 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

What will be scraped
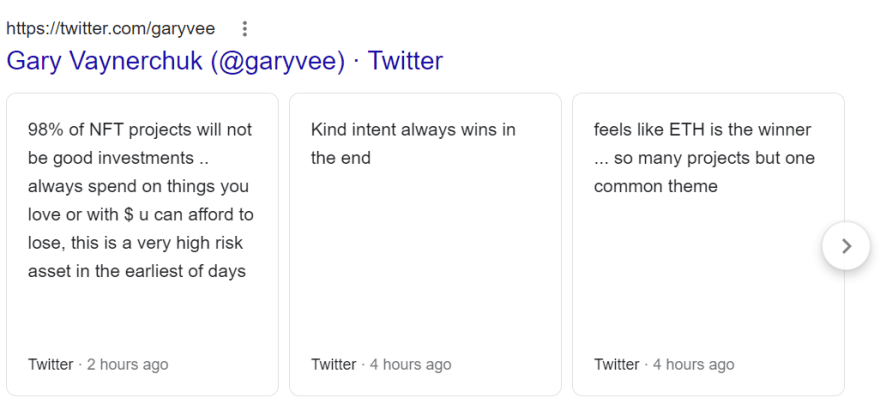
Google Twitter Results API
Why use it over the DIY code below? No need to create the parser from scratch, maintain it, and figure out how to bypass blocks.
import json
from serpapi import GoogleSearch
params = {
"api_key": "...", # https://serpapi.com/manage-api-key
"engine": "google", # search engine
"q": "garyvee twitter", # search query
"hl": "en" # language
}
search = GoogleSearch(params) # where data extracts
results = search.get_dict() # JSON -> Python dict
title = results['twitter_results']['title']
link = results['twitter_results']['link']
displayed_link = results['twitter_results']['displayed_link']
tweets = results['twitter_results']['tweets']
print(f'{title}\n{link}\n{displayed_link}\n{json.dumps(tweets, indent=2)}\n')
----------------------
'''
Gary Vaynerchuk (@garyvee) · Twitter
https://twitter.com/garyvee?ref_src=twsrc%5Egoogle%7Ctwcamp%5Eserp%7Ctwgr%5Eauthor
https://twitter.com/garyvee
[
{
"link": "https://twitter.com/garyvee/status/1420238044259565569?ref_src=twsrc%5Egoogle%7Ctwcamp%5Eserp%7Ctwgr%5Etweet",
"snippet": "98% of NFT projects will not be good investments .. always spend on things you love or with $ u can afford to lose, this is a very high risk asset in the earliest of days",
"published_date": "3 hours ago"
}
...
]
'''DIY Process
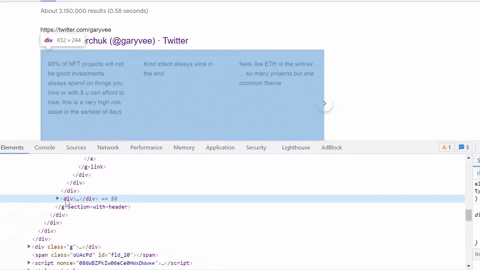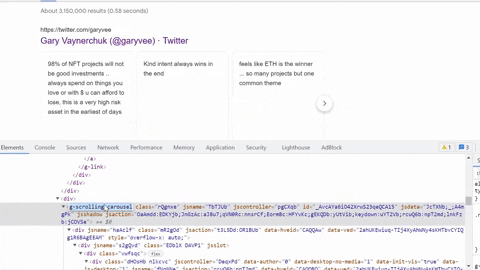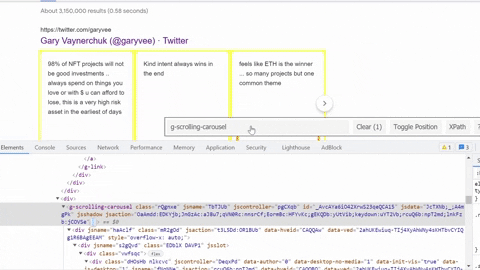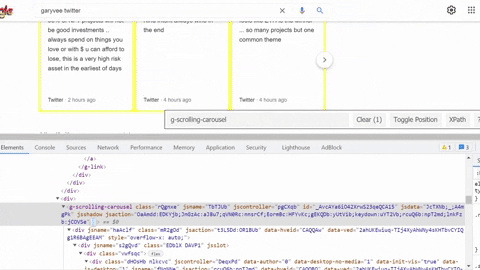
Selecting author info container, title, link, displayed link.
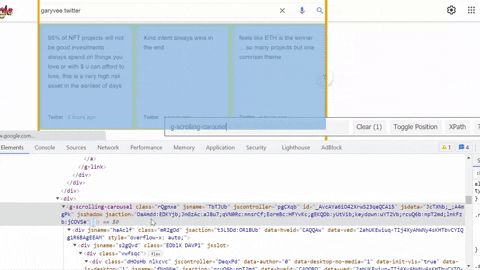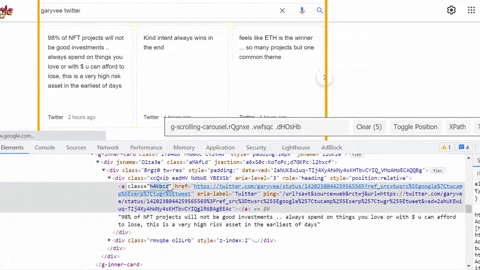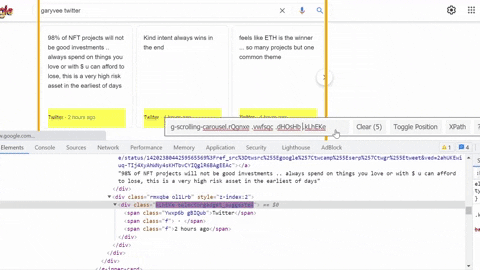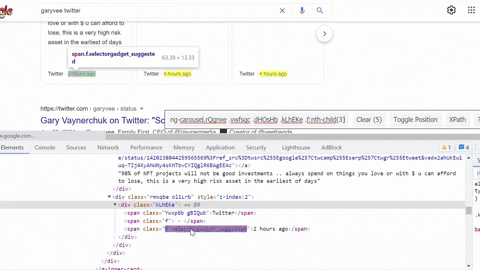
Same process goes for selecting tweet snippet, tweet published date, tweet link.
Full DIY Code
import requests, lxml
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
params = {
"q": "garyvee twitter",
"hl": "en",
"gl": "us"
}
response = requests.get("https://www.google.com/search", headers=headers, params=params)
soup = BeautifulSoup(response.text, 'lxml')
for result in soup.select('[jscontroller=yz368b]'):
title = result.select_one('g-link .a-no-hover-decoration .NsiYH').text
link = result.select_one('g-link .a-no-hover-decoration')['href']
displayed_link = result.select_one('g-link .a-no-hover-decoration .V0XQK').text
print(f'{title}\n{link}\n{displayed_link}\n')
for tweet in result.select('g-scrolling-carousel.rQgnxe .dHOsHb g-inner-card'):
tweet_link = tweet.select_one('.h4kbcd')['href']
tweet_snippet = tweet.select_one('.xcQxib').text
tweet_published = tweet.select_one('.kLhEKe .f:nth-child(3)').text
print(f'{tweet_link}\n{tweet_snippet}\n{tweet_published}')
-------------------
'''
Gary Vaynerchuk (@garyvee) · Twitterhttps://twitter.com/garyvee
https://twitter.com/garyvee?ref_src=twsrc%5Egoogle%7Ctwcamp%5Eserp%7Ctwgr%5Eauthor
https://twitter.com/garyvee
https://twitter.com/garyvee/status/1420238044259565569?ref_src=twsrc%5Egoogle%7Ctwcamp%5Eserp%7Ctwgr%5Etweet
98% of NFT projects will not be good investments .. always spend on things you love or with $ u can afford to lose, this is a very high risk asset in the earliest of days
3 hours ago
https://twitter.com/garyvee/status/1420211442490486789?ref_src=twsrc%5Egoogle%7Ctwcamp%5Eserp%7Ctwgr%5Etweet
Kind intent always wins in the end
5 hours ago
https://twitter.com/garyvee/status/1420207827210153987?ref_src=twsrc%5Egoogle%7Ctwcamp%5Eserp%7Ctwgr%5Etweet
feels like ETH is the winner ... so many projects but one common theme
5 hours ago
'''