 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 C++
C++

Hi everyone! Ever wondered why your Python scripts using requests sometimes run into blocks, errors, or just don’t work as intended? That’s because many websites have protections in place to limit automated requests, detect suspicious activity, or enforce region-specific restrictions.

Why do you need a proxy?
Without a proxy, your script might be flagged, blocked, or unable to access certain content altogether.
But don’t worry—proxies are here to help! Let’s explore how to use a proxy on your Python requests.
We'll learn how to:
- use a proxy on Python requests
- use a proxy with user authentication
- use rotating proxies
- use a proxy with session
How to use Python Requests with a proxy
Here’s a step-by-step tutorial on how to use Python’s requests library with a proxy:
Step 1: Install the requests Library
Make sure you have the requests library installed. If not, install it using pip:
pip install requests
Step 2: Choose Your Proxy
You’ll need a proxy server. You can:
1. Find a Free Proxy: Some providers offer a limited free proxy. You can try to google "free proxy."
Using free proxies has a bigger chance of being blocked than a paid one. So, it's not recommended.
2. Use a Paid Proxy: Paid proxies are more reliable, faster, and secure.
Step 3: Define Your Proxy
Proxies can be set up for HTTP and HTTPS requests, but you aren't required to use both. In Python, this is done using a dictionary.
proxies = {
"http": "http://your-proxy-ip:port",
"https": "https://your-proxy-ip:port",
}Replace your-proxy-ip:port with the actual IP address and port of your proxy server. For example:
proxies = {
"http": "http://123.45.67.89:8080",
"https": "https://123.45.67.89:8080",
}Don't try to use that proxy; it's just an example.
Official Requests documentation on Proxy: https://requests.readthedocs.io/en/latest/user/advanced/#proxies
Step 4: Test the Proxy
Use the proxy with the requests.get method to test if it works:
import requests
proxies = {
"http": "http://123.45.67.89:8080",
"https": "https://123.45.67.89:8080",
}
try:
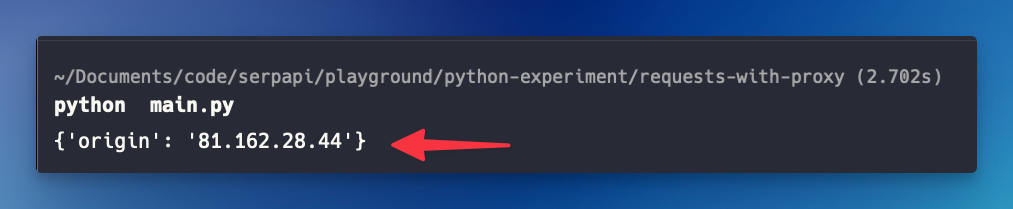
response = requests.get("https://httpbin.org/ip", proxies=proxies)
print(response.json()) # This should return the proxy's IP
except requests.exceptions.ProxyError as e:
print("Proxy error:", e)
If successful, the output will show the proxy IP address instead of your local IP.
Step 5: Use Proxies with Authentication (Optional)
Some proxies require a username and password. In that case, include the credentials in the proxy URL:
proxies = {
"https": "https://username:password@proxy-ip:port",
}Example:
proxies = {
"https": "https://user123:pass123@123.45.67.89:8080",
}
Step 6: Rotate Proxies (Optional)
Using the same proxy can risk your proxy being flagged and eventually getting blocked by the website. To avoid getting blocked, you can rotate proxies by randomly selecting one from a list:
import requests
import random
proxy_list = [
"https://123.45.67.89:8080",
"https://98.76.54.32:8080",
]
proxies = {
"https": random.choice(proxy_list),
}
response = requests.get("https://httpbin.org/ip", proxies=proxies)
print(response.json())
Step 7: Handle Proxy Errors Gracefully
Proxies might fail or be blocked. Just like a regular program, ensure to log your request properly to debug it later.
Handle exceptions to avoid crashes:
try:
response = requests.get("https://example.com", proxies=proxies, timeout=5)
print(response.status_code)
except requests.exceptions.ProxyError:
print("Failed to connect to the proxy.")
except requests.exceptions.ConnectTimeout:
print("Proxy timed out.")
Step 8: Use a proxy with session
You can enhance your web scraping effort by combining proxies with a requests.Session method for improved performance, persistent connections, and seamless handling of state across multiple requests. By reusing connections, you can keep things like cookies and settings consistent across requests.
import requests
proxies = {
'https': 'http://10.10.1.10:1080',
}
session = requests.Session()
session.proxies.update(proxies)
session.get('http://example.org')Step 9: Use a Proxy with Advanced Requests
You can also use proxies with POST, PUT, or other HTTP methods:
data = {"key": "value"}
response = requests.post("https://example.com/api", data=data, proxies=proxies)
print(response.text)
Possible error when not using a Proxy
When performing HTTP requests in Python using the requests library without a proxy, you might encounter several types of errors depending on the specific scenario. Here are some common ones:
1. Blocked by the Server
- If the server you're trying to access has security mechanisms (like rate limiting, geographic restrictions, or IP bans), you might get responses like:
403 Forbidden: The server is rejecting your request.429 Too Many Requests: You are sending too many requests in a short period.
2. Connection Errors
- If the server restricts access based on IP or geographical location:
requests.exceptions.ConnectionError: Indicates that the connection could not be established.
3. Timeouts
- If the server is slow to respond, or your IP is throttled:
requests.exceptions.Timeout: Raised when a request exceeds the specified timeout duration.
4. DNS Resolution Issues
- If your local DNS can't resolve the server's domain:
requests.exceptions.ConnectionErrorwith a message about DNS failure.
5. Captchas or Bot Detection
- Some websites employ CAPTCHAs or bot-detection systems, leading to responses with:
- HTML for a CAPTCHA challenge (usually requires analysis of the response content to detect).
6. IP-Based Rate Limiting
- Without proxies, all requests originate from your local IP address. High traffic might lead to:
- Temporary or permanent IP bans.
- Slower response times from the server.
7. SSL Verification Errors
- If the server requires specific SSL configurations:
requests.exceptions.SSLError: Indicates SSL handshake failures.
Example Error Handling Code
Here's how you can handle common errors when using the requests library:
import requests
try:
response = requests.get("https://example.com", timeout=5)
response.raise_for_status() # Raise HTTPError for bad responses (4xx, 5xx)
except requests.exceptions.HTTPError as e:
print(f"HTTP error occurred: {e}")
except requests.exceptions.ConnectionError as e:
print(f"Connection error occurred: {e}")
except requests.exceptions.Timeout as e:
print(f"Timeout occurred: {e}")
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")
More error exceptions on requests: https://requests.readthedocs.io/en/latest/_modules/requests/exceptions/
On top of using proxies, you might need these other methods:
- Headers/User-Agent Spoofing: To mimic a real browser.
- Captcha Solvers: If the server uses CAPTCHA.
- Session Management: To maintain cookies and sessions across requests.
Scraping Google with a proxy
Big companies like Google are much stricter on protecting their site from being scraped. Even using a paid proxy, you might face multiple layers of challenges before you can start scraping data from Google.
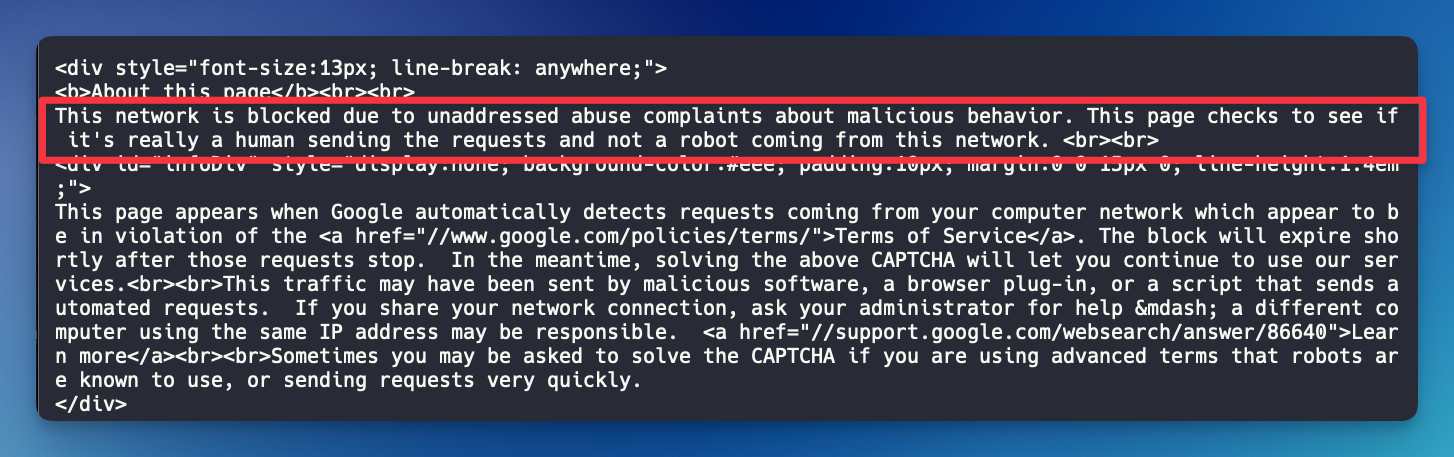
Luckily, SerpApi offers a simple API for developers to scrape Google and other search engines like Bing, DuckDuckGo, Yahoo, etc. Using our APIs, you don't need to think about buying a proxy, solving Captchas and other headaches that come with scraping.
Register for free at serpapi.com.
Here is a quick way to scrape Google using SerpApi:
from serpapi import GoogleSearch
params = {
"api_key": "YOUR_SERPAPI_API_KEY",
"engine": "google",
"q": "Coffee",
}
search = GoogleSearch(params)
results = search.get_dict()The other benefit of using SerpApi is controlling the geolocation when accessing a website.
FAQ
How do I get a proxy?
You can buy proxies from proxy providers or free proxy lists, but paid ones are more reliable.
When to use a proxy?
Use a proxy to hide your IP, bypass geo-restrictions, or avoid getting blocked while scraping.
What is proxy rotation?
Proxy rotation automatically switches proxies for each request to avoid detection and bans.
What is a residential proxy?
A residential proxy uses real IP addresses from real devices, making it harder to detect.