 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 C++
C++

Sometimes, you see truncated text on a Google search result like this (...) . Google doesn't always display the meta description of a website. Sometimes, it gets a snippet of relevant text to the search query, which could truncate the text.
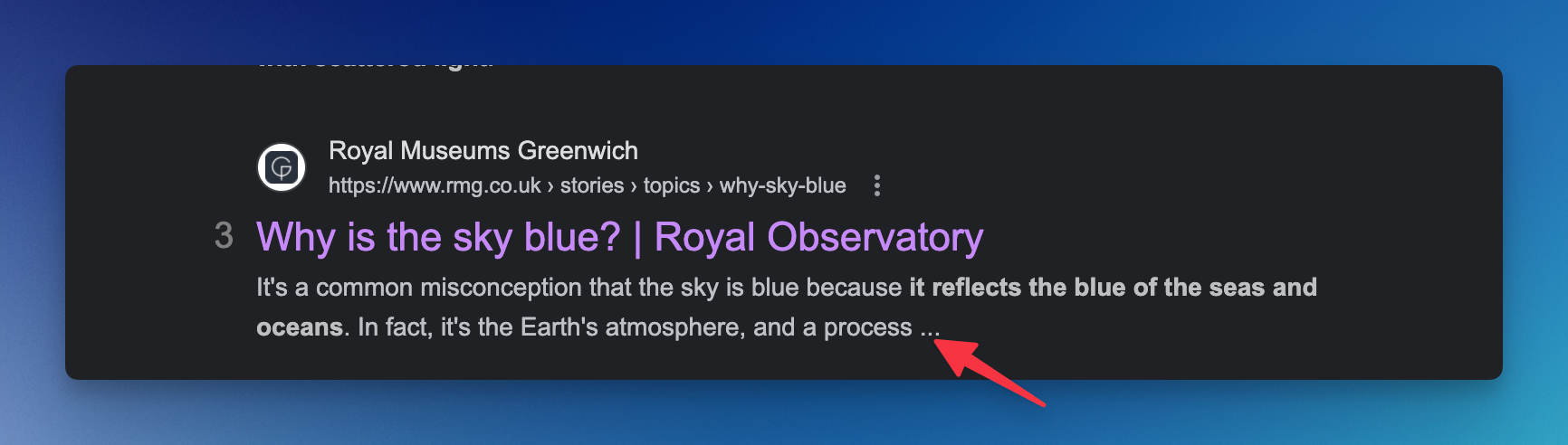
Wonder how you can get the entire snippet of this search result? Let's dive in!
The Idea
The idea is to visit the page URL and scrape part of the relevant text until the next period sign or the whole paragraph.
But before that, we need to find the Google search results list. Therefore, we will use Google search API by SerpApi to scrape the Google SERP.
You can use any programming language you want, but I'll use Go Lang for this sample.

Scraping Google SERP list with Go lang
First, let's get the Google organic results.
Step 1:
Get your SerpApi key
Step 2:
Create a new Go Lang project
mkdir fullsnippet && cd fullsnippet // Create a new folder and move
touch main.go // Create a new go fileStep 3:
Install Golang SerpApi package
go mod init project-snippet // Initialize Go Module
go get -u github.com/serpapi/serpapi-golang // Install Go lang package by SerpApiStep 4:
This is how to get the organic_results from Google SERP
package main
import (
"fmt"
"github.com/serpapi/serpapi-golang"
)
const API_KEY = "YOUR_API_KEY"
func main() {
client_parameter := map[string]string{
"engine": "google",
"api_key": API_KEY,
}
client := serpapi.NewClient(client_parameter)
parameter := map[string]string{
"q": "why the sky is blue", // Feel free to change with any keyword
}
data, err := client.Search(parameter)
fmt.Println(data["organic_results"])
if err != nil {
fmt.Println(err)
}
}We've received each result's title, description, link, and other information.
Collect only specific data
We can collect and display only specific data in a variable like this
data, err := client.Search(parameter)
type OrganicResult struct {
Title string
Snippet string
Link string
}
var organic_results []OrganicResult
for _, result := range data["organic_results"].([]interface{}) {
result := result.(map[string]interface{})
organic_result := OrganicResult{
Title: result["title"].(string),
Snippet: result["snippet"].(string),
Link: result["link"].(string),
}
organic_results = append(organic_results, organic_result)
}
Scraping the individual page
SerpApi focuses on scraping search results. That's why we need extra help to scrape individual sites. We'll use GoColly package.
Install package
go get -u github.com/gocolly/colly/v2Code for scraping individual site
Add this code inside the loop
// Scrape each of the link
c := colly.NewCollector()
c.OnHTML("body", func(e *colly.HTMLElement) {
rawText := e.Text
fmt.Println("Raw text in entire body tag:", rawText)
})
// Handle any errors
c.OnError(func(r *colly.Response, err error) {
fmt.Println("Request URL:", r.Request.URL, "failed with response:", r, "\nError:", err)
})
// Start scraping
c.Visit(organic_result.Link)If you need the whole text of each site, you can return the rawText from above. Then you're done.
But if you need only the snippet part until the next period (the entire sentence), we will continue to the following function.
Scraping only the relevant text
Here's the pseudocode on returning only the relevant full snippet.
Find $partialSnippet in the rawText
Find the position of $partialSnippet
Find the next (closest) period after that partial snippet
Return the whole snippetHere is the Go Lang code:
fullSnippet := findSentence(rawText, snippet)
return fullSnippetThe findSentence method:
func findSentence(rawText string, searchText string) string {
// 1. Replace all whitespaces with a single space
re := regexp.MustCompile(`\s+`)
fullText := re.ReplaceAllString(rawText, " ")
// 2. Replace all backtik ’ into ' at rawText
re1 := regexp.MustCompile(`’`)
fullText = re1.ReplaceAllString(fullText, "'")
// 3. Find the start index of searchText
startIndex := strings.Index(fullText, searchText)
if startIndex == -1 {
return "Text not found"
}
// 4. Calculate the end index of the snippet
snippetEndIndex := startIndex + len(searchText)
// 5. Find the end of the sentence after the snippet
endOfSentenceIndex := strings.Index(fullText[snippetEndIndex:], ".")
if endOfSentenceIndex == -1 {
// Return the rest of the text from snippet if not found
return fullText[startIndex:]
}
// Adjust to get the correct index in the full text
endOfSentenceIndex += snippetEndIndex + 1
return fullText[startIndex:endOfSentenceIndex]
}Here is the result:
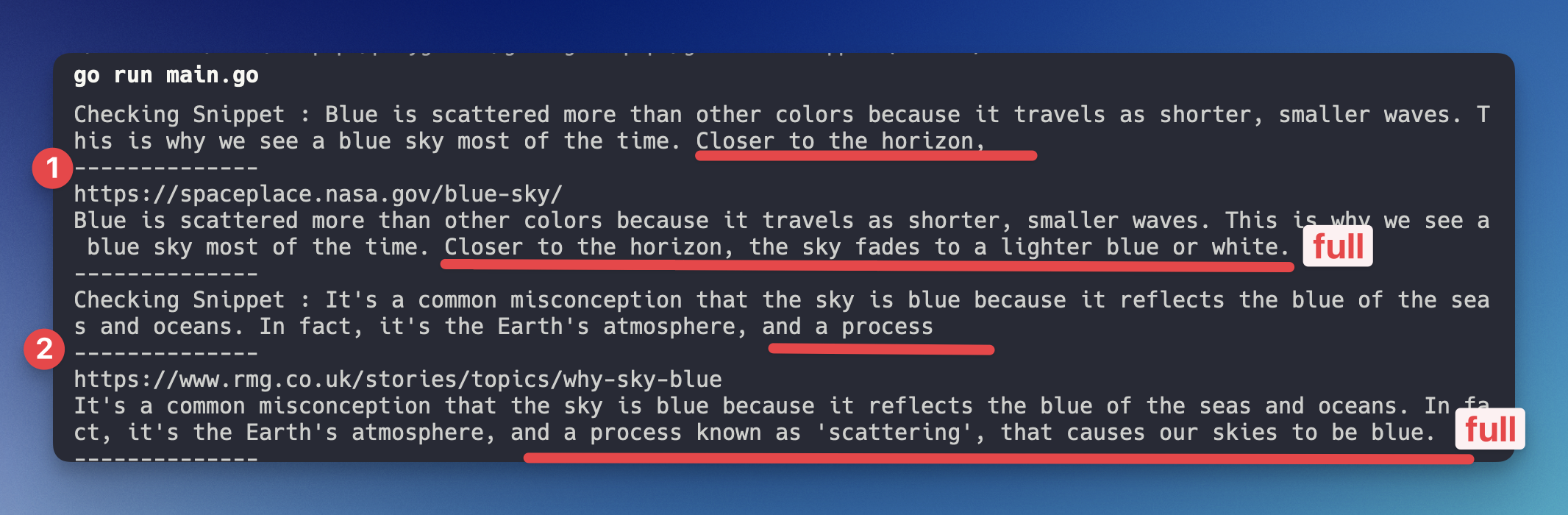
You can create a conditional logic (if statement) to only perform this when the snippet has "..." (three dots in the end).
Full code sample
Here is the full code sample in GitHub: https://github.com/hilmanski/serpapi-fullsnippet-golang
Warning
Here are a few potential issues and solutions with our method.
Different snippet format
This might not work when Google displays a snippet list, where the snippet comes from some headings or key points. We'll need to write a different logic for this.
Adding proxy
To prevent getting blocked when scraping the individual site, you can add proxies to the GoColly.
As a reminder, You don't need to worry about getting blocked for scraping the Google search itself when using SerpApi.
Reference: https://go-colly.org/docs/examples/proxy_switcher/
Sample proxy switcher
package main
import (
"bytes"
"log"
"github.com/gocolly/colly"
"github.com/gocolly/colly/proxy"
)
func main() {
// Instantiate default collector
c := colly.NewCollector(colly.AllowURLRevisit())
// Rotate two socks5 proxies
rp, err := proxy.RoundRobinProxySwitcher("socks5://127.0.0.1:1337", "socks5://127.0.0.1:1338")
if err != nil {
log.Fatal(err)
}
c.SetProxyFunc(rp)
// Print the response
c.OnResponse(func(r *colly.Response) {
log.Printf("%s\n", bytes.Replace(r.Body, []byte("\n"), nil, -1))
})
// Fetch httpbin.org/ip five times
for i := 0; i < 5; i++ {
c.Visit("https://httpbin.org/ip")
}
}I hope it helps you to collect more data for your Google SERP!