 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

In my previous blog post, we can scrape Google Images Results with keywords and it's pretty easy with SerpApi. From here, when you want more images, you can also scrape similar images with our SerpApi Google Image Related Content Results API.
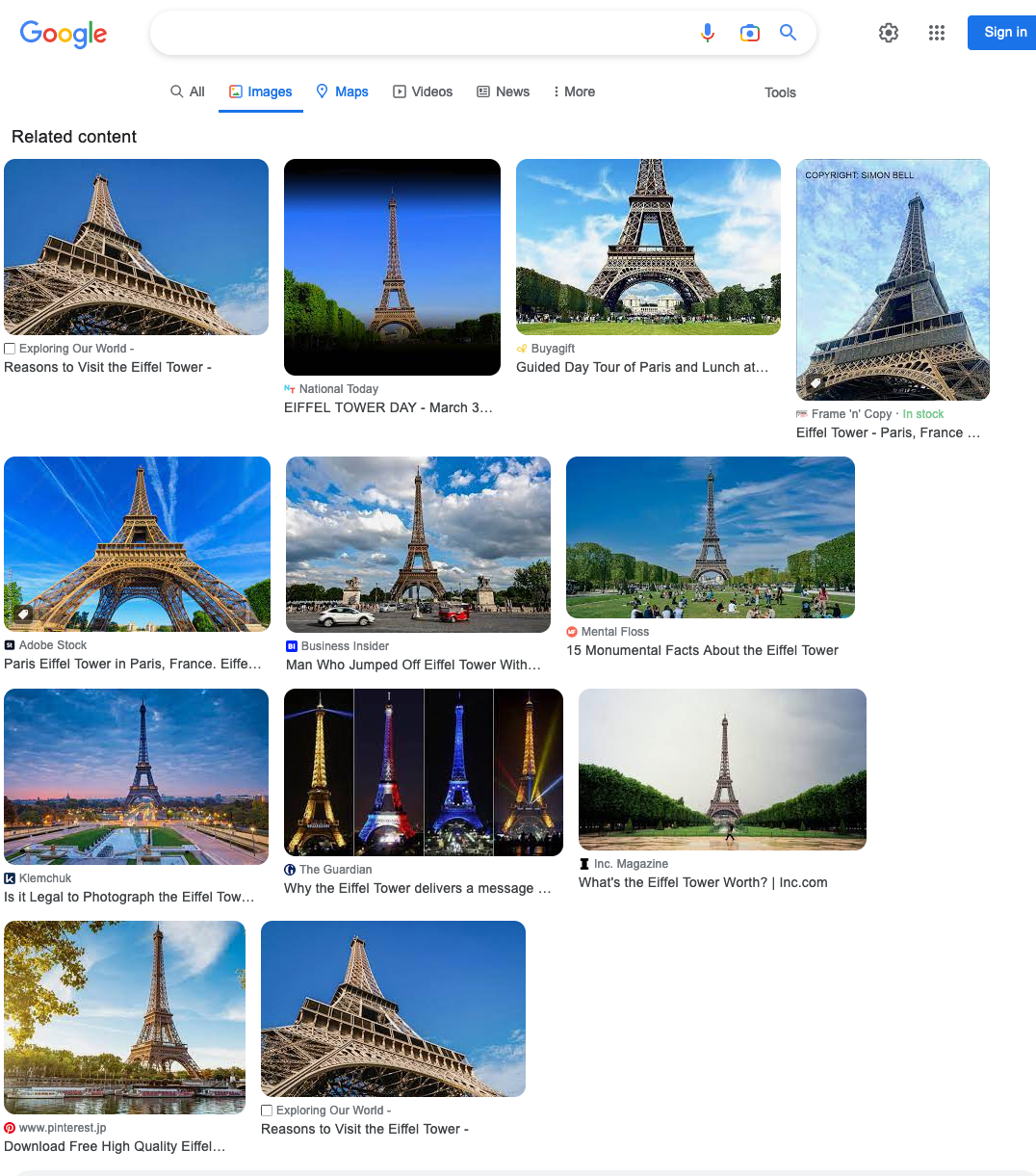
The related images offer users more options and variations like similar objects, scenes, colors, compositions or visual styles. You can discover more visual content that aligns with your interests and search intent.
It's always helpful to get more images related to your search intent. SerpApi also supports this API, so it should be easy to scrape with us.
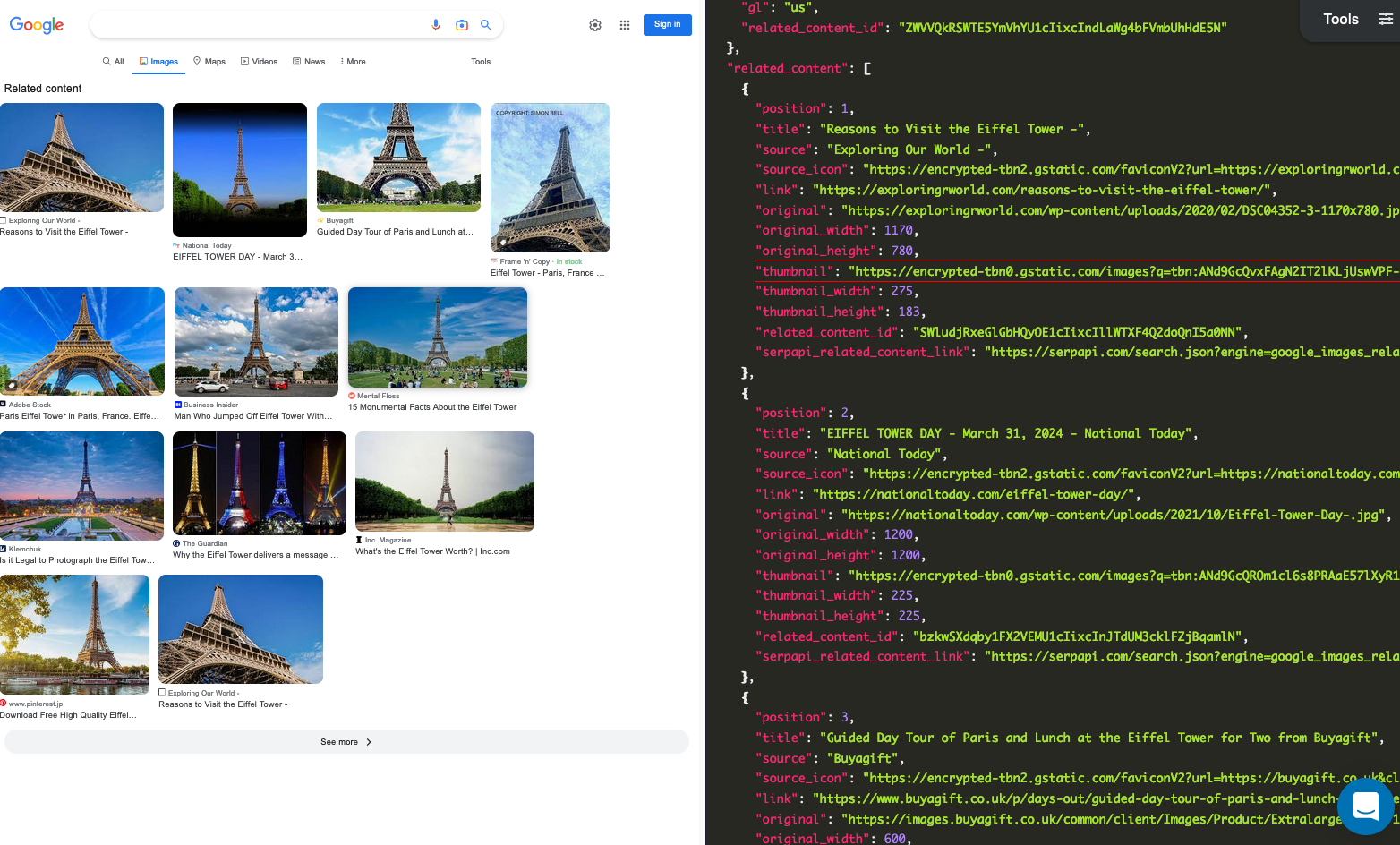
Setting up a SerpApi account
SerpApi offers a free plan for newly created accounts. Head to the sign-up page to register an account and complete your first search with our interactive playground. When you want to do more searches with us, please visit the pricing page.
Once you are familiar with all results, you can utilize SERP APIs using your API Key.
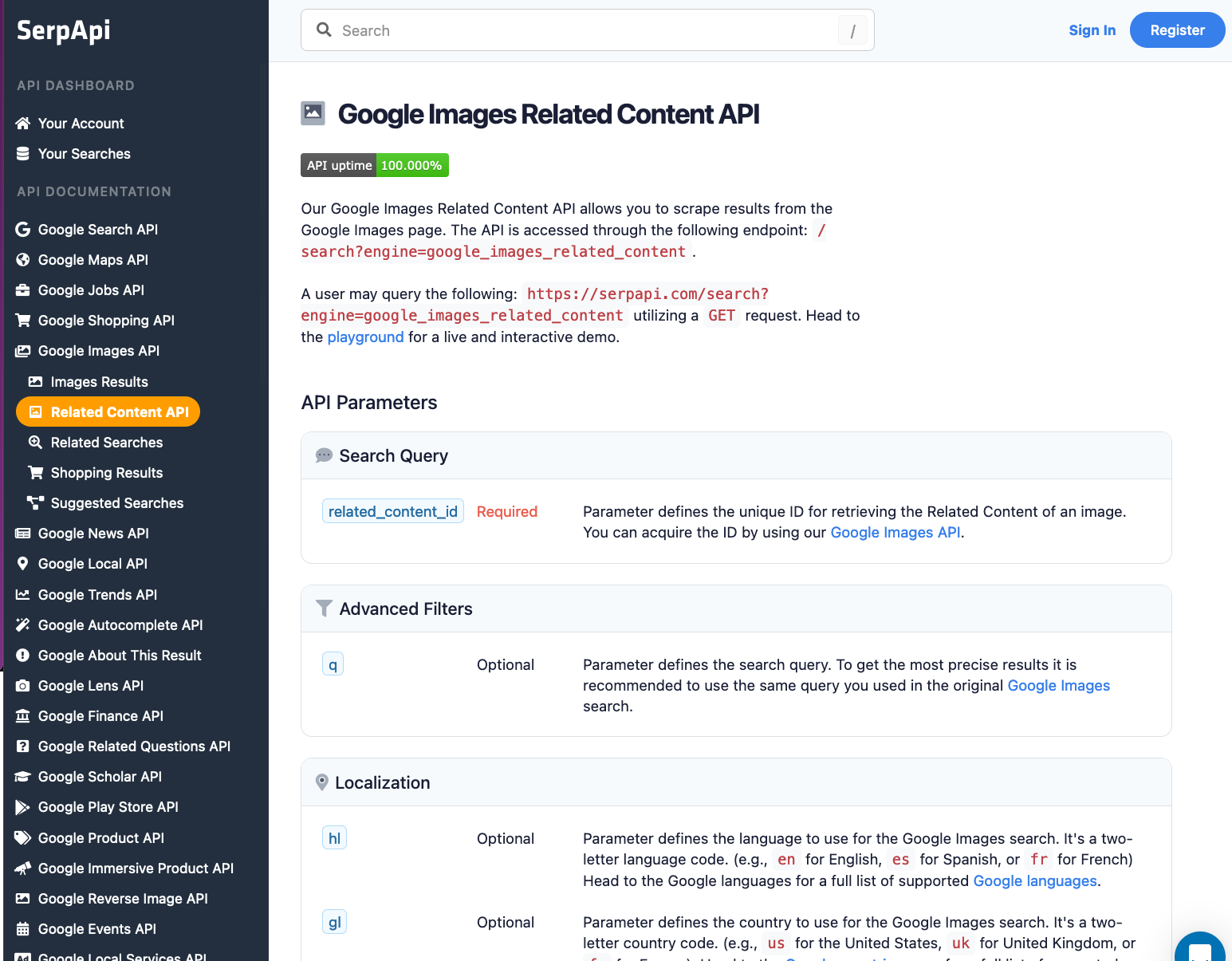
Scrape your first Google Image Related Content results with SerpApi
Head to the Google Image Related Content Results from the documentation on SerpApi for details.
From the previous tutorial, you can scrape images from Google Images and it will have "related_content_id". In this tutorial, we will scrape related images for one of the images from the "Eiffel tower" keyword. The data contains: "position", "title", "link", "source", "original", "original_width", "original_height", "thumbnail", and more. You can also scrape more information with SerpApi.
First, you need to install the SerpApi client library.
pip install google-search-resultsSet up the SerpApi credentials and search.
import serpapi
import os, json, csv
params = {
'api_key': 'YOUR_API_KEY', # your serpapi api
'engine': 'google_images_related_content', # SerpApi search engine
'related_content_id': 'ZWVVQkRSWTE5YmVhYU1cIixcIndLaWg4bFVmbUhHdE5N'
}
To retrieve Google Image Related Content Results for a given search query, you can use the following code:
client = serpapi.Client()
results = client.search(params)['related_content']
You can store Google Image Related Content Results JSON data in databases or export them to a CSV file.
import csv
header = ['position', 'title', 'link', 'source', 'original', 'original_width', 'original_height', 'thumbnail']
with open('google_image_related_content.csv', 'w', encoding='UTF8', newline='') as f:
writer = csv.writer(f)
writer.writerow(header)
for item in results:
print(item)
writer.writerow([item.get('position'), item.get('title'), item.get('link'), item.get('source'), item.get('original'), item.get('original_width'), item.get('original_height'), item.get('thumbnail')])
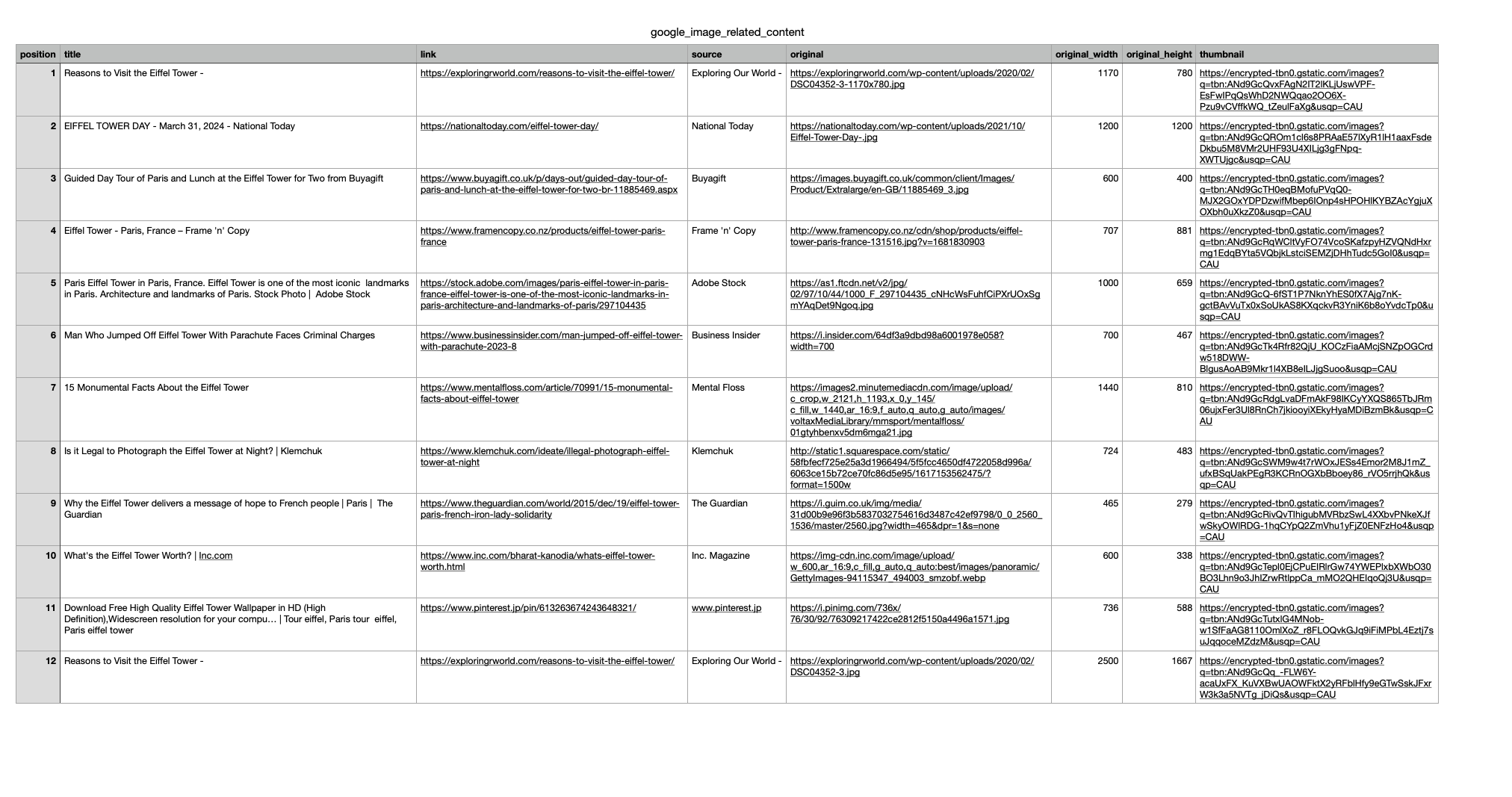
This example is using Python, but you can also use all your favorite programming languages likes Ruby, NodeJS, Java, PHP, and more.
Want to scrape more images with Google Images? Check out this blog post.
If you have any questions, please feel free to contact me.