 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

Welcome to our quick guide on XPath selectors! XPath can help you pull specific information from websites. This post will explain the basics of XPath in easy-to-understand terms, giving you the tools to start scraping effectively.
What is XPath?
XPath stands for XML Path Language, a tool used to navigate through elements and attributes in an XML document. It allows you to query and select parts of an XML document, such as HTML pages, based on specific criteria, like an element's name, position, or content. This makes XPath very useful for tasks like web scraping, where you must extract particular information from web pages.
Want to learn how to scrape a website? Read the Beginner's guide to Web Scraping
XPath is used on several scraping tools, including:
The other option is to parse an HTML document using css selector. Use XPath over CSS selectors when you need to perform complex queries that involve navigating the DOM non-linearly.
Here is a guide on how to use CSS Selector for web scraping.
XPath Cheat Sheet
Here is the XPath Cheat Sheet for you:
Basic syntax for selecting nodes
/- Selects from the root node- Example:
/htmlselects the root<html>element of the document.
- Example:
//- Selects nodes from the current node that match the selection no matter where they are- Example:
//divselects all<div>elements throughout the entire document, regardless of their location.
- Example:
.- Selects the current node- Example: Suppose you are inside a loop processing
<div>elements, using.would select the current<div>element being processed.
- Example: Suppose you are inside a loop processing
..- Selects the parent of the current node- Example:
./..selects the parent of the current node. If you are currently on a<span>inside a<div>,./..would select the<div>.
- Example:
@- Selects attributes- Example:
//@hrefselects allhrefattributes of anchor tags<a>throughout the document.
- Example:
nodename- Selects all nodes with the name "nodename" / tagname- Example:
//pselects all<p>(paragraph) elements in the document.
- Example:
Each of these examples showcases how to use XPath selectors to target specific parts of an XML or HTML document effectively, each serving different needs in data extraction or document navigation.
Predicates - to refine your selection
[n]- Selects the nth element (1-based index)- Example:
//li[3]selects the third<li>element in any list on the document.
- Example:
[position() = n]- Same as above- Example:
//(ul/li)[position() = 2]selects the second<li>element within each<ul>element.
- Example:
[last()]- Selects the last element- Example:
//li[last()]selects the last<li>element within each list.
- Example:
[attribute = 'value']- Selects all elements with a given attribute value- Example:
//*[@id='uniqueElement']selects all elements with anidattribute equal to "uniqueElement".
- Example:
[contains(attribute, 'text')]- Selects elements with an attribute containing 'text'- Example:
//div[contains(@class, 'note')]selects all<div>elements whoseclassattribute contains the word "note".
- Example:
[not(predicate)]- Selects elements while excluding the predicate- Example:
//input[not(@type='hidden')]selects all<input>elements that do not have atypeattribute of "hidden".
- Example:
[starts-with(attribute, 'text')]- Selects elements where the attribute starts with 'text'- Example:
//a[starts-with(@href, 'http')]selects all<a>elements where thehrefattribute starts with "http".
- Example:
Axes
ancestor::- Selects all ancestors (parent, grandparent, etc.)- Example:
//span[@class='highlight']/ancestor::divselects all<div>ancestors of<span>elements with the class "highlight".
- Example:
descendant::- Selects all descendants (children, grandchildren, etc.)- Example:
//div[@id='content']/descendant::pselects all<p>elements that are descendants of the<div>element with the ID "content".
- Example:
following::- Selects everything in the document after the closing tag of the current node- Example:
//h2[@id='section1']/following::pselects all<p>elements in the document that come after an<h2>element with the ID "section1".
- Example:
preceding::- Selects all nodes that appear before the current node in the document- Example:
//h2[@id='section2']/preceding::pselects all<p>elements that appear before an<h2>element with the ID "section2".
- Example:
following-sibling::- Selects all siblings after the current node- Example:
//h2[@id='header']/following-sibling::divselects all<div>siblings that follow an<h2>element with the ID "header".
- Example:
preceding-sibling::- Selects all siblings before the current node- Example:
//h2[@id='header']/preceding-sibling::divselects all<div>siblings that precede an<h2>element with the ID "header".
- Example:
child::- Selects all direct children of the current node (additional useful axis)- Example:
//div[@class='container']/child::pselects all<p>elements that are direct children of<div>elements with the class "container".
- Example:
parent::- Selects the parent of the current node (to complete the navigation possibilities)- Example:
//span[@class='highlight']/parent::divselects the<div>parent of each<span>with the class "highlight".
- Example:
Wildcards
*- Matches any element node- Example:
//*selects all elements in the document. - Example:
/html/body/*selects all child elements of the<body>tag, regardless of their tag name.
- Example:
@*- Matches any attribute node- Example:
//@*selects all attributes of all elements in the document. - Example:
//div[@*]selects all<div>elements that have any attribute.
- Example:
node()- Matches any node of any kind- Example:
//body/node()selects all child nodes of the<body>tag, including elements, text nodes, and possibly others like comments. - Example:
//div/p/node()selects all child nodes of every<p>element that is a child of a<div>, encompassing text nodes, element nodes, and other types.
- Example:
Functions
text()- Selects the text content of nodes. Useful for cases where you want to extract only the text within an element.
Example: //p[text()='Hello World']contains()- Returns true if the first argument string contains the second argument string.
Example: //div[contains(@class, 'important')]starts-with()- Returns true if the first argument string starts with the second argument string.
Example: //div[starts-with(@id, 'prefix-')]not()- Returns true if the argument is false. This is useful for negating a condition.
Example: //input[not(@type='hidden')]normalize-space()- Strips leading and trailing whitespace from a string and replaces sequences of whitespace characters by a single space. This is useful in cleaning up text.
Example: //td[normalize-space(text())='Some text']translate()- Replaces characters in a string. This is useful for case-insensitive searching or removing specific characters.
Example: //text()[translate(., 'ABC', 'abc')='abc']last()- Returns the position of the last node in the context node list. Useful for selecting the last item in a list or a series of elements.
Example: //(ul/li)[last()]position()- Returns the position of the current node in the context node list.
Example: //(ul/li)[position() <= 3]count()- Counts the number of nodes in the argument node-set.
Example: //ul[count(li) > 3]sum()- Returns the sum of the values of the nodes in the argument node-set.
Example: sum(//input[@type='number']/@value)floor(), ceil(), and round()- Numeric functions to round numbers down, up, or to the nearest integer, respectively.
Example: //div[floor(@data-number) = 10]boolean()- Converts the argument to a boolean value, where strings and numbers are true unless the string is empty or the number is zero.
Example: //div[boolean(@attribute)]
Selecting Specific Nodes
- By Tag Name:
//tagname- Selects all nodes with the nametagname
- By Attribute:
//*[@attribute='value']- Selects all elements that have the specified attribute with a certain value
- By Partial Attribute:
//*[contains(@attribute, 'value')]- Selects elements that contain the specified value in the specified attribute
Time to practice
We can start practicing by using the browser console function $x() . It's available on Chrome and Firefox.
Right click > Inspect, and switch to console tab
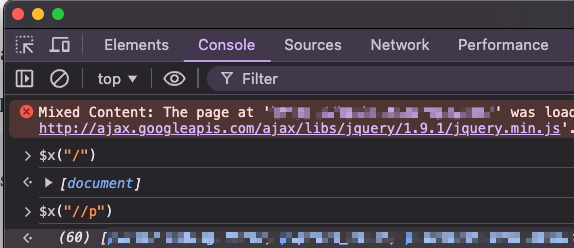
You can explore any website you like; I'll be using the serpapi.com website.
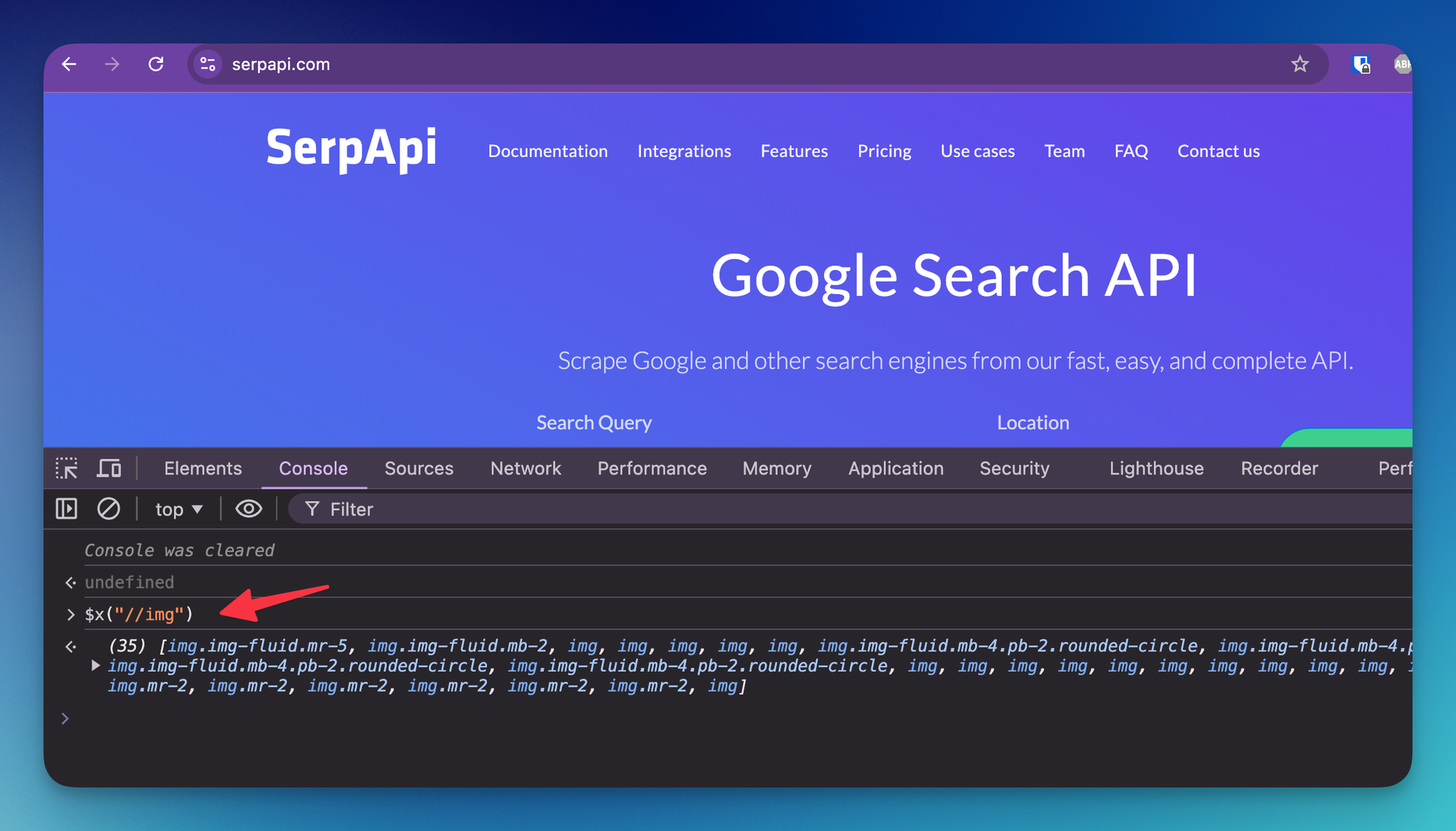
Find all images using XPath
//img , wrapped in a double quote and $x function-> $x("//img")
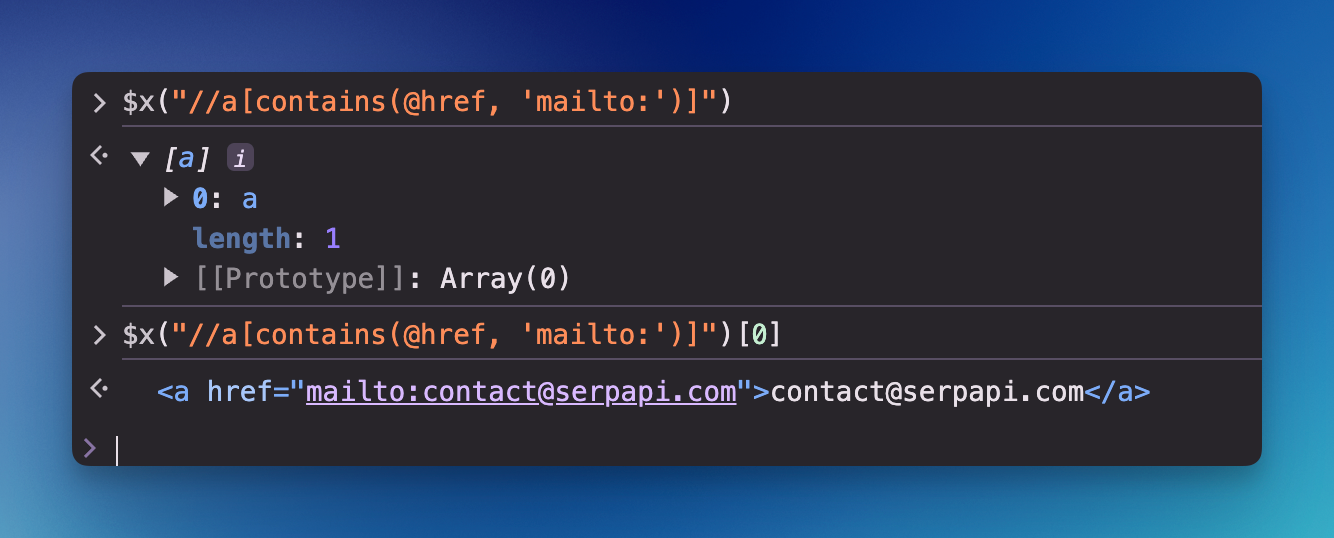
Find emails with XPath
Let's find emails on a page. We're using a tag link that contains href attribute with mailto an attribute as a sign for email. You can look at each of the selected elements using the array order; in this case, we only got 1, so we're using [0] to retrieve the first result.
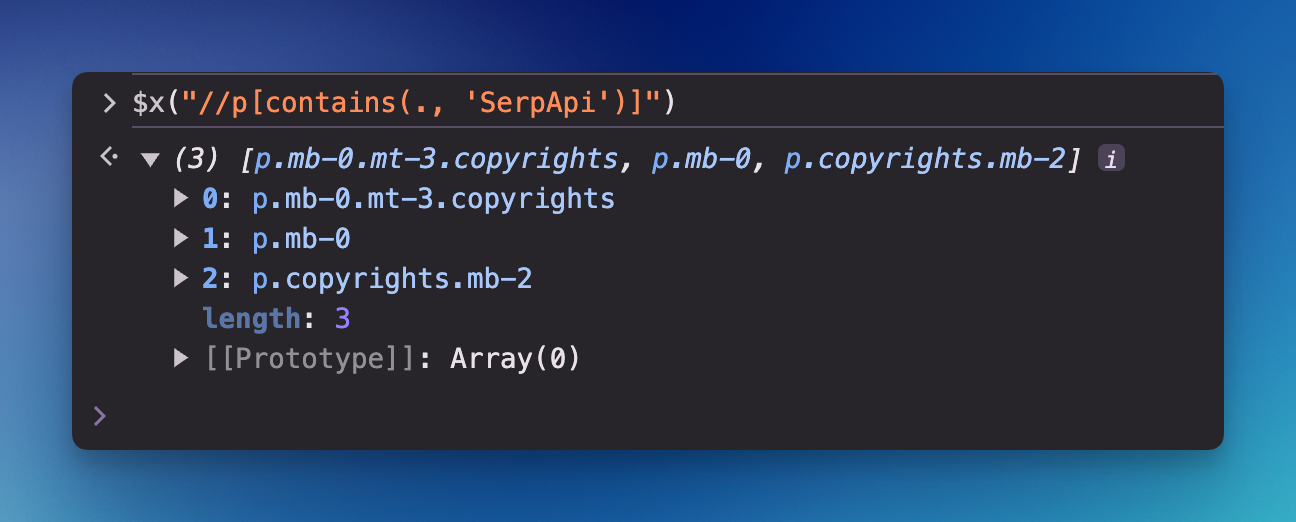
Find paragraphs that contain certain text
We can use the function to search for a keyword. In the first parameter, we use a dot sign . to search on the root or search anywhere in this case. The second parameter is the keyword we're looking for.
FAQs around XPath
- How can I use XPath to select elements based on text content?
To select elements based on their text content, you can use thetext()function in combination with thecontains()function. For example, the XPath expression//p[contains(text(), 'important')]selects all<p>elements that contain the word "important" in their text. - How can I use XPath to select siblings of a specific element?
XPath provides functions to select siblings of an element. To select all following siblings of an element, you can use thefollowing-sibling::axis. For example,//h2[@id='intro']/following-sibling::pwould select all<p>paragraph elements that follow an<h2>element with the id 'intro'. To select preceding siblings, use thepreceding-sibling::axis, such as//div[@id='footer']/preceding-sibling::divto select all<div>elements that precede a<div>with the id 'footer'. - How do you select attributes with XPath?
Attributes can be selected by using the@symbol followed by the attribute name. For instance, to select thehrefattribute of all anchor tags in a document, you would use the XPath//a/@href. This is useful for extracting specific attribute values from elements. - Can XPath be used to select elements that do not contain specific text?
Yes, XPath allows you to select elements that do not contain specific text using thenot()function along withcontains(). For example,//div[not(contains(text(), 'exclude'))]would select all<div>elements that do not contain the text "exclude". - How can I use XPath to select a specific element when there are multiple similar elements?
You can refine your selection using predicates, including position or specific attribute values. For example, if you want to select the second<li>element from a list, you could use//ul/li[2]. Alternatively, if you need to select an element based on a unique attribute, you could use something like//input[@type='submit' and @value='Search']selecting an input element specifically with the type 'submit' and value 'Search'.
Reference:
w3 - XML Path language