 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 C++
C++

Naver (Hangul: 네이버) is a South Korean online platform operated by the Naver Corporation. It debuted in 1999 as the first web portal in South Korea to develop and use its own search engine. It was also the world's first operator to introduce the comprehensive search feature, which compiles search results from various categories and presents them on a single page.
Introduction
In the age of data-driven decision-making, web scraping has become an essential tool in the repertoire of data scientists and programmers. However, web scraping can be a complex task due to the dynamic nature of web pages and their specific structure. Naver can be challanging to scrape some of it's pages such as Images search results since it get its results from API endpoint so scraping the actual HTML page is useless.
In Naver videos it's easy to scrape when it comes to the regular video results, but it's a little bit tricky when trying to scrape and handle the pagination for the video results page but that's another story for another time.
In this blog post, we will demonstrate how to scrape video search results from Naver, a popular South Korean online platform, using Python.
Required Libraries
requests: This is a Python module used for making various types of HTTP requests like GET and POST. In this case, we will use it to send a GET request to the Naver page and get the HTML content.BeautifulSoup: A Python library used for web scraping purposes to pull the data out of HTML and XML files. It creates a parse tree that can be used to extract data more easily.
pip install requests beautifulsoup4
Python Script: Let's now look at our Python script step by step:
import requests
from bs4 import BeautifulSoup
import json
First, we import the necessary libraries. requests is used for making HTTP requests, BeautifulSoup for parsing HTML and json for outputting our results in JSON format.
url = "https://search.naver.com/search.naver?where=video&sm=top_hty&fbm=0&ie=utf8&query=coffee"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
We then define the URL for the page we want to scrape and send a GET request to it. The server responds to the request by returning the HTML content of the webpage. We then create a BeautifulSoup object and specify the parser library at the same time.
videos = soup.select('div.subject_bx li.video_item, .sp_nvideo li.video_item')
The select method in BeautifulSoup lets us pick out the parts of the webpage we're interested in. Here, we're looking for all list items (li) with the class video_item that are children of either a div with the class subject_bx or a li with the class sp_nvideo.
for i, video in enumerate(videos, start=1):
Next, we iterate over each video item. The enumerate function adds a counter to the iterable and returns it as an enumerate object, allowing us to track the current position.
title_link_node = video.select_one('a.info_title')
The select_one a method in BeautifulSoup lets us pick out the first matching element in the webpage we're interested in. Here, we're looking for an anchor (a) with the class info_title.
result['title'] = title_link_node.get_text(strip=True)
result['link'] = title_link_node['href']
Next, we extract the video title and link from the title_link_node. We use the get_text method to get the text content of the HTML node, and we access the href attribute to get the link.
This process is repeated for the other elements we're interested in, such as duration, origin, thumbnail, views, publish date, and channel.
Finally, we output the results in a JSON format using the json.dumps method.
Final Script
import requests
from bs4 import BeautifulSoup
import json
# Url of Naver video search for 'coffee'
url = "https://search.naver.com/search.naver?where=video&sm=top_hty&fbm=0&ie=utf8&query=coffee"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
video_results = []
videos = soup.select('div.subject_bx li.video_item, .sp_nvideo li.video_item')
for i, video in enumerate(videos, start=1):
result = {}
title_link_node = video.select_one('a.info_title')
duration_node = video.select_one('span.time, .api_time')
origin_node = video.select_one('.origin')
thumbnail_node = video.select_one('img')
channel_node = video.select_one('a.channel')
views_node = video.select_one('i.spnew.api_ico_count')
info_node = video.select('.desc_group:not(:has(.desc_group_inner)) .desc')
if title_link_node:
result['title'] = title_link_node.get_text(strip=True)
result['link'] = title_link_node['href']
if duration_node:
result['duration'] = duration_node.get_text(strip=True)
if origin_node:
result['origin'] = origin_node.get_text(strip=True)
if thumbnail_node:
thumbnail = thumbnail_node.get('data-lazysrc', thumbnail_node['src'])
result['thumbnail'] = thumbnail
if views_node and info_node:
result['views'] = views_node.next_sibling.get_text(strip=True)
result['publish_date'] = info_node[0].get_text(strip=True)
if channel_node:
result['channel'] = {
'name': channel_node.get_text(strip=True),
'link': channel_node['href']
}
video_results.append(result)
final_hash = {'video_results': video_results}
print(json.dumps(final_hash, indent=4, ensure_ascii=False))
We will run the script by executing the following command python naver_videos.py and we will get the results printed as JSON, and the results are identical to what SerpApi provides in our Naver Videos API, ofc our API is optimized to be 10x times faster and provide more results with captcha solving and many more features so don't miss our Naver Video API.
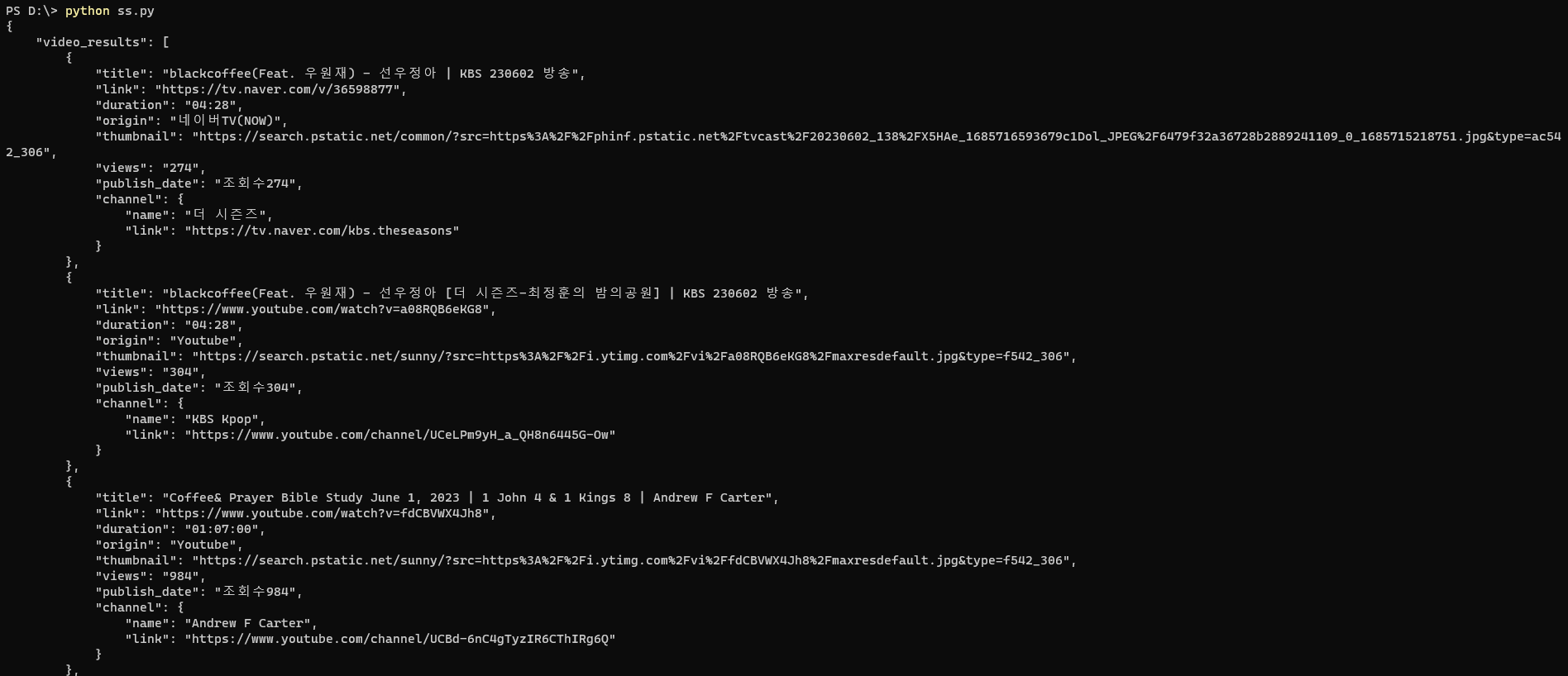
Ending
We will continue discovering the Naver search engine with SerpApi.
Don't miss the other blog post about Scraping Naver video results with SerpApi
- You can sign-up for SerpApi here: https://serpapi.com/
- You can find the SerpApi user forum here: https://forum.serpapi.com/
- You can find the API documentation here: https://serpapi.com/search-api/
- You can follow us on Twitter at @serp_api, to get our latest news and articles.