Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

SerpApi streamlines the process of web-scraping and helps you retrieve live data from Google and most major search engines. Whether you need to track rankings, monitor competitor strategies, or analyze search trends, SerpApi provides a structured JSON output of search engine results. Combining SerpApi with the robust features of Amazon Web Services (AWS) provides a scalable and cost-effective solution for businesses wanting to use AWS features like Lambda to make SerpApi requests.
In this blog post, let's dive into the specifics of how to start using our Google Search API within AWS.
An Overview of Steps to Start Using SerpApi within AWS
- Create your SerpApi account (if you don't have one already)
- Create your AWS Account (if you don't have one already)
- Create and deploy an AWS Lambda Function to use our Google Search API
- Use our API with a simple GET request
- Use our API with our python library
google-search-results
- Store response data with AWS DynamoDB
Create Your SerpApi account
To get started with SerpApi, you'll need to create an account on their platform and obtain an API key. This key will be required for making requests to the SerpApi endpoints.
- Visit SerpApi's website and sign up.
- Once your account is registered, you can navigate to the Manage API key page to find your API key: https://serpapi.com/manage-api-key
You'll need this key for authentication when making requests.
Create your AWS Account
Navigate to the AWS website: https://aws.amazon.com/
Click on the "Create an AWS Account" button: You’ll typically find it at the top right corner of the page.
After entering all the required details, you can pick the support plan which is right for you - AWS offers several support plans, but the Basic Support Plan is free and provides you with 24/7 access to documentation, whitepapers, and community forums. For most users, the Basic Support plan will be sufficient at the beginning.
After account setup, you’ll be redirected to the AWS Management Console. This is your central hub for managing all AWS services.
Create and Deploy AWS Lambda Function
AWS Lambda is a serverless compute service that allows you to run code without provisioning or managing servers. It is ideal for automating API calls, and you can easily use any of our APIs using a programming language of your choice.
First, Open the AWS Lambda Console and create a new function. Choose a runtime that suits your programming language preference (e.g., Python, Node.js).
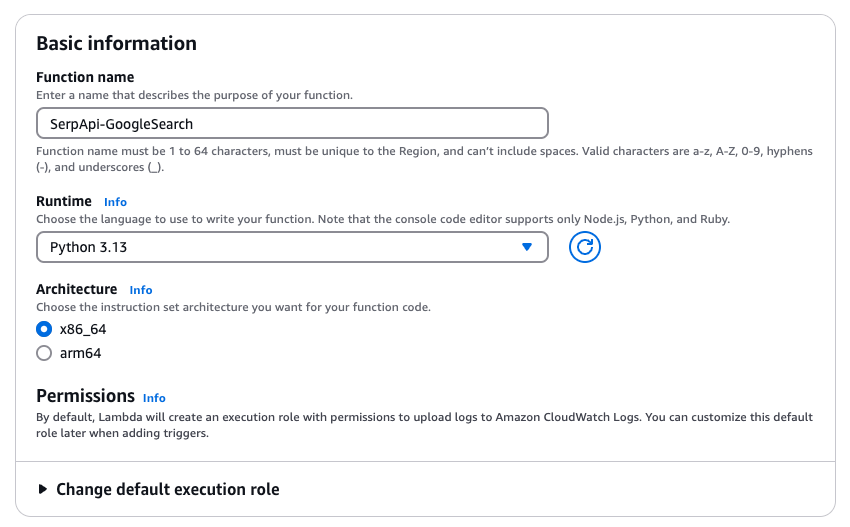
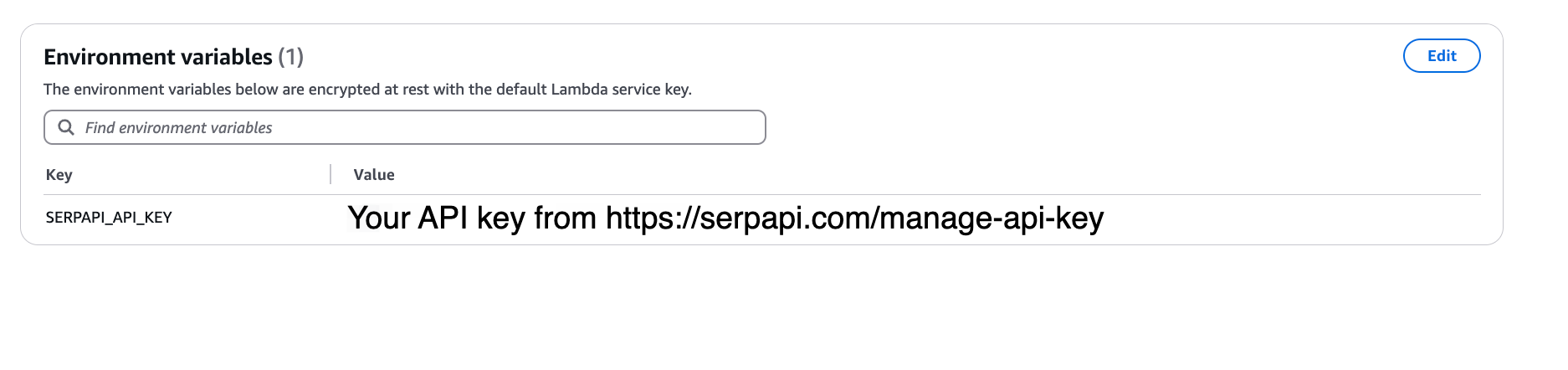
Let's add our SerpApi API key as an environment variable so we can access it in our code as needed. Head over to Configuration -> Environ
Next, we will add code to our Lambda function to scrape Google Search results. In this tutorial, we are going to use Python. I'll mention a simple example using a simple GET request, and another example using our python library google-search-results.
Our Goal: we want to extract the links of all the results appearing on the first page for the query: "Are fruits healthy?" on Google Search.
Use our API with a simple GET request
First, let's explore how to do this using a simple GET request using Python's urllib3 library.
To extract the links of all the results appearing on the first page of result for the query: "Are fruits healthy?" on Google Search, I'm using our Google Search API. This is what the code looks like:
import json, os
import urllib3
def lambda_handler(event, context):
api_key = os.environ.get('SERPAPI_API_KEY')
http = urllib3.PoolManager()
url = f"https://serpapi.com/search.json?engine=google&q=Are+fruits+healthy%3F&location=Austin%2C+Texas%2C+United+States&google_domain=google.com&gl=us&hl=en&google_domain=google.com&api_key={api_key}"
response = http.request('GET', url)
response_dict = json.loads(response.data.decode('utf-8'))
# Extract organic results
organic_results = response_dict.get("organic_results", [])
links = []
for result in organic_results:
links.append(result["link"])
return {
'statusCode': 200,
'body': links
}You can modify this code depending on the part of the output you are interested in.
I've shared results from running this code under the "Deploy and Test Your Lambda Function" section in this post.
Use our API with our python library google-search-results
Now, let's see how we can accomplish the same goal using SerpApi's Python integration - our python library google-search-results.
More Information About Our Python Libraries
We have two separate Python libraries serpapi and google-search-results, and both work perfectly fine. However, serpapi is a new one, and all the examples you can find on our website are from the old one google-search-results. If you'd like to use our Python library with all the examples from our website, you should install the google-search-results module instead of serpapi.
For this blog post, I am using google-search-results because all of our documentation references this one.
You may encounter issues if you have both libraries installed at the same time. If you have the old library installed and want to proceed with using our new library, please follow these steps:
- Uninstall
google-search-resultsmodule from your environment. - Make sure that neither
serpapinorgoogle-search-resultsare installed at that stage. - Install
serpapimodule, for example with the following command if you're usingpip:pip install serpapi
There is a bit of setup to do the first time you use our google-search-results python library with AWS Lambda. To use this library with AWS Lambda, you would need to create a layer within your lambda function. What this means is that you will package the library and its dependencies into a Lambda Layer, which is a distribution mechanism for libraries, custom runtimes, and other function dependencies. This allows you to separate the library from your function code, making it reusable and easier to manage. To do this, you need to create a .zip file with all the dependencies and upload that to create a Lambda Layer. These are the steps you need to follow to make this happen:
- Have your desired version of Python installed locally
❯ python3 --version
Python 3.12.2
- Create a folder for the package and cd into it
mkdir py_packages
cd py_packages
- Create a virtual Env
python3 -m venv venv
source venv/bin/activate
- Create a python folder. This is the folder which is going to have all the files.
mkdir python
cd python
- Install the
google-search-resultspackage.
pip install google-search-results -t .
- Let's save space and delete objects with the ".dis-info" and the "venv" folders. They are not needed.
rm -rf *dist-info
rm -rf venv
- Zip the folder to upload to aws lambda layer
cd ..
zip -r requests-package.zip pythonOnce you have this .zip file ready, you can head over to the Layers tab on the left panel on the Lambda page and select "Create a new layer".
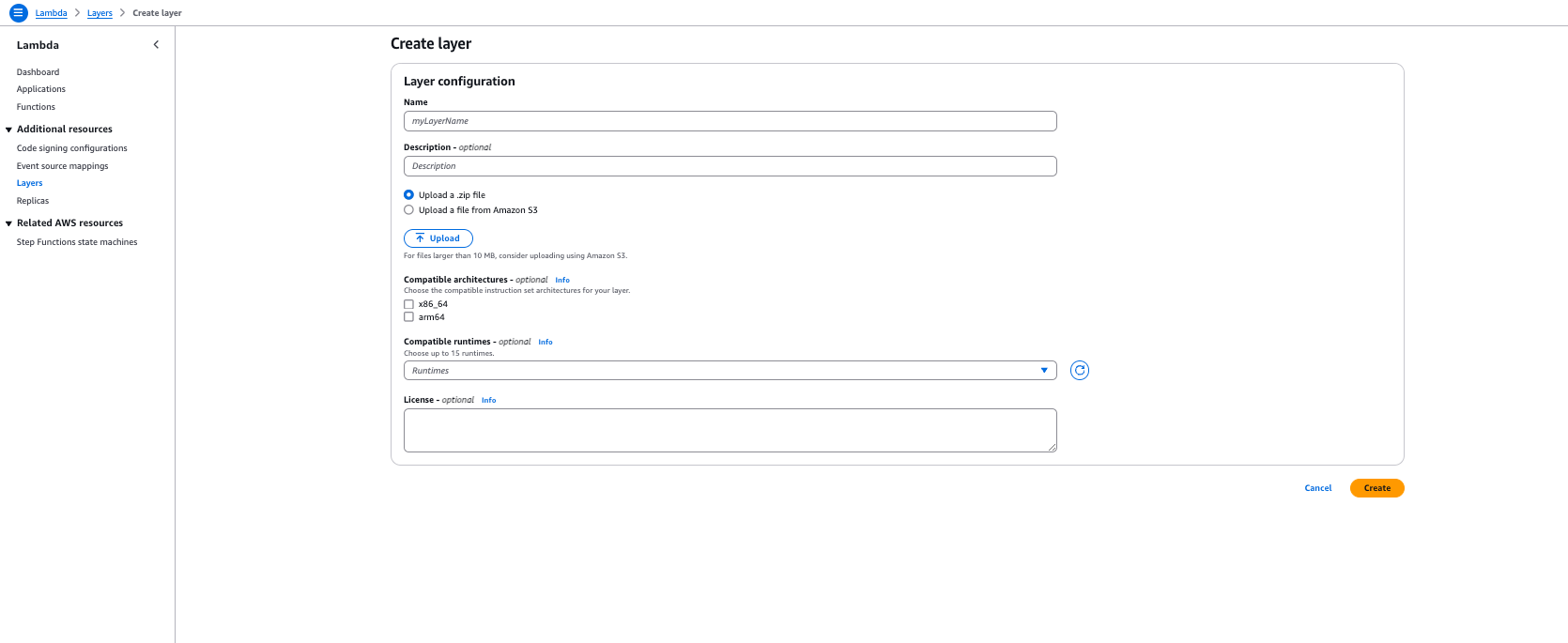
This is what the layer creation will look like:
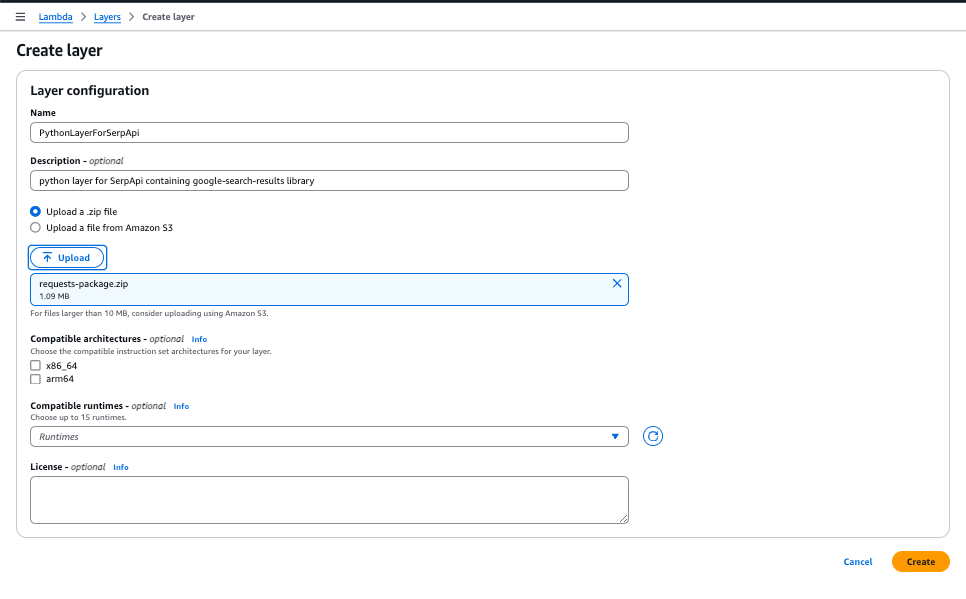
Copy the ARN of the layer that is created. Following that, we can add this layer to the Lambda function we created.
Head over to the Lambda function you defined, and scroll down to a section called Layers, and select "Add a layer". It looks like this:

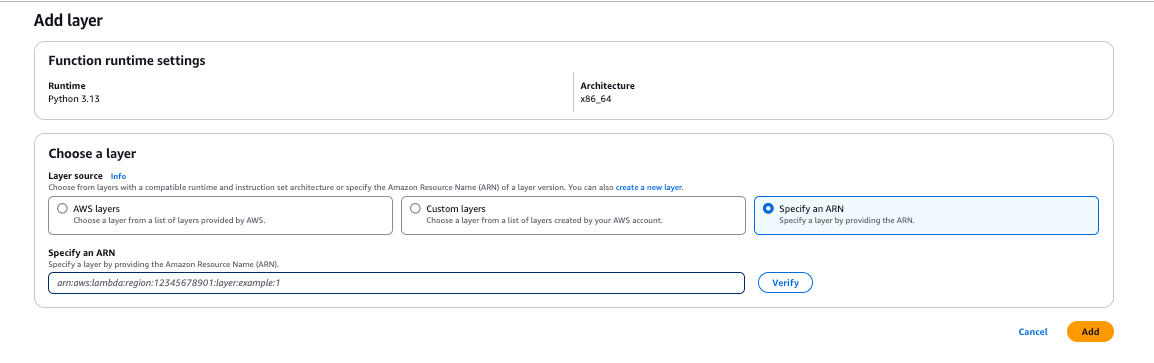
Then, select the "Specify an ARN option" and paste the ARN of the layer you created. Click Add, and it's all ready to use.
Now, we can write the code using the google-search-results python library.
To extract the links of all the results appearing on the first page of result for the query: "Are fruits healthy?" on Google Search, I'm using our Google Search API. This is what the code looks like:
import json, os
from serpapi import GoogleSearch
def lambda_handler(event, context):
params = {
"q": "Are fruits healthy?",
"api_key": os.environ.get('SERPAPI_API_KEY')
}
search = GoogleSearch(params)
results = search.get_dict()
organic_results = results["organic_results"]
links = []
for result in organic_results:
links.append(result["link"])
return {
'statusCode': 200,
'body': links
}You can modify this code depending on the part of the output you are interested in.
Deploy and Test Your Lambda Function
Once you are ready to run the code, click "Deploy", and then click "Test".
Following that, when you test your Lambda function, you should see an output like this:
{
"statusCode": 200,
"body": [
"https://www.webmd.com/diet/how-much-fruit-is-too-much",
"https://www.healthline.com/nutrition/is-fruit-good-or-bad-for-your-health",
"https://www.medicalnewstoday.com/articles/324431",
"https://www.myplate.gov/eat-healthy/fruits",
"https://www.afmc.af.mil/News/Article-Display/Article/3869551/health-benefits-of-eating-more-fruits-and-vegetables/",
"https://www.nhs.uk/live-well/eat-well/5-a-day/why-5-a-day/",
"https://nutritionsource.hsph.harvard.edu/what-should-you-eat/vegetables-and-fruits/",
"https://www.reddit.com/r/nutrition/comments/7dkbgq/is_fruit_really_as_healthy_as_it_is_made_out_to/",
"https://www.betterhealth.vic.gov.au/health/healthyliving/fruit-and-vegetables"
]
}Here we have links from all the results appearing on the first page for the query: "Are fruits healthy?" on Google Search.
Add the Results to a DynamoDB Table
Now, let's say we want to save these results to a database, like DynamoDB. In that case, you can create a DynamoDB table, let's call it SearchResults, and set a partition_key like search_id (String). Then we can return to the Lambda function, and modify the code to store the list of links in the table as an entry, along with the search_id and the timestamp. This would look something like this:
import json, os
from serpapi import GoogleSearch
import boto3
from datetime import datetime
def lambda_handler(event, context):
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('SearchResults')
params = {
"q": "Are fruits healthy?",
"api_key": os.environ.get('SERPAPI_API_KEY')
}
search = GoogleSearch(params)
results = search.get_dict()
organic_results = results["organic_results"]
links = []
for result in organic_results:
links.append(result["link"])
table.put_item(
Item={
'search_id': results["search_metadata"]["id"],
'timestamp': datetime.now().isoformat(timespec='seconds'),
'links': json.dumps(links)
}
)
return {
'statusCode': 200,
'body': links
}
table.put_item function to work, we need to add permissions to our DynamoDB table to accept a call from our Lambda function. This can be done by heading over the the DynamoDB table, and adding the permission (under Resource-based policy for table) it asks you to add in the error message. In my case, I had to add this permission to allow all operations on my table from my Lambda: { "Version": "2012-10-17", "Statement": [ { "Sid": "1111", "Effect": "Allow", "Principal": { "AWS": "arn:aws:sts::<Account ID>:assumed-role/SerpApiGoogleSearch-role-5o8squva/SerpApiGoogleSearch" }, "Action": "dynamodb:*", "Resource": "arn:aws:dynamodb:us-east-2:<Account ID>:table/SearchResults" } ] }After a successful run, you will be able to see an entry added to the table. It looks like this:

Conclusion
And, that's it - you've successfully set up your Lambda function to scrape data from Google Search results and add it to a DynamoDB table at the click of a button!
Integrating SerpApi with the AWS ecosystem unlocks powerful capabilities for automating search results collection, processing, and analysis. Here at SerpApi, we perform web scraping on search engines and provide that data to you in a JSON format. The API calls replicate real-time searches, and you can get all this data seamlessly in AWS.
If you haven't used SerpApi before, create a free account on serpapi.com. You'll receive one hundred free search credits each month to explore the API. For usage requirements beyond that, you can view all our plans here after logging in: https://serpapi.com/change-plan.
I hope this blog post was helpful in understanding how to scrape Google search results using SerpApi and AWS. If you have any questions, don't hesitate to reach out to me at sonika@serpapi.com.
Relevant Posts
You may be interested in reading more about our Google Search API, and other integrations we have.