 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

Have you ever wanted to collect data from websites automatically? Maybe you're interested in tracking product prices, gathering news articles, or compiling a list of businesses.

What is Web Scraping?
Web scraping is the process of automatically extracting information from websites. Instead of manually copying and pasting data, a web scraper does the heavy lifting by fetching the web pages and extracting the desired information.
Choose Your Tools
Before we dive in, it's essential to know that web scraping can be done using a variety of programming languages and tools—not just Python. Whether you're comfortable with JavaScript, Ruby, Go, or any other language, libraries and frameworks are available to help you scrape websites.

You can click on the sidebar to jump to the implementation of your desired programming language.
If you're not into coding or prefer a quicker setup, there are also low-code and no-code tools that make web scraping accessible to everyone. It might be less flexible than writing your program.
The Two Core Steps of Web Scraping
Web scraping generally involves two fundamental steps:
- Requesting the HTML Content
- Parsing the Relevant Data
Let's dive into what each of these steps entails.
1. Requesting the HTML Content
The first step in web scraping is to fetch the HTML content of the web page you want to scrape. This is similar to how your web browser works when you visit a website—it sends a request to the server, and the server responds with the HTML, CSS, JavaScript, and other resources needed to display the page.
In web scraping, you'll use a programming language or tool to send an HTTP request to the website's server. This can be done using various methods:
- Programming Libraries: Languages like Python (with the
requestslibrary), JavaScript, Ruby, and others have libraries that make it easy to send HTTP requests. - Built-in Functions: Some languages have built-in functions for making web requests.
By requesting the HTML content, you're retrieving the raw data that makes up the web page, which you can then process and analyze.
2. Parsing the Relevant Data
Once you've obtained the HTML content, the next step is to parse it to extract the information you're interested in. Web pages are structured documents that use HTML tags to define elements like headings, paragraphs, links, images, and more.
To navigate through the HTML document, we can use CSS Selector or XPath.
Parsing involves:
- Understanding the Structure: To find your desired data, you'll need to inspect the HTML. This often involves looking at the tags, classes, or IDs encapsulating the data.
You can right-click and click inspect in browsers to see the HTML structure. Alternatively, you can choose "view page source" to open the raw HTML on a new tab.
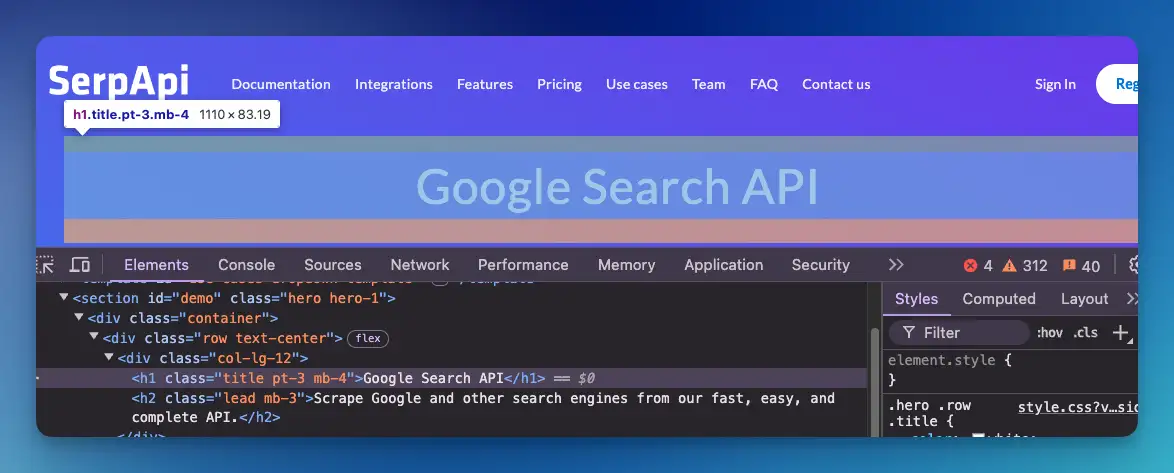
- Using Parsing Tools or Libraries:
- For Programmers: Libraries like Beautiful Soup (Python), Cheerio (JavaScript), Nokogiri/Nokolexbor (Ruby), and others can parse HTML and XML documents, allowing you to navigate and search the document tree.
- Extracting the Data: Once you've identified the correct elements, you can extract the text, attributes, or other relevant information.
You can even use AI to parse raw HTML into nice structured data.
By parsing the relevant data, you transform the raw HTML into meaningful information that you can use for your specific needs, like building a dataset, analyzing trends, or feeding into another application.
Practice
It's time to practice. Let's use the Hackernews: https://news.ycombinator.com/ website as the target website that we want to scrape.
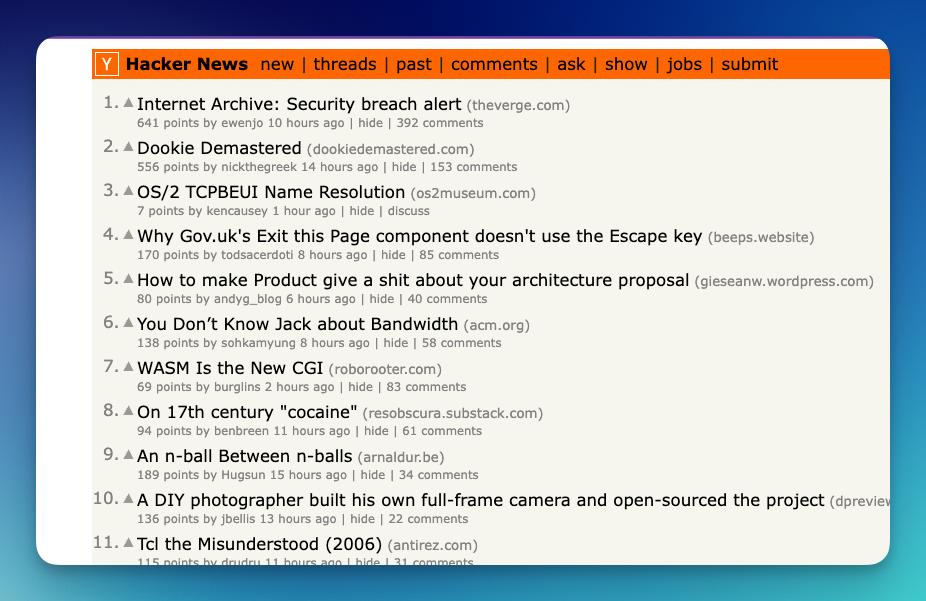
Inspect where this data is located
Let's assume we want to scrape the:
- title
- link
- visible link
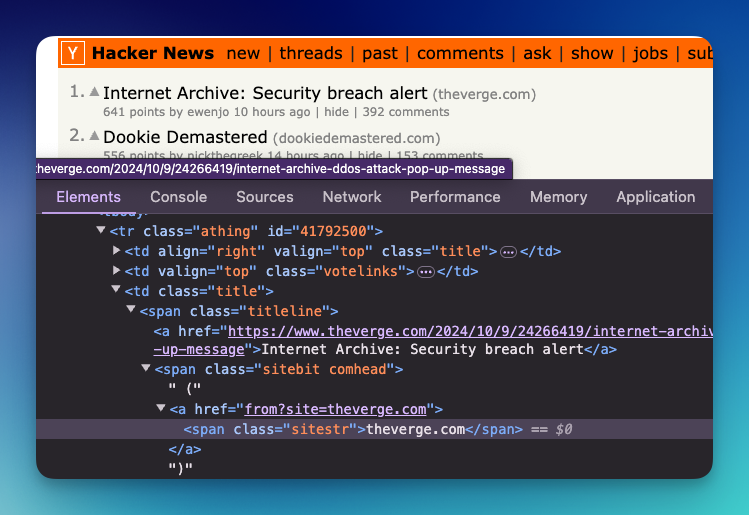
It looks like they are inside the athing class, and below titleline and sitestr classes.
The structure layout may change in the future. Please adjust your code accordingly.
Below, we'll look at how to scrape this website using different languages.
Web scraping using Python
Python has become the go-to language for web scraping. Python has a rich ecosystem of libraries and frameworks that make web scraping straightforward:
- Requests: Simplifies making HTTP requests to fetch web pages.
- Beautiful Soup: Makes it easy to parse and navigate HTML and XML documents.
- Selenium: Allows you to automate web browsers to scrape dynamic, JavaScript-rendered content.
- Scrapy: A powerful framework for large-scale web scraping with built-in handling for crawling, data extraction, and pipeline management.
These tools handle much of the heavy lifting, so you can focus on extracting the data you need. Let's practice with the first 2 tools.
We'll be using the Hackernews website for practice
1. Install Python and Necessary Libraries
First, you'll need to install Python on your computer. You can download it from the official website.
Next, install two essential libraries:
- Requests: To send HTTP requests and get the web page's HTML.
- Beautiful Soup: To parse and navigate the HTML content.
Open your command prompt or terminal and run:
pip install requests beautifulsoup4
2. Request the HTML Content
Create a new Python file called main.py and start by importing the requests library:
import requests
URL = 'https://news.ycombinator.com/'
response = requests.get(URL)
html_content = response.text
print(html_content)
This code sends a GET request to the URL and stores the HTML content in a variable.
3. Parse the Relevant Data
Now, let's parse the HTML to extract the data.
a. Import Beautiful Soup
Add the following import statement:
from bs4 import BeautifulSoup
b. Create a Soup Object
soup = BeautifulSoup(html_content, 'html.parser')
This creates a Beautiful Soup object that represents the parsed HTML document.
c. Extract title, link, and visible links
rows = soup.find_all('tr', class_='athing')
for row in rows:
titleline = row.find('span', class_='titleline')
link_tag = titleline.find('a', href=True)
title = link_tag.text
link = link_tag['href']
visible_link_tag = row.find('span', class_='sitestr')
# We add this condition to avoid an error when the visible_link_tag is None
visible_link = visible_link_tag.text if visible_link_tag else "No visible link"
print("Title:", title)
print("Link:", link)
print("Visible Link:", visible_link)
print('---')This loop goes through each thread.
4. Scrape Multiple Pages
The website has multiple pages. If we want to grab all the data, we must first find the pattern. In this case, this is what the patterns look like:
- Page 1: https://news.ycombinator.com/?p=1
- Page 2: https://news.ycombinator.com/?p=2
- Page n: https://news.ycombinator.com/?p=n
Let's modify the script to scrape the first three pages.
import requests
from bs4 import BeautifulSoup
URL = 'https://news.ycombinator.com/'
max_pages = 3 # I gave the limit to only 3 pages
for i in range(1, max_pages+1):
response = requests.get(f'{URL}?p={i}')
html_content = response.text
soup = BeautifulSoup(html_content, 'html.parser')
rows = soup.find_all('tr', class_='athing')
for row in rows:
titleline = row.find('span', class_='titleline')
link_tag = titleline.find('a', href=True)
title = link_tag.text
link = link_tag['href']
visible_link_tag = row.find('span', class_='sitestr')
visible_link = visible_link_tag.text if visible_link_tag else "No visible link"
print("Title:", title)
print("Link:", link)
print("Visible Link:", visible_link)
print('---')This script will continue to the next page until the 3rd page.
5. Save Data to a CSV File
You might want to save the data for later use. Let's save this example as a CSV file.
import requests
from bs4 import BeautifulSoup
import csv
URL = 'https://news.ycombinator.com/'
max_pages = 3
# Open a CSV file in write mode
with open('data.csv', mode='w', newline='') as file:
writer = csv.writer(file)
# Write the header row
writer.writerow(['Title', 'Link', 'Visible Link'])
for i in range(1, max_pages+1):
response = requests.get(f'{URL}?p={i}')
html_content = response.text
soup = BeautifulSoup(html_content, 'html.parser')
rows = soup.find_all('tr', class_='athing')
for row in rows:
titleline = row.find('span', class_='titleline')
link_tag = titleline.find('a', href=True)
title = link_tag.text
link = link_tag['href']
visible_link_tag = row.find('span', class_='sitestr')
visible_link = visible_link_tag.text if visible_link_tag else "No visible link"
# Write the data row to the CSV file
writer.writerow([title, link, visible_link])Now, running the script will create a data.csv file with all relevant data.
- Learn About CSS Selectors: Libraries like Beautiful Soup allow you to use CSS selectors to find elements.
- Scrape JavaScript-Rendered Content: Use tools like Selenium or Playwright for sites that load content dynamically.
- Build a Real Project: Think of a practical application for your scraper to solidify your learning.
- If you want to learn more, please read this Python for web scraping blog.
Useful Python Resources
Web scraping using Javascript
JavaScript isn't just for front-end development—it's also a powerful tool for web scraping. If you're already familiar with JavaScript or prefer using it over Python, you're in luck! JavaScript has a rich ecosystem of libraries and frameworks that make web scraping straightforward:
- Axios: Simplifies making HTTP requests to fetch web pages.
- Cheerio: This enables you to parse and navigate HTML and XML documents efficiently.
- Puppeteer: Allows you to control a headless Chrome browser to scrape dynamic, JavaScript-rendered content.
- Node.js: Provides a JavaScript runtime environment that lets you run JavaScript code outside of a browser.
These tools handle much of the heavy lifting, so you can focus on extracting the needed data. Let's practice with the first two tools.
We'll be using the Hackernews website for practice
1. Install Node.js and Necessary Libraries
First, you'll need Node.js installed on your computer. You can download it from the official website.
Next, install two essential libraries:
- Axios: To send HTTP requests and get the web page's HTML.
- Cheerio: To parse and navigate the HTML content.
Open your command prompt or terminal and run:
npm install axios cheerio
2. Request the HTML Content
Create a new JavaScript file called main.js and start by importing the axios library:
const axios = require('axios');
const URL = 'https://news.ycombinator.com/';
async function run() {
const response = await axios.get(`${URL}`);
console.log(response.data)
}
run()This code sends a GET request to the URL and logs the HTML content of the page.
3. Parse the Relevant Data
Now, let's parse the HTML to extract the data.
a. Import Cheerio
Add the following import statement:
const cheerio = require('cheerio');
b. Load and parse the data
const URL = 'https://news.ycombinator.com/';
async function run() {
const response = await axios.get(`${URL}`);
const htmlContent = response.data;
const $ = cheerio.load(htmlContent);
// Find all rows with the class 'athing'
$('tr.athing').each((_, element) => {
const titleElement = $(element).find('span.titleline a');
const title = titleElement.text();
const link = titleElement.attr('href');
const visibleLinkElement = $(element).find('span.sitestr');
const visibleLink = visibleLinkElement.length ? visibleLinkElement.text() : 'No visible link';
console.log({ title, link, visibleLink });
});
}
run()
This loop goes through each thread.
4. Scrape Multiple Pages
The website has multiple pages. If we want to grab all the data, we must first find the pattern. In this case, this is what the patterns look like:
- Page 1: https://news.ycombinator.com/?p=1
- Page 2: https://news.ycombinator.com/?p=2
- Page n: https://news.ycombinator.com/?p=n
Let's modify the script to scrape the first three pages.
const URL = 'https://news.ycombinator.com/';
const maxPages = 3;
async function run() {
for (let i = 1; i <= maxPages; i++) {
const response = await axios.get(`${URL}?p=${i}`);
const htmlContent = response.data;
const $ = cheerio.load(htmlContent);
// Find all rows with the class 'athing'
$('tr.athing').each((_, element) => {
const titleElement = $(element).find('span.titleline a');
const title = titleElement.text();
const link = titleElement.attr('href');
const visibleLinkElement = $(element).find('span.sitestr');
const visibleLink = visibleLinkElement.length ? visibleLinkElement.text() : 'No visible link';
console.log({ title, link, visibleLink });
});
}
}
run()5. Save Data to a CSV File
You might want to save the data for later use. Let's save this example in a CSV file.
const axios = require('axios');
const cheerio = require('cheerio');
const fs = require('fs');
const URL = 'https://news.ycombinator.com/';
const maxPages = 3;
const csvFile = 'data.csv';
const header = 'Title,Link,Visible Link\n';
fs.writeFileSync(csvFile, header);
async function run() {
for (let i = 1; i <= maxPages; i++) {
const response = await axios.get(`${URL}?p=${i}`);
const htmlContent = response.data;
const $ = cheerio.load(htmlContent);
// Find all rows with the class 'athing'
$('tr.athing').each((_, element) => {
const titleElement = $(element).find('span.titleline a');
const title = titleElement.text();
const link = titleElement.attr('href');
const visibleLinkElement = $(element).find('span.sitestr');
const visibleLink = visibleLinkElement.length ? visibleLinkElement.text() : 'No visible link';
// Append data to CSV file
const dataRow = `"${title}","${link}","${visibleLink}"\n`;
fs.appendFileSync(csvFile, dataRow);
});
}
}
run()
Now, running the script will create a data.csv file with all the relevant data.
Next Steps
- Learn About CSS Selectors: Cheerio supports jQuery-like selectors for finding elements.
- Scrape JavaScript-Rendered Content: Use tools like Puppeteer or Playwright for sites that load content dynamically.
- Build a Real Project: Think of a practical application for your scraper to solidify your learning.
- Learn more by reading this post: Web scraping using Javascript for beginner
Useful JavaScript Resources:
Web scraping using Ruby
Ruby is a dynamic, open-source programming language focusing on simplicity and productivity. It's known for its elegant syntax, which is natural to read and easy to write. If you're comfortable with Ruby or want to try it out for web scraping, you're in the right place! Ruby has powerful libraries that make web scraping straightforward:
- HTTParty: Simplifies making HTTP requests to fetch web pages.
- Nokogiri: A gem that makes it easy to parse and navigate HTML and XML documents.
- Selenium WebDriver: Allows you to automate web browsers to scrape dynamic, JavaScript-rendered content.
These tools handle much of the heavy lifting, so you can focus on extracting the data you need. Let's practice with the first two tools.
We'll be using the Hackernews website for practice
1. Install Ruby and Necessary Gems
First, you'll need Ruby installed on your computer. You can download it from the official website or use a version manager like rbenv or RVM.
Next, install two essential gems (Ruby libraries):
- HTTParty: To send HTTP requests and get the web page's HTML.
- Nokogiri: To parse and navigate the HTML content.
Open your command prompt or terminal and run:
gem install httparty nokogiri
2. Request the HTML Content
Create a new Ruby file called main.rb and start by requiring the httparty gem:
require 'httparty'
URL = 'https://news.ycombinator.com/'
response = HTTParty.get(URL)
html_content = response.body
puts html_content This code sends a GET request to the URL and stores the HTML content in a variable.
3. Parse the Relevant Data
Now, let's parse the HTML to extract the relevant data.
a. Require Nokogiri
Add the following required statement:
require 'nokogiri'
b. Parse the HTML with Nokogiri
Modify your code to parse the HTML content:
require 'httparty'
require 'nokogiri'
URL = 'https://news.ycombinator.com/'
response = HTTParty.get(URL)
html_content = response.body
doc = Nokogiri::HTML(html_content)
This creates a Nokogiri document that represents the parsed HTML.
c. Parse the data
Let's extract the title, link, and the visible link:
URL = 'https://news.ycombinator.com/'
response = HTTParty.get(URL)
html_content = response.body
parsed_page = Nokogiri::HTML(html_content)
rows = parsed_page.css('tr.athing')
rows.each do |row|
titleline = row.at_css('span.titleline a')
title = titleline.text
link = titleline['href']
visible_link_tag = row.at_css('span.sitestr')
visible_link = visible_link_tag ? visible_link_tag.text : 'No visible link'
print "#{title} , #{link}, (#{visible_link})\n"
end
This loop goes through each block.
4. Scrape Multiple Pages
The website has multiple pages. If we want to grab all the data, we must first find the pattern. In this case, this is what the patterns look like:
- Page 1: https://news.ycombinator.com/?p=1
- Page 2: https://news.ycombinator.com/?p=2
- Page n: https://news.ycombinator.com/?p=n
Let's modify the script to scrape the first three pages.
URL = 'https://news.ycombinator.com/'
max_pages = 3
(1..max_pages).each do |i|
response = HTTParty.get("#{URL}?p=#{i}")
html_content = response.body
parsed_page = Nokogiri::HTML(html_content)
rows = parsed_page.css('tr.athing')
rows.each do |row|
titleline = row.at_css('span.titleline a')
title = titleline.text
link = titleline['href']
visible_link_tag = row.at_css('span.sitestr')
visible_link = visible_link_tag ? visible_link_tag.text : 'No visible link'
print "#{title} , #{link}, (#{visible_link})\n"
end
endThis script will continue to the next page until the 3rd page.
5. Save Data to a CSV File
You might want to save the data for later use. Let's save this data in a CSV file.
require 'csv'
URL = 'https://news.ycombinator.com/'
max_pages = 3
# Open a CSV file in write mode
CSV.open('data.csv', 'w') do |csv|
# Write the header row
csv << ['Title', 'Link', 'Visible Link']
(1..max_pages).each do |i|
response = HTTParty.get("#{URL}?p=#{i}")
html_content = response.body
parsed_page = Nokogiri::HTML(html_content)
rows = parsed_page.css('tr.athing')
rows.each do |row|
titleline = row.at_css('span.titleline a')
title = titleline.text
link = titleline['href']
visible_link_tag = row.at_css('span.sitestr')
visible_link = visible_link_tag ? visible_link_tag.text : 'No visible link'
# Write the data row to the CSV file
csv << [title, link, visible_link]
end
end
end
puts 'Data successfully written to data.csv'Now, running the script will create a data.csv file with all relevant data inside.
Next Steps
- Learn About CSS Selectors: Nokogiri supports CSS selectors, which can make selecting elements more intuitive.
- Scrape JavaScript-Rendered Content: Use tools like Selenium WebDriver for sites that load content dynamically.
- Build a Real Project: Think of a practical application for your scraper to solidify your learning.
- Nokogiri Documentation
- HTTParty Documentation
Challenges in Web Scraping
Beyond fetching and parsing data, web scraping involves several additional challenges:
- Identifying Data Sources: Determining where and how data is stored can be complex. Websites may store data across different pages or load it via APIs, making it difficult to pinpoint the exact source.
- Handling Captchas: Websites often use CAPTCHAs to block automated access. Bypassing CAPTCHAs without violating terms of service requires sophisticated methods, such as using CAPTCHA-solving services, which adds cost and complexity.
- Managing IP Blocks and Rate Limits: Frequent requests from the same IP can lead to blocks or bans. Using proxies to rotate IPs and implementing smart throttling mechanisms can help mitigate this but require careful management and additional infrastructure.
- Legal and Ethical Considerations: Scraping must be done in compliance with laws and website terms of service. Ignoring these can lead to legal actions and ethical issues.
- Data Structure Changes: Websites often update their layout and structure, which can break scrapers. Regularly maintaining and updating scraping scripts is crucial to handle these changes.
You may interested in reading more tips and tricks on web scraping:
That's it! Thank you very much for reading this blog post. I hope you enjoyed it!