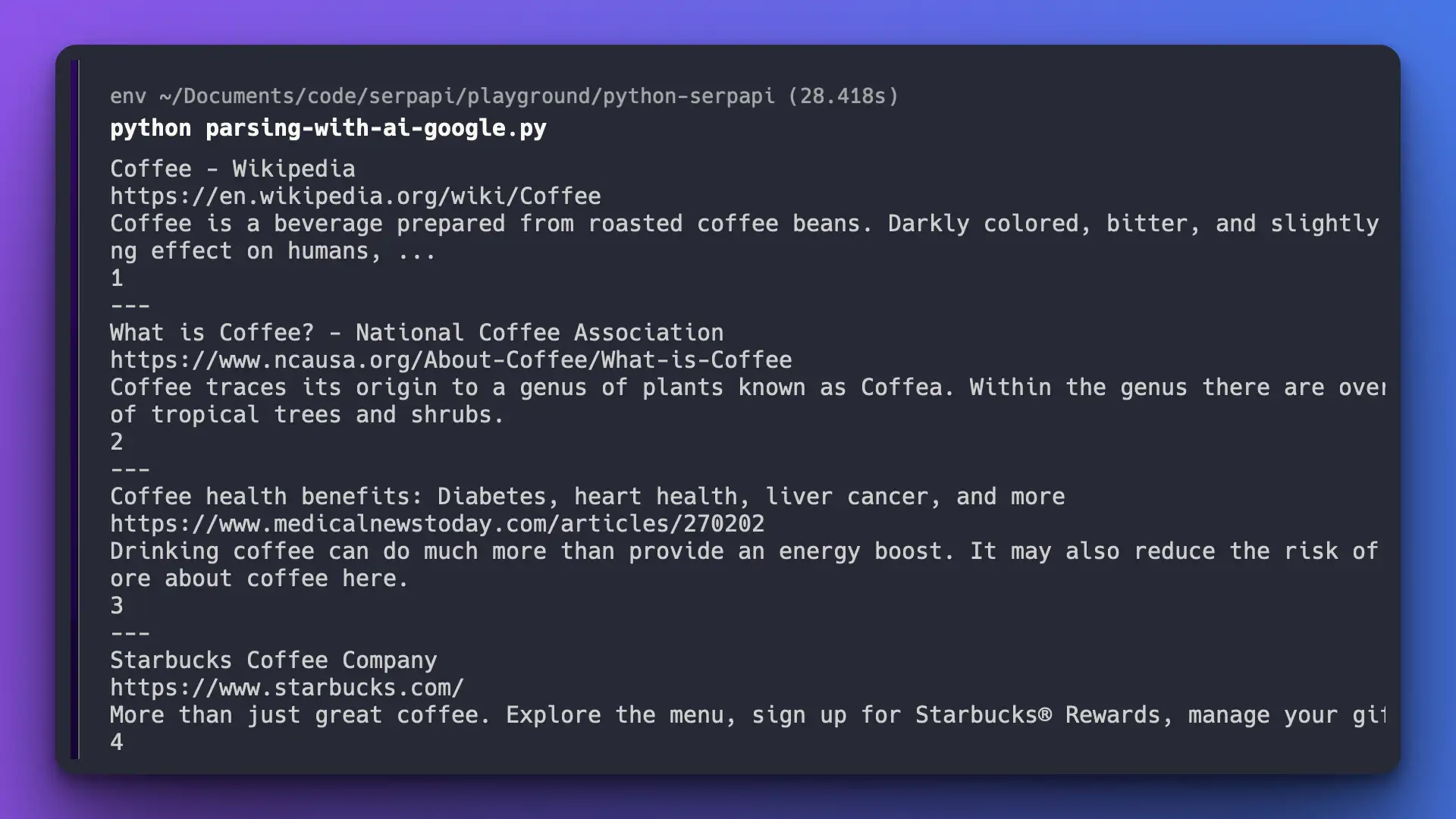
Ta-da! We get exactly the data we need despite the complicated format from Google raw HTML.
Time to finish for GPT-4-1106-preview: ~28s
Time to finish for GPT-4o: ~16s
Notes: My original prompt was "Parse organic results from Google SERP raw HTML data nicely" It only returns the first 3-5 results, so I adjusted the prompt to get a more precise amount of results.
Using gpt-3.5 model
I'm not able to do this since the raw HTML data amount exceeds the token length.
Level 3: Parse local place results from Google Maps with AI
Now, let's scrape another Google product, which is Google Maps. This is our target page: https://www.google.com/maps/search/coffee/@40.7455096,-74.0083012,14z?hl=en&entry=ttu
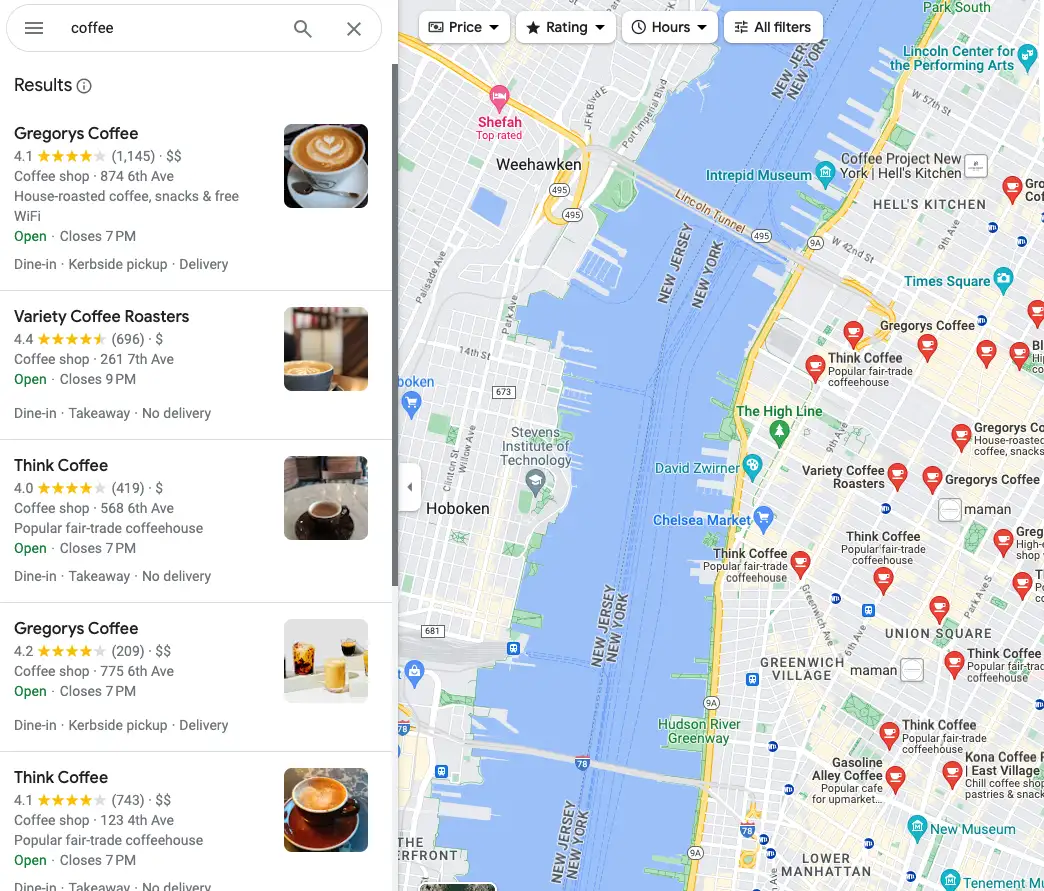
As you can see, each of the items includes a lot of information. We'll scrape:
- Name
- Rating average
- Total rating
- Price
- Address
- Extras
- Hours
- Additional service
- Thumbnail image
Warning! It turns out, Google Maps loads this data via Javascript, so I have to change my method to get the raw_html from usingrequeststoseleniumfor python.
Code
Install Selenium on Python. More instructions on installation are here.
pip install seleniumImport Selenium
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import ByCreate a headless browser instance to surf the web
target_url = 'https://www.google.com/maps/search/coffee/@40.7455096,-74.0083012,14z?hl=en'
op = webdriver.ChromeOptions()
op.add_argument('headless')
driver = webdriver.Chrome(options=op)
driver.get(target_url)
driver.implicitly_wait(1) # seconds
# get raw html
html_text = driver.page_source
# You can continue like previous method, where we trim only the body part firstI wait 1 second with implicitly_wait to make sure the data is already there to scrape.
Now, here's the OpenAI API function:
completion = client.chat.completions.create(
model="gpt-4-1106-preview",
messages=[
{"role": "system", "content": "You are a master at scraping Google Maps results. Scrape all local places results data"},
{"role": "user", "content": html_text}
],
tools=[
{
"type": "function",
"function": {
"name": "parse_data",
"description": "Parse local results detail from Google MAPS raw HTML data nicely",
"parameters": {
'type': 'object',
'properties': {
'data': {
'type': 'array',
'items': {
'type': 'object',
'properties': {
'position': {'type': 'integer'},
'title': {'type': 'string'},
'rating': {'type': 'string'},
'total_reviews': {'type': 'string'},
'price': {'type': 'string'},
'type': {'type': 'string'},
'address': {'type': 'string'},
'phone': {'type': 'string'},
'hours': {'type': 'string'},
'service_options': {'type': 'string'},
'image_url': {'type': 'string'},
}
}
}
}
}
}
}
],
tool_choice={
"type": "function",
"function": {"name": "parse_data"}
}
)
argument_str = completion.choices[0].message.tool_calls[0].function.arguments
argument_dict = json.loads(argument_str)
data = argument_dict['data']
print(data)Result:
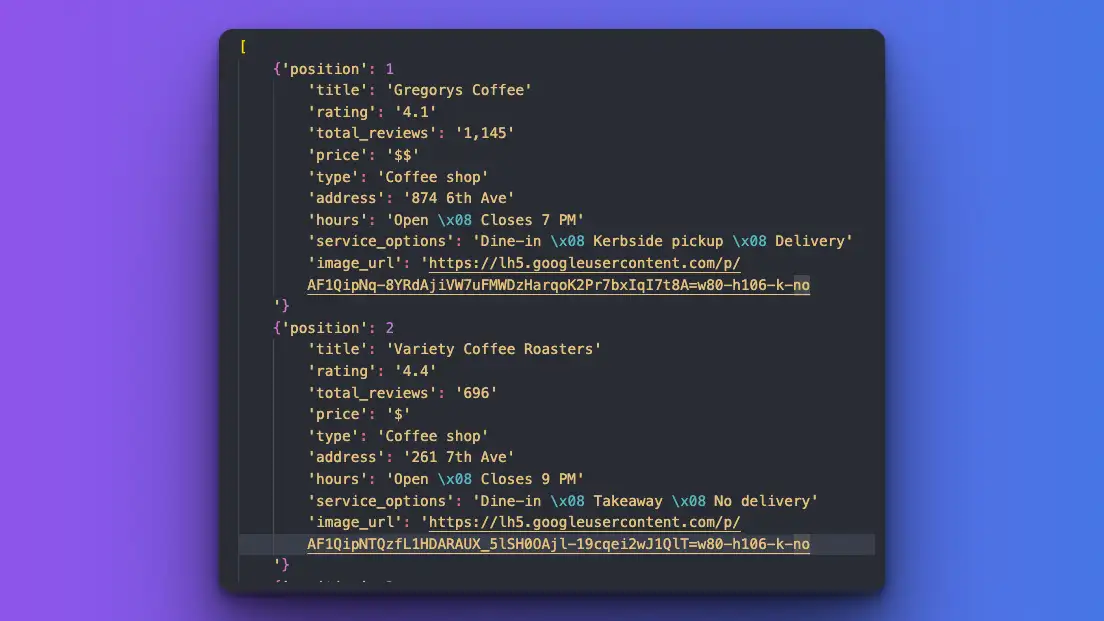
It turns out perfect! I'm able to get the exact data for each of these local_results.
GPT-4-1106-preview
Time to finish with Selenium: ~47s
Time to finish (exclude Selenium time): ~34s
GPT-4o
Time to finish with Selenium: ~15s
Time to finish (exclude Selenium time): ~16s
Level 4: Parsing two different data (organic results and people-also-ask section) from Google SERP with AI
As you might know, Google SERP doesn't just display organic results, but also other data, like ads, people-also-ask (related questions), knowledge graphs, and so on.
Let's see how to target multiple data points with multiple functions calling features from OpenAI.
Here's the code:
completion = client.chat.completions.create(
model="gpt-4-1106-preview", //or gpt-4o
messages=[
{"role": "system", "content": "You are a master at scraping Google results data. Scrape two things: 1st. Scrape top 10 organic results data and 2nd. Scrape people_also_ask section from Google search result page."},
{"role": "user", "content": html_text}
],
tools=[
{
"type": "function",
"function": {
"name": "parse_organic_results",
"description": "Parse organic results from Google SERP raw HTML data nicely",
"parameters": {
'type': 'object',
'properties': {
'data': {
'type': 'array',
'items': {
'type': 'object',
'properties': {
'title': {'type': 'string'},
'original_url': {'type': 'string'},
'snippet': {'type': 'string'},
'position': {'type': 'integer'}
}
}
}
}
}
}
},
{
"type": "function",
"function": {
"name": "parse_people_also_ask_section",
"description": "Parse `people also ask` section from Google SERP raw HTML",
"parameters": {
'type': 'object',
'properties': {
'data': {
'type': 'array',
'items': {
'type': 'object',
'properties': {
'question': {'type': 'string'},
'original_url': {'type': 'string'},
'answer': {'type': 'string'},
}
}
}
}
}
}
}
],
tool_choice="auto"
)
# Organic_results
argument_str = completion.choices[0].message.tool_calls[0].function.arguments
argument_dict = json.loads(argument_str)
organic_results = argument_dict['data']
print('Organic results:')
for result in organic_results:
print(result['title'])
print(result['original_url'] or '')
print(result['snippet'] or '')
print(result['position'])
print('---')
# People also ask
argument_str = completion.choices[0].message.tool_calls[1].function.arguments
argument_dict = json.loads(argument_str)
people_also_ask = argument_dict['data']
print('People also ask:')
for result in people_also_ask:
print(result['question'])
print(result['original_url'] or '')
print(result['answer'] or '')
print('---')
Code Explanation:
- Adjust the prompt to include specific information on what to scrape: "You are a master at scraping Google results data. Scrape two things: 1st. Scrape top 10 organic results data and 2nd. Scrape the the people_also_ask section from the Google search result page."
- Adding and separating functions, one for organic results, and one for people-also-ask section.
- Testing the output in two different formats.
Here's the result:
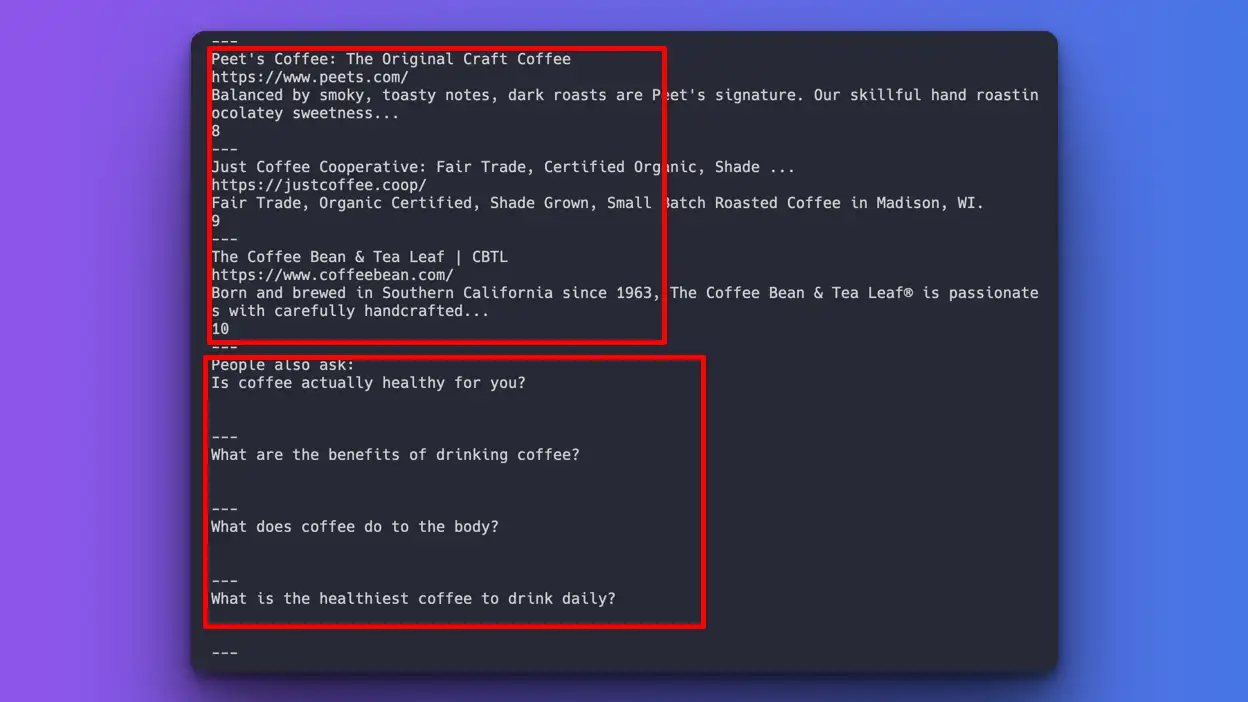
Success:
I'm able to scrape both the organic_results and people_also_ask separately. Kudos to OpenAI!
Problem:
I'm not able to scrape the answer and original URL for the people_also_ask section. The reason is that this information is hidden somewhere in the script tag. We could try this by providing that specific part of the script content, but I would consider it cheating for this experiment, as we want to pass the raw HTML without pinpointing or giving a hint.
Time to finish for GPT-4-1106-preview: ~30s
Time to finish for GPT-4o: ~19s
If you want to learn how to scrape this data cheaper, faster, and more accurately, you can read these posts:
Table comparison with SerpApi
Here's the timetable comparison using OpenAI's new GPT-4 model for web scraping VS SerpApi . We're comparing with the 'normal speed'; SerpApi has faster (roughly twice as fast) when using Ludicrous Speed.
| Subject | gpt-4-1106-preview | gpt-4o | SerpApi |
|---|---|---|---|
| Organic results | 28s | 16s | 2.4s |
| Organic results with Related questions | 30s | 19s | 2.4s |
| Maps local results | 34s | 16s | 2.4s |
Using custom GPT to scrape search engine
On the same conference, Sam Altman also announce a new feature "custom GPT", where people can make a chatGPT custom-tailored to their needs.
Here is a related blog post if you're interested in this:
- The basic: How to create custom GPT (step-by-step tutorial).
- Want to scrape Google results from chatGPT? Read: How to connect custom GPT to the internet.
Testing other LLM
- We also experimented with parsing raw HTML data with the Mistral7B model. Feel free to check this out: Parsing with Mistral7B Model
- We also tried Vision API by OpenAI to parse data from an image.
Conclusion
OpenAI definitely improves a lot of over time. Now, it's possible to scrape a website and collect relevant data with the API. But based on the time it takes, it's not yet ready for production, commercial purpose, or scale. While the accuracy of the data and response format turns out perfect, it's still far behind in terms of cost and speed.
Let me know if you have any thoughts, spot any mistakes, and have other experiments you want to add that are relevant to this post to hilman(at)serpapi(dot)com.
Thank you for reading this post!