 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 C++
C++

This week we'll talk about how to convert a pth file to onnx file in order to use the trained model in production to enhance the parsing of SerpApi's Google Local Results Scraper API. Then, we'll be using ONNX Runtime Ruby gem to run the onnx file. Here's a mindmap of the process to reference:
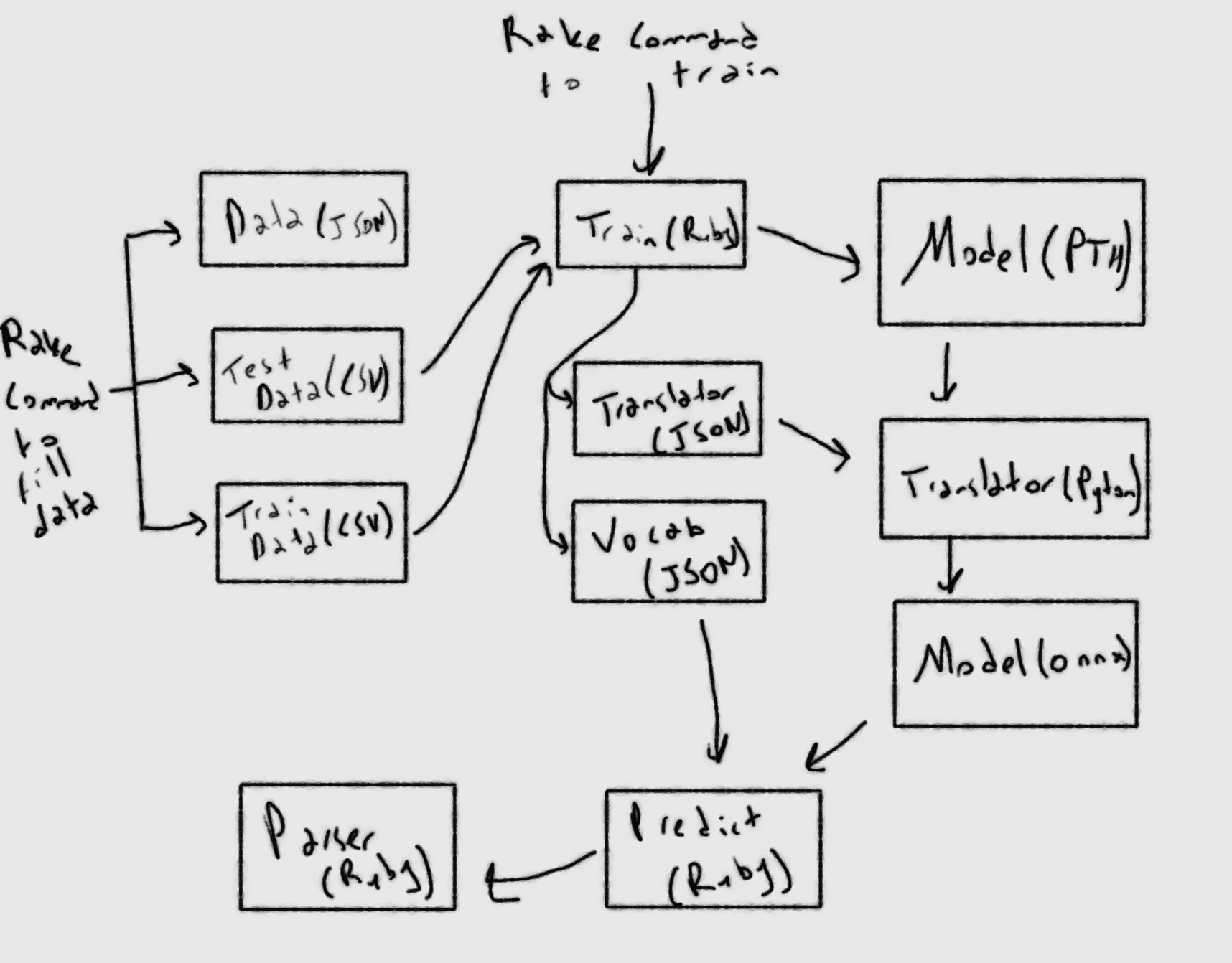
Necessary Variables for Conversion to ONNX
In order to transform a pth file into onnx file, we need several things to carry the state of the model. First, we'll need to create the model in translator code. This means we'll need the necessary inputs to initiate our model. Let's take a look at what it takes to construct the model:
def initialize(vocab_size, embed_dim, num_class)
super()
@embedding = Torch::NN::EmbeddingBag.new(vocab_size, embed_dim, sparse: true)
@fc = Torch::NN::Linear.new(embed_dim, num_class)
init_weights
endIn this case, we'll save vocab_size, embed_dim, and nun_class variables, and write them into a json file to be read from another file.
def self.save_model_constructors vocab_size, embed_dim, nun_class
path = "ml/google/local_pack/predict_value/trained_models/translator/translator.json"
data = File.read(path)
data = JSON.parse(data)
data['vocab_size'] = vocab_size
data['embed_dim'] = embed_dim
data['nun_class'] = nun_class
File.write(path, JSON.pretty_generate(data))
endWe also need an example input, or inputs to mimic the forwarding of the model. Our forwarding function is like this:
def forward(text, offsets)
embedded = @embedding.call(text, offsets: offsets)
@fc.call(embedded)
endSo we need an example text and offsets:
def self.save_model_inputs text, offsets
path = "ml/google/local_pack/predict_value/trained_models/translator/translator.json"
data = File.read(path)
data = JSON.parse(data)
data['text'] = text.to_a
data['offsets'] = offsets.to_a
File.write(path, JSON.pretty_generate(data))
endAll of these functions are integrated into a training file. Here's the result of the JSON file that is created:
{
"vocab_size": 24439,
"embed_dim": 128,
"nun_class": 9,
"text": [
2,
143,
3,
12211,
140,
144,
6259,
2,
...
},
"offsets": [
0,
7,
14,
29,
44,
51,
56,
63,
70,
77,
80,
83,
...
]
}Lastly, since we use an n-gram model, we need the vocabulary the model is using:
def self.save_vocab vocab
path = "ml/google/local_pack/predict_value/trained_models/n_gram_value_predictor_vocab.json"
data = JSON.parse(vocab.to_json)
File.write(path, JSON.pretty_generate(data))
endHere's the resulting JSON file containing different aspects of the vocabulary used in trained model. We'll be interested in stoi key specifically.
{
"freqs": {
"mcdonald": 2,
"'": 334,
"s": 309,
"mcdonald '": 1,
"' s": 293,
"starbucks": 5,
"goza": 1,
"espresso": 43,
...
},
"itos": [
"<unk>",
"<pad>",
"(",
")",
",",
"in",
"·",
"· in",
"+1",
...
],
"unk_index": 0,
"stoi": {
"<unk>": 0,
"<pad>": 1,
"(": 2,
")": 3,
",": 4,
"in": 5,
"·": 6,
"· in": 7,
"+1": 8,
"united": 9,
"states": 10,
"united states": 11,
...
},
"vectors": null
}
Converting to ONNX
There is a lack of support on ruby side for transforming pth to onnx. Luckily, we have a plan to train models locally, and use trained models as ONNX files in production.
This doesn't prevent us from using python file for the transformation process. In fact, this is the reason we used a JSON file to store preliminary variables for the conversion. This part requires PyTorch and python to execute. Here are the requirements:
import torch
import torch.nn as nn
import torch.nn.init as init
import jsonWe'll also need to recreate the model in python. It is not hard to recreate at all. Here's the model in ruby:
class GLocalNet < Torch::NN::Module
def initialize(vocab_size, embed_dim, num_class)
super()
@embedding = Torch::NN::EmbeddingBag.new(vocab_size, embed_dim, sparse: true)
@fc = Torch::NN::Linear.new(embed_dim, num_class)
init_weights
end
def init_weights
initrange = 0.5
@embedding.weight.data.uniform!(-initrange, initrange)
@fc.weight.data.uniform!(-initrange, initrange)
@fc.bias.data.zero!
end
def forward(text, offsets)
embedded = @embedding.call(text, offsets: offsets)
@fc.call(embedded)
end
endSo, here's its reconstruction in python:
class GLocalNet(nn.Module):
def __init__(self, vocab_size, embed_dim, num_class):
super(GLocalNet, self).__init__()
self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=True)
self.fc = nn.Linear(embed_dim, num_class)
self.init_weights()
def init_weights(self):
initrange = 0.5
self.embedding.weight.data.uniform_(-initrange, initrange)
self.fc.weight.data.uniform_(-initrange, initrange)
self.fc.bias.data.zero_()
def forward(self, text, offsets):
embedded = self.embedding(text, offsets)
return self.fc(embedded)After that, we'll call the necessary variables from a JSON file we previously created and filled:
json_path = "ml/google/local_pack/predict_value/trained_models/translator/translator.json"
f = open(json_path)
data = json.load(f)
#Constructors
vocab_size = data['vocab_size']
embed_dim = data['embed_dim']
nun_class = data['nun_class']
#Inputs
text = torch.tensor(data['text'])
offsets = torch.tensor(data['offsets'])PyTorch has an excellent module, onnx.export. We set the necessary parameters for the conversion.
file_path = "ml/google/local_pack/predict_value/trained_models/n_gram_value_predictor.pth"
model = GLocalNet(vocab_size, embed_dim, nun_class)
model.load_state_dict(torch.load(file_path))
model.eval()
torch.onnx.export( model,
(text, offsets),
"ml/google/local_pack/predict_value/trained_models/n_gram_value_predictor.onnx",
export_params=True,
opset_version=11,
do_constant_folding=True,
input_names = ['text', 'offsets'],
output_names = ['label'],
dynamic_axes={ 'text' : {0 : 'batch_size'},
'offsets': {0 : 'batch_size'},
'label' : {0 : 'batch_size'} })Here's the breakdown of the conversion process:
model: model we loaded earlier.
(text, offsets): example inputs.
"ml/google/local_pack/predict_value/trained_models/n_gram_value_predictor.onnx": path to save the onnx model.
export_params=True: parameter for storing trained parameter weights.
opset_version=11: onnx version to use. We picked 11 to support EmbeddingBag which is in the model.
do_constant_folding=True: parameter for executing constant folding for optimization.
input_names = ['text', 'offsets']: input names to be used when calling conversed onnx model.
output_names = ['label']: output names to be used when calling conversed onnx model.
dynamic_axes={'text':{0:'batch_size'}, 'offsets': {0:'batch_size'}, 'label':{0:'batch_size'}}: parameter for keeping the inputs and outputs dynamic.
Implementing ONNX in Ruby on Rails
I was lucky to realize that the vocabulary iterator for torchtext-ruby was not dependent on torch itself. To implement the model for production purposes, we cannot have a large files for a solution such as this.
So with a little bit of a tweak, I was able to create a input loader that takes text and translates it into an array using the vocab we saved earlier in training.
def create_input text
def ngrams_iterator(token_list, ngrams)
return enum_for(:ngrams_iterator, token_list, ngrams) unless block_given?
get_ngrams = lambda do |n|
(token_list.size - n + 1).times.map { |i| token_list[i...(i + n)] }
end
token_list.each do |x|
yield x
end
2.upto(ngrams) do |n|
get_ngrams.call(n).each do |x|
yield x.join(" ")
end
end
end
def basic_english_normalize(line)
line = line.downcase
@patterns_dict.each do |pattern_re, replaced_str|
line.sub!(pattern_re, replaced_str)
end
line.split
end
def vocab_operation vocab, token
if vocab[token].present?
vocab[token]
else
vocab[token] = vocab.values.last + 1
vocab[token]
end
end
_patterns = [%r{\'}, %r{\"}, %r{\.}, %r{<br \/>}, %r{,}, %r{\(}, %r{\)}, %r{\!}, %r{\?}, %r{\;}, %r{\:}, %r{\s+}]
_replacements = [" \' ", "", " . ", " ", " , ", " ( ", " ) ", " ! ", " ? ", " ", " ", " "]
@patterns_dict = _patterns.zip(_replacements)
vocab_path = "ml/google/local_pack/predict_value/trained_models/n_gram_value_predictor_vocab.json"
data = File.read(vocab_path)
data = JSON.parse(data)
vocab = data['stoi']
ngrams = 2
new_vocab = []
arr = ngrams_iterator(basic_english_normalize(text), ngrams).map { |token| vocab_operation vocab, token }
arr
endHere's the function for prediction of label from a string:
def get_prediction text
local_pack_label = {
0 => "title",
1 => "rating",
2 => "reviews",
3 => "type",
4 => "phone",
5 => "address",
6 => "hours",
7 => "price",
8 => "description"
}
path = "ml/google/local_pack/predict_value/trained_models/n_gram_value_predictor.onnx"
model = OnnxRuntime::Model.new(path)
output = model.predict(text: create_input(text), offsets: [0])
result = local_pack_label[output['label'][0].find_index(output['label'][0].max)]
result.to_sym
endget_prediction command:
- takes the
text, - transforms it into an array using
vocab, - loads it into the model using
ONNX file, - gets the
resultarray which consists of different floats representing the probability of labels in order, - takes the index of maximum probability and runs it in
local_pack_labelhash, - predicts its
labeland returns it as asymbol.
Conclusion
This helper function can be directly implemented in our parsers. Next week, we'll talk about expansion of vocabulary for n-grams, implementation of this function within our parsers, and comparison of JSON results versus using the parser enhanced with predictive model, and traditional parser. We'll also mention a usecase for Machine Learning on Rspec.
I'd like to thank the brave and brilliant people of SerpApi for all their support, especially in these trying times. Also, I am grateful to the reader for their attention.
Acknowledgements:
- Gems Used:
torch.rb
torchtext-ruby
onnxruntime-ruby - C++ Libraries Used:
LibTorch 1.10.2, Linux, CUDA 10.2, cxx11 ABI - Materials Repurposed From:
Documentation
Tutorial