 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

This week we'll share the comparisons with our problematic parser and how ML-Hybrid model will improve our parsing. I picked SerpApi's Google Local Pack Scraper API as the testing ground. We'll only use Desktop results in the scope of this comparison.
Rules of Comparison
Let's define some rules to compare two parsers:
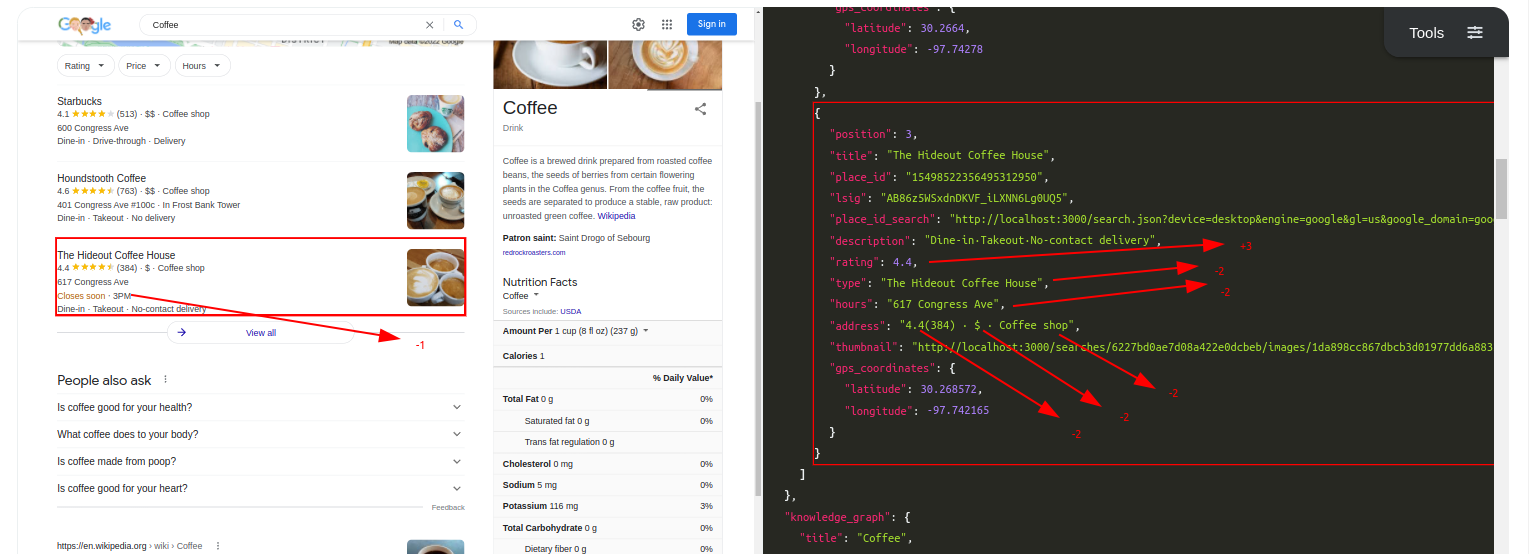
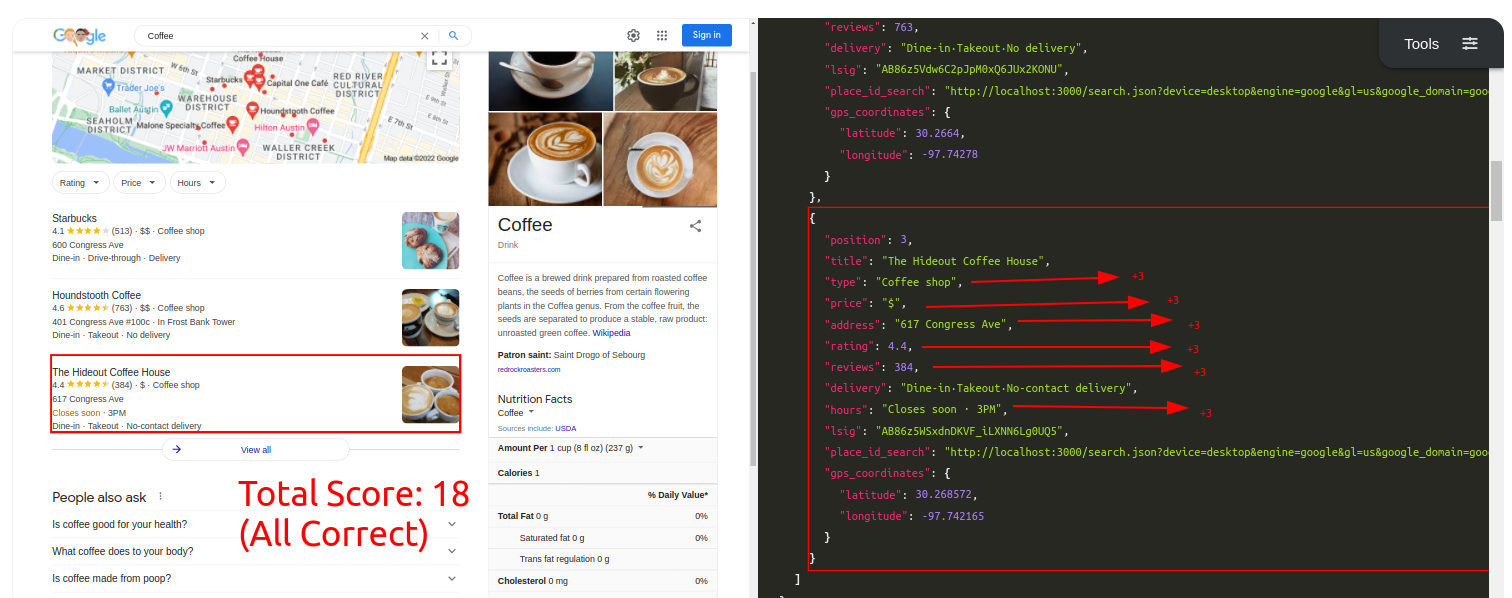
- Correct Parsing gives
+3points - Incorrect Parsing gives
-2points - Partial Correct Parsing is still Incorrect Parsing, so
-2points - If a correctly parsed value appears at another key, second appearence will be considered
-2separately, so in the end it'll equate to+1(minus for confusion) - If more than one element appear at an unwanted key, they'll separately have
-2points - If a text within the part of HTML is not scraped in any of the keys, it'll have
-1points for not causing a confusion
Examples
We tried to use queries from different queries from different sectors of business in order to eliminate bias in the comparison. There aren't any problems with calculating ML-Hybrid Model. However, the reader must take into consideration the invalidity of Traditional Parser, same problems appear over different values.
With that being said, traditional parser uses a big and complex set of conditions in order to parse results. It is hard to maintain, and CSS targets change almost every two weeks. ML-Hybrid model on the other hand uses simple CSS targets such as div:has(text()) in order to gather texts necessary on the targeted fields.
Query: Dentist
Traditional Parser Score: -10
ML-Hybrid Parser Score: 14
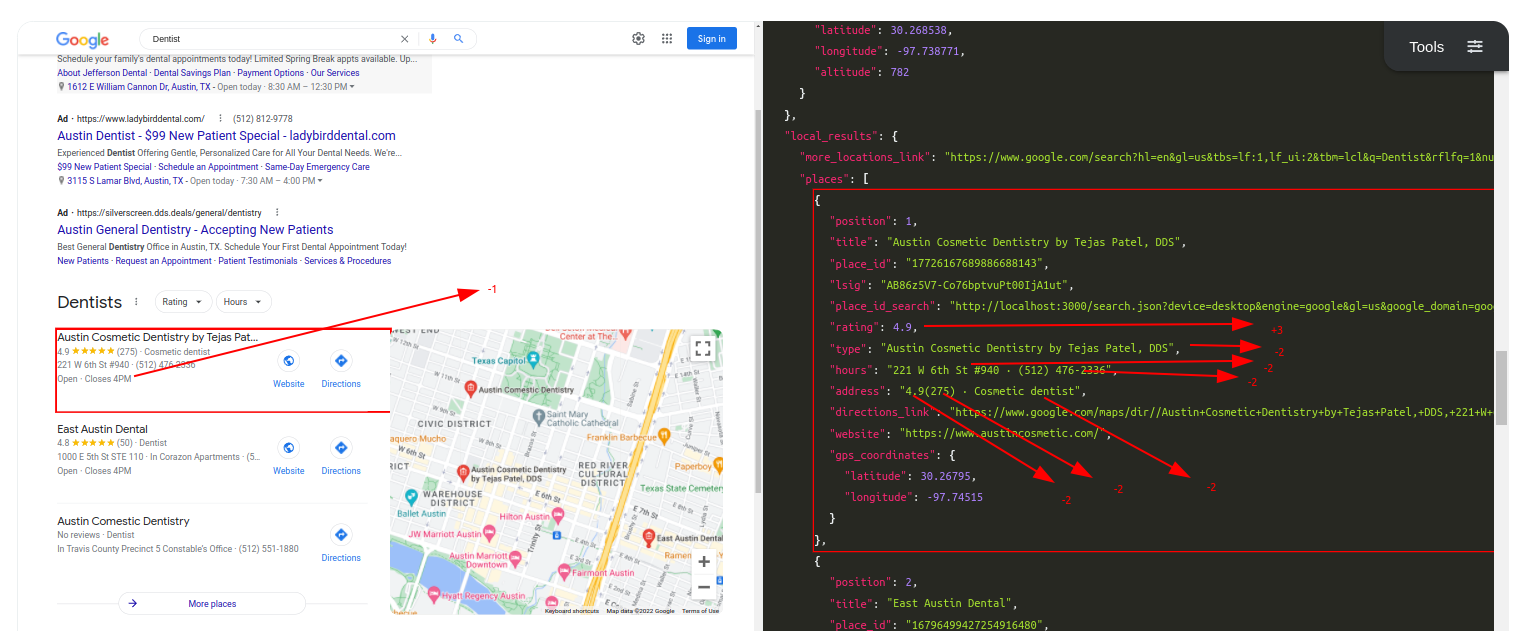
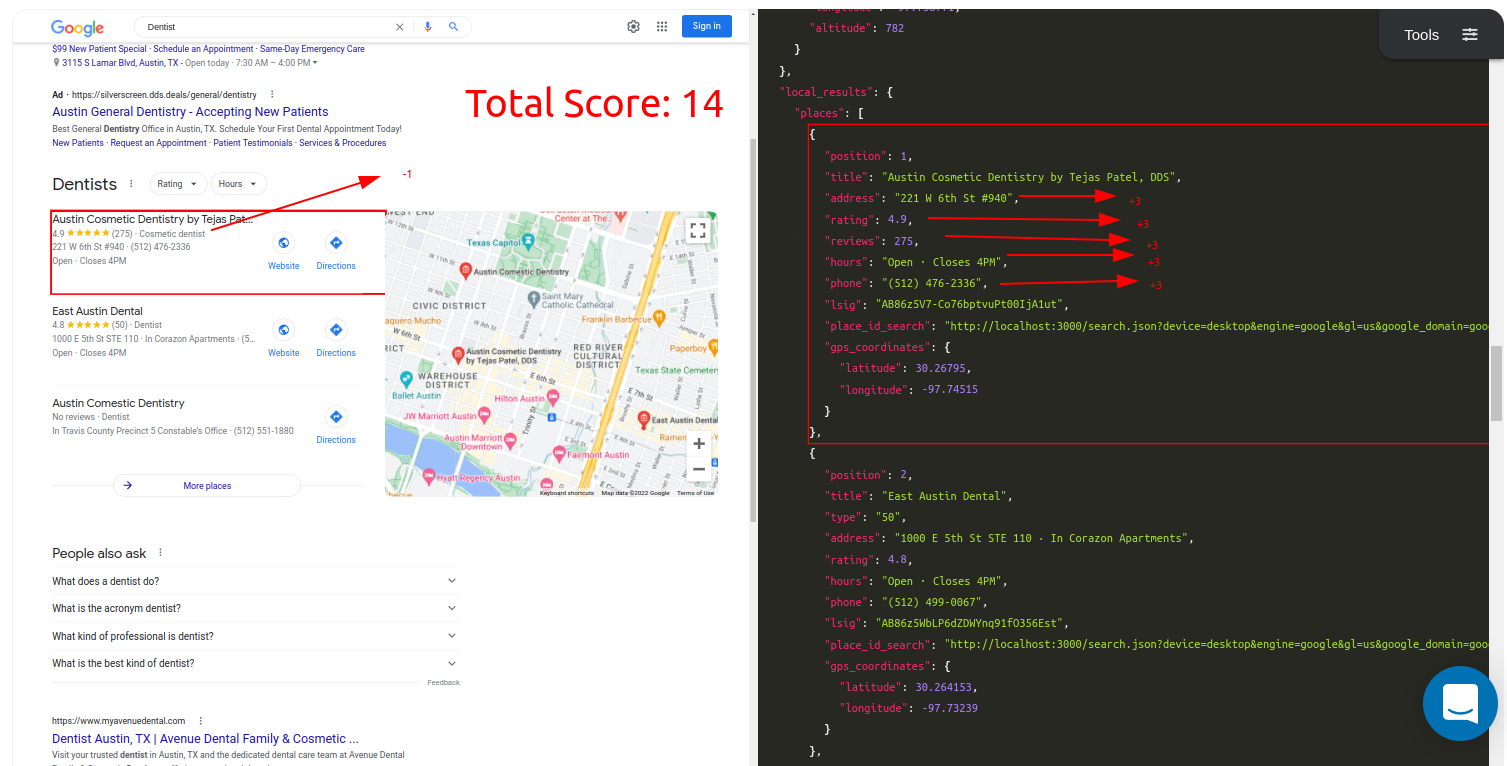
Query: Dentist
Traditional Parser Score: -10
ML-Hybrid Parser Score: 10
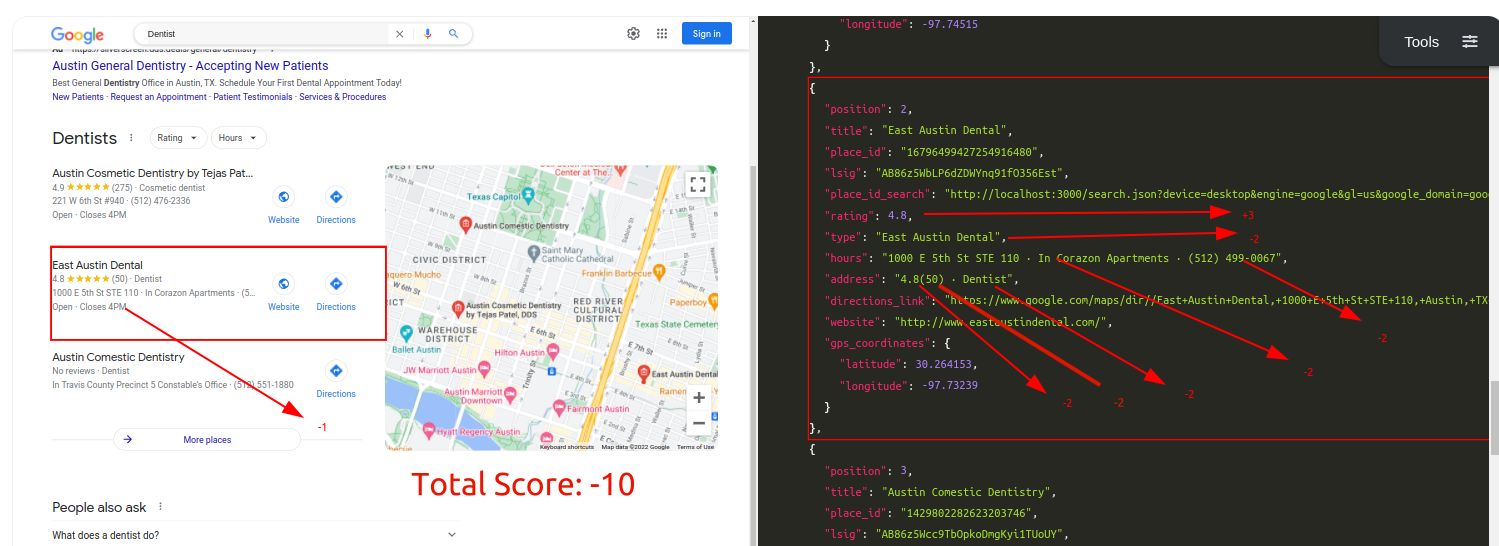
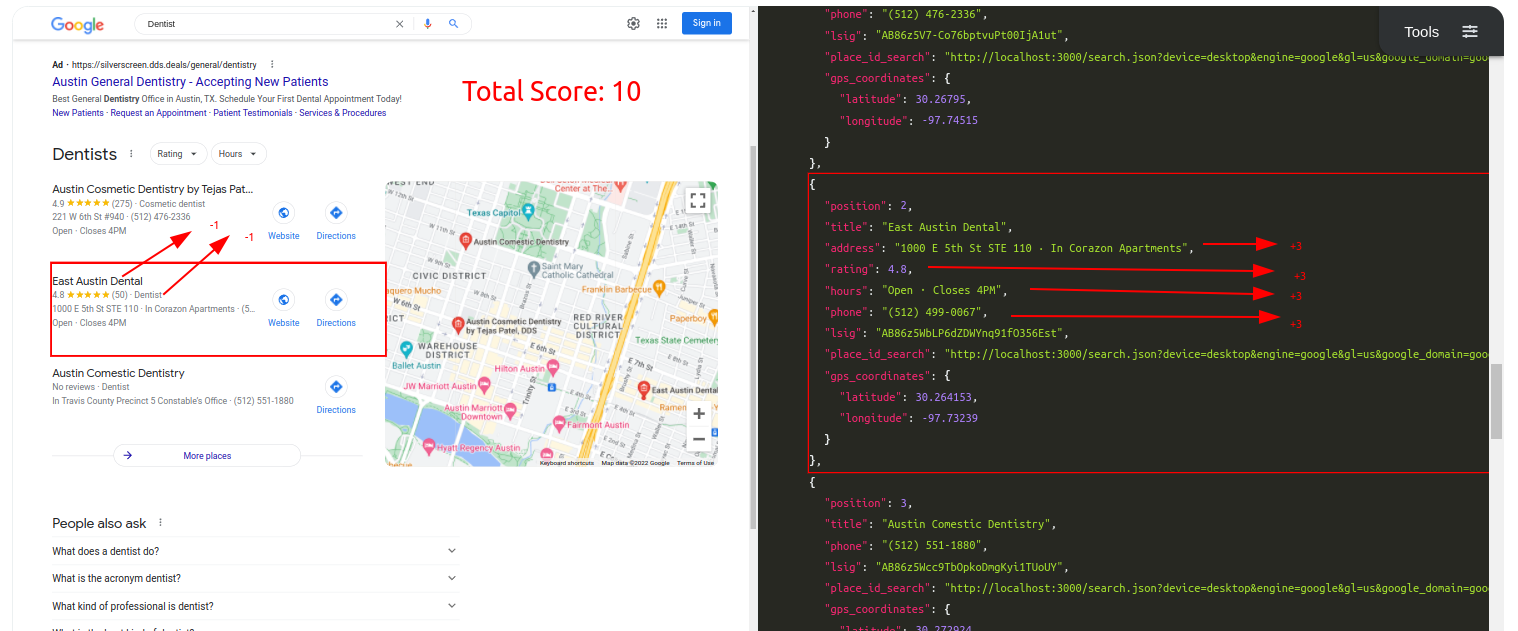
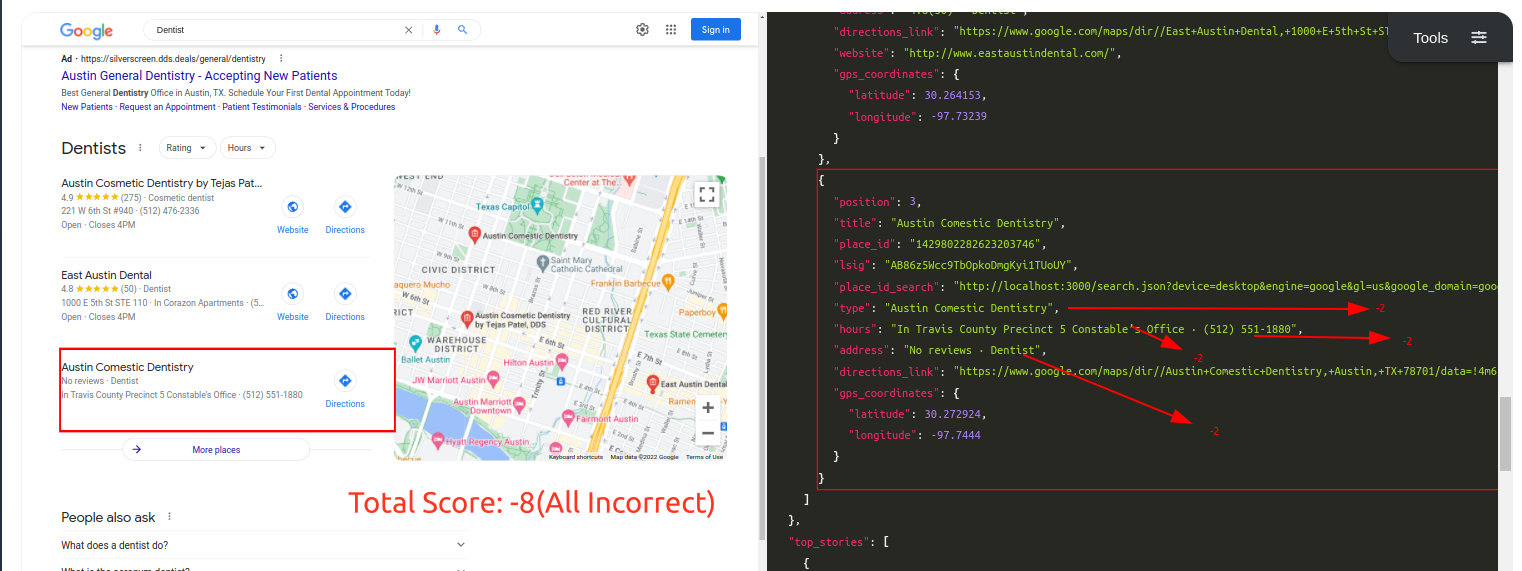
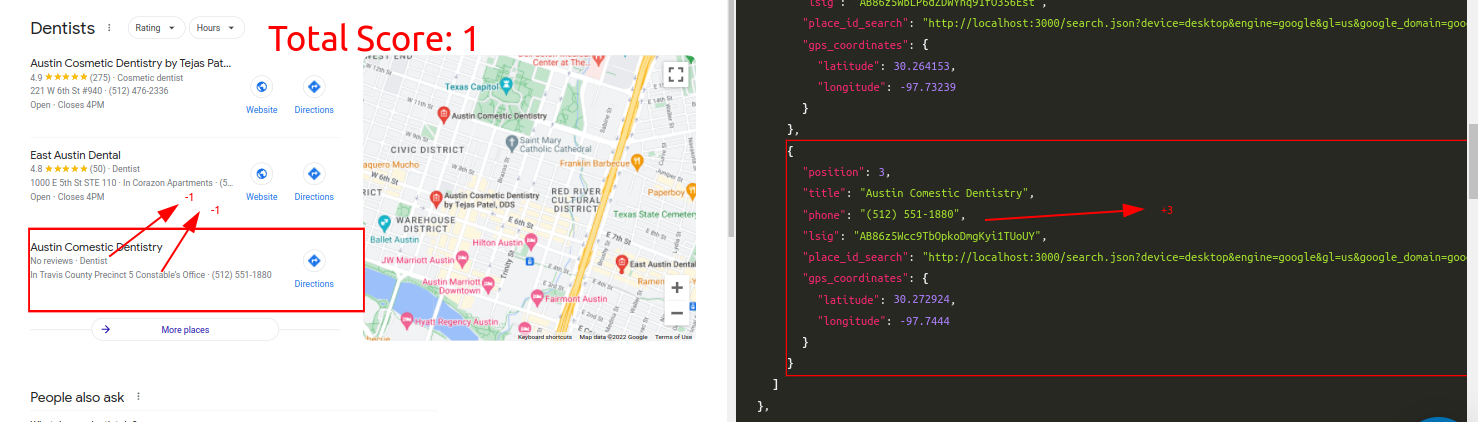
Query: DentistTraditional Parser Score: -8 (All Incorrect)ML-Hybrid Parser Score: 1
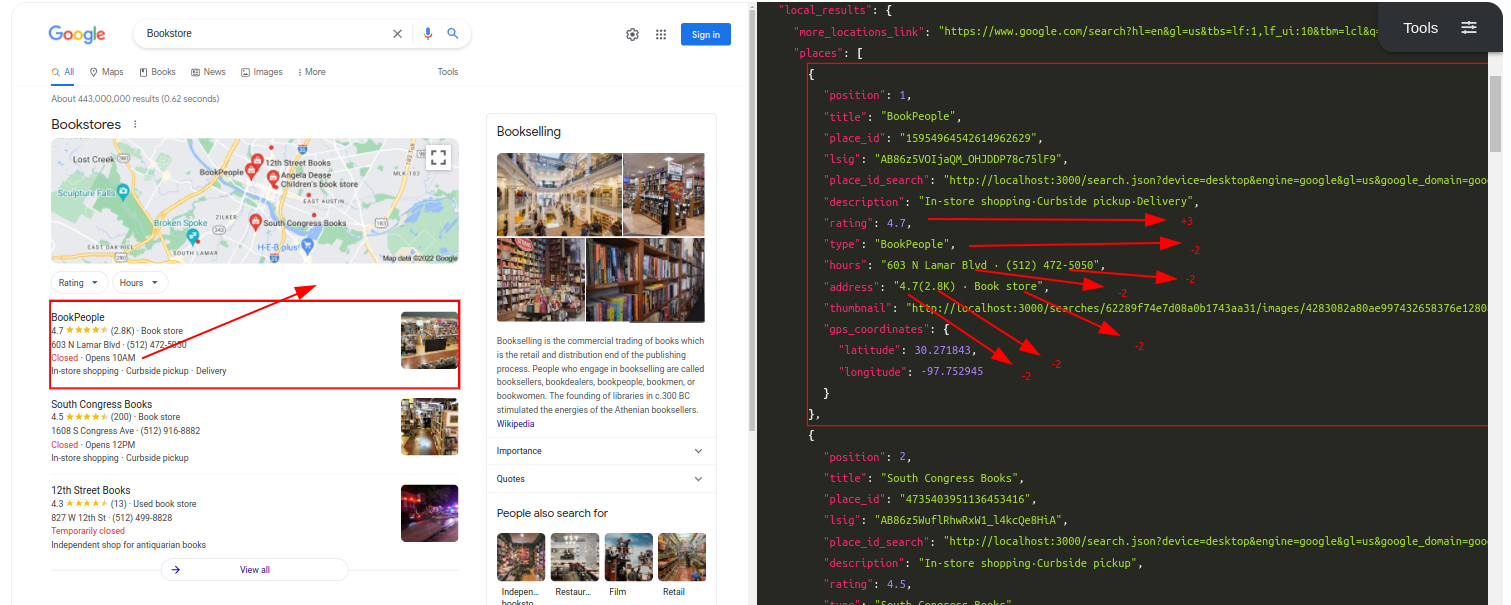
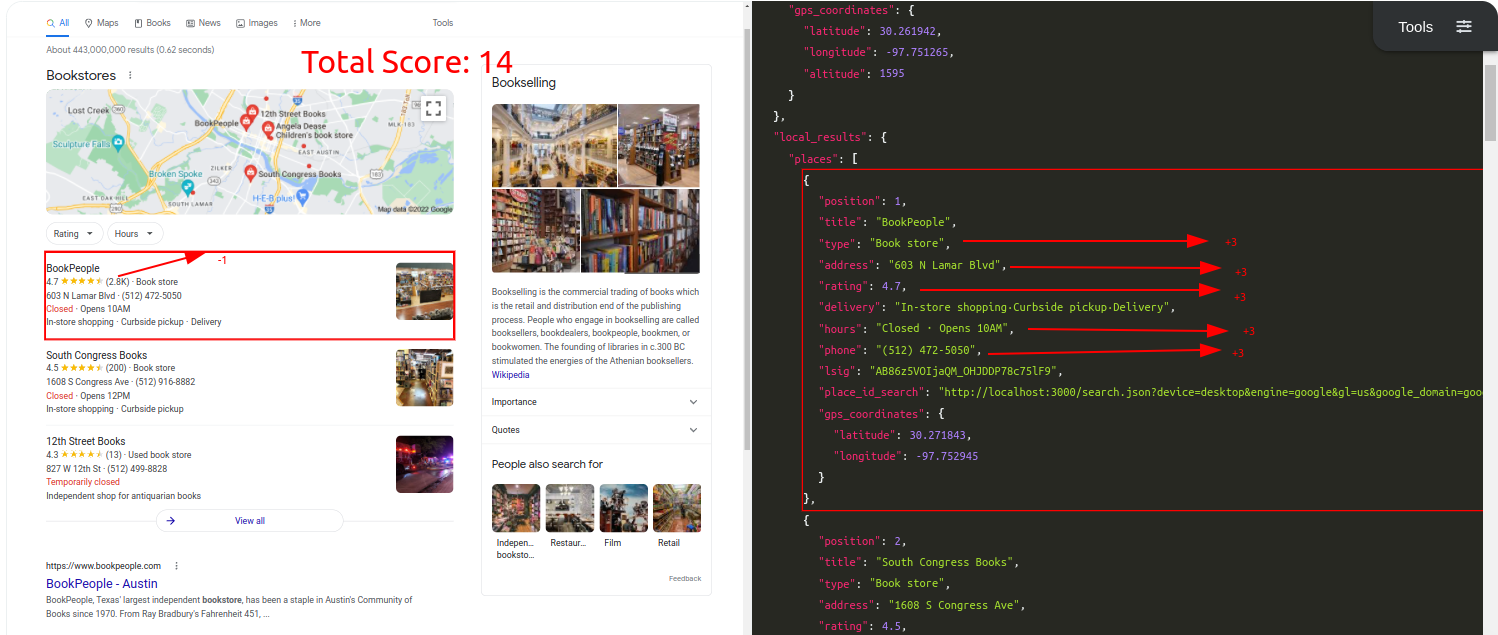
Query: BookstoreTraditional Parser Score: -10ML-Hybrid Parser Score: 14
Query: BookstoreTraditional Parser Score: -10ML-Hybrid Parser Score: 21 (All Correct)
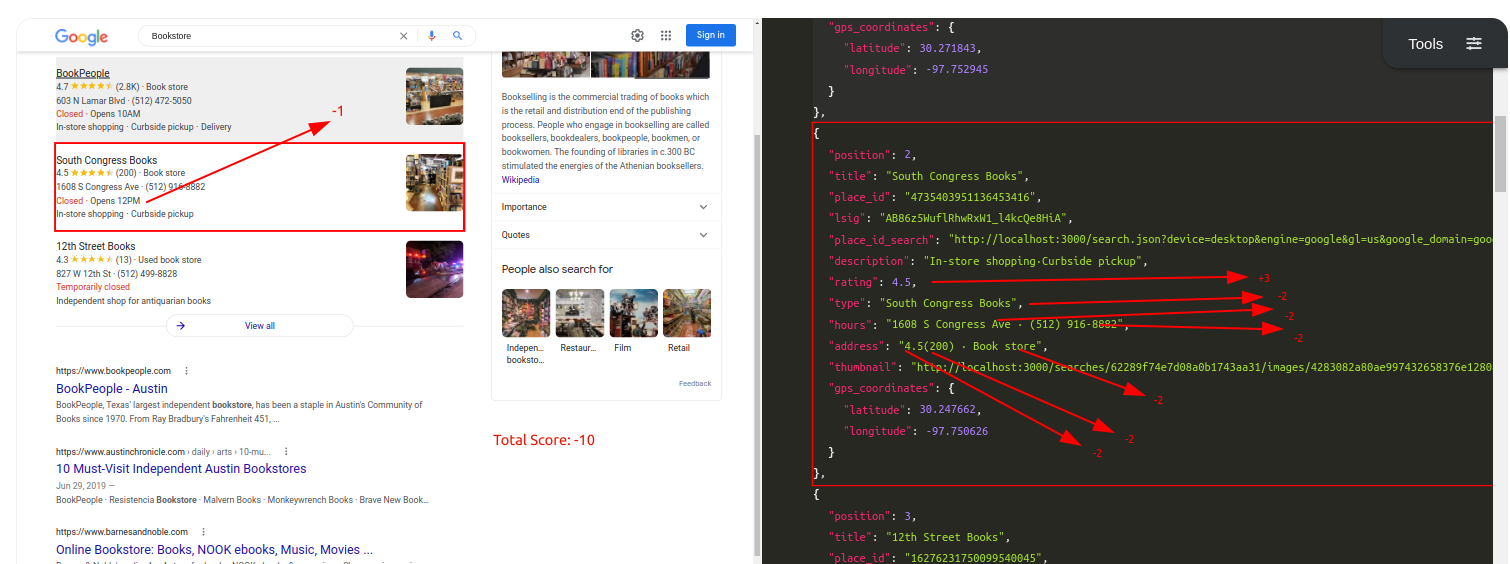
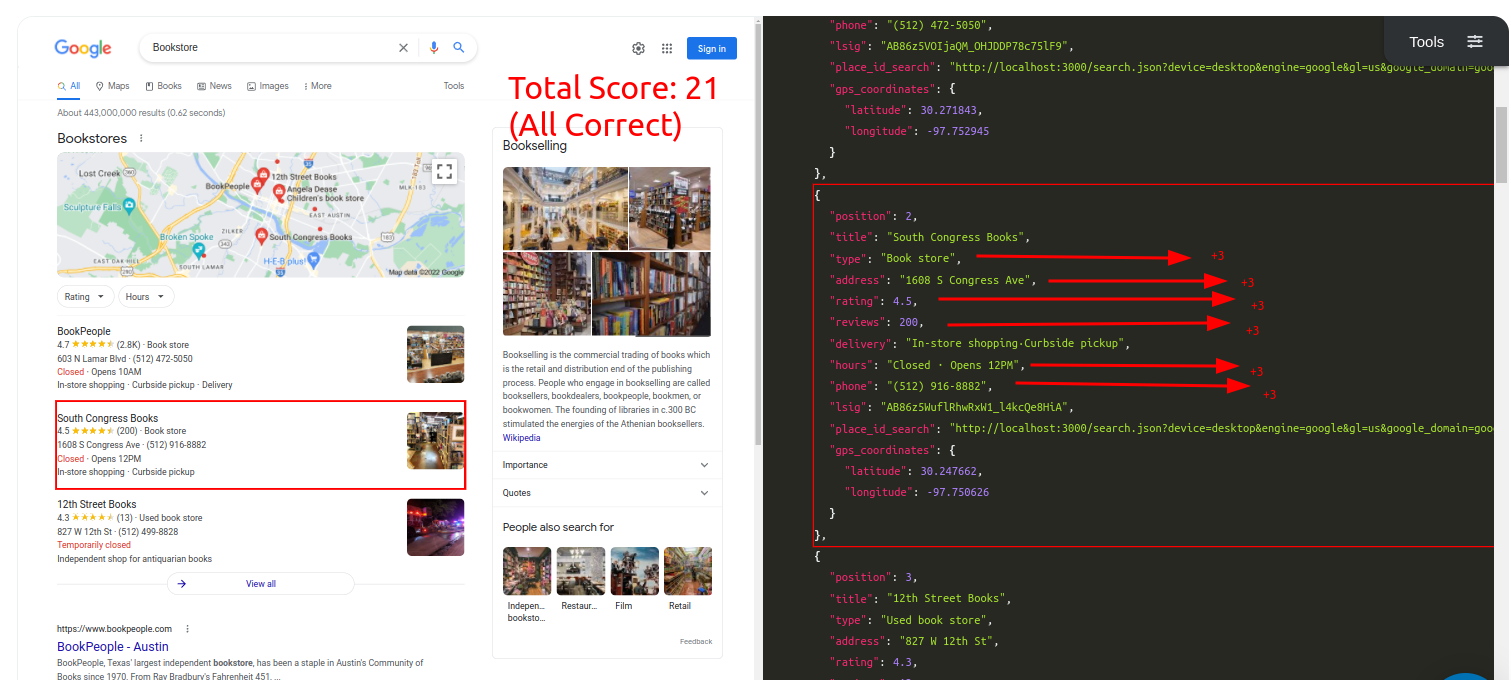
Query: BookstoreTraditional Parser Score: -3ML-Hybrid Parser Score: 17
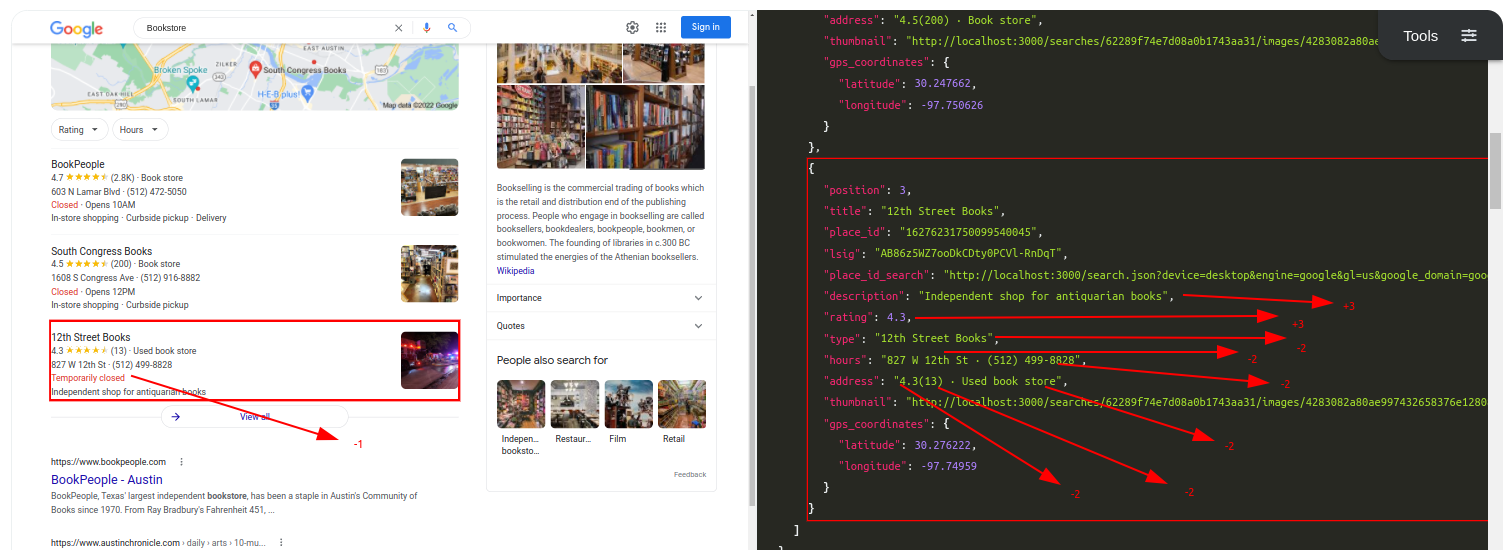
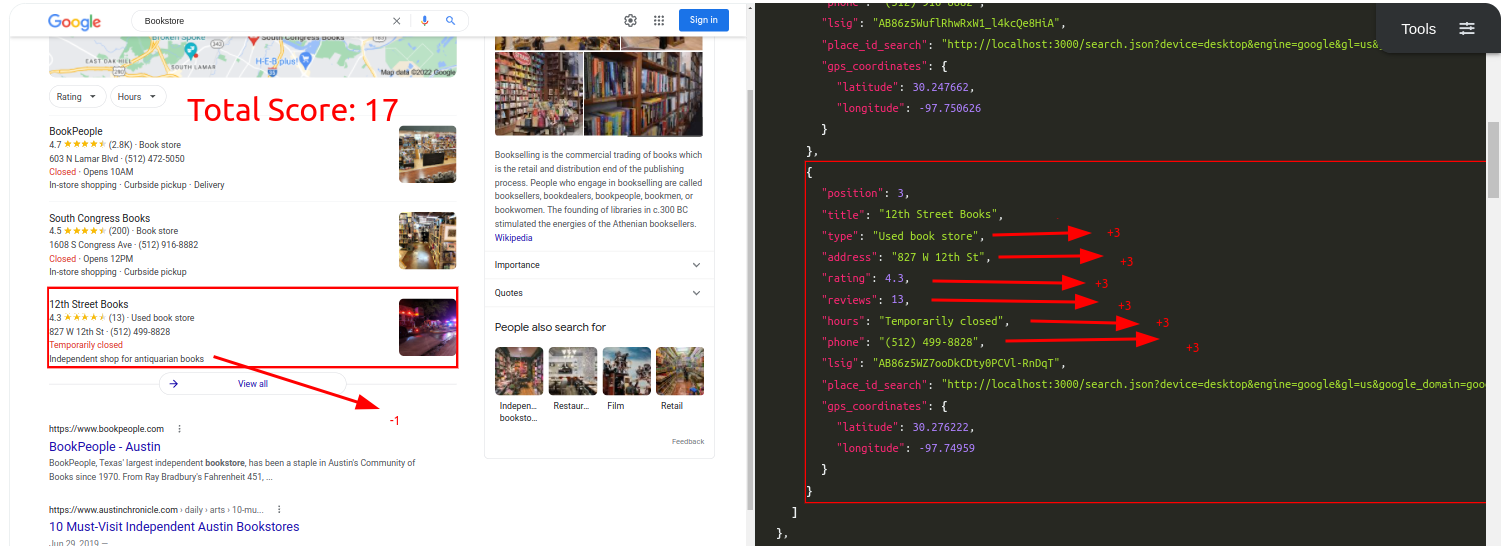
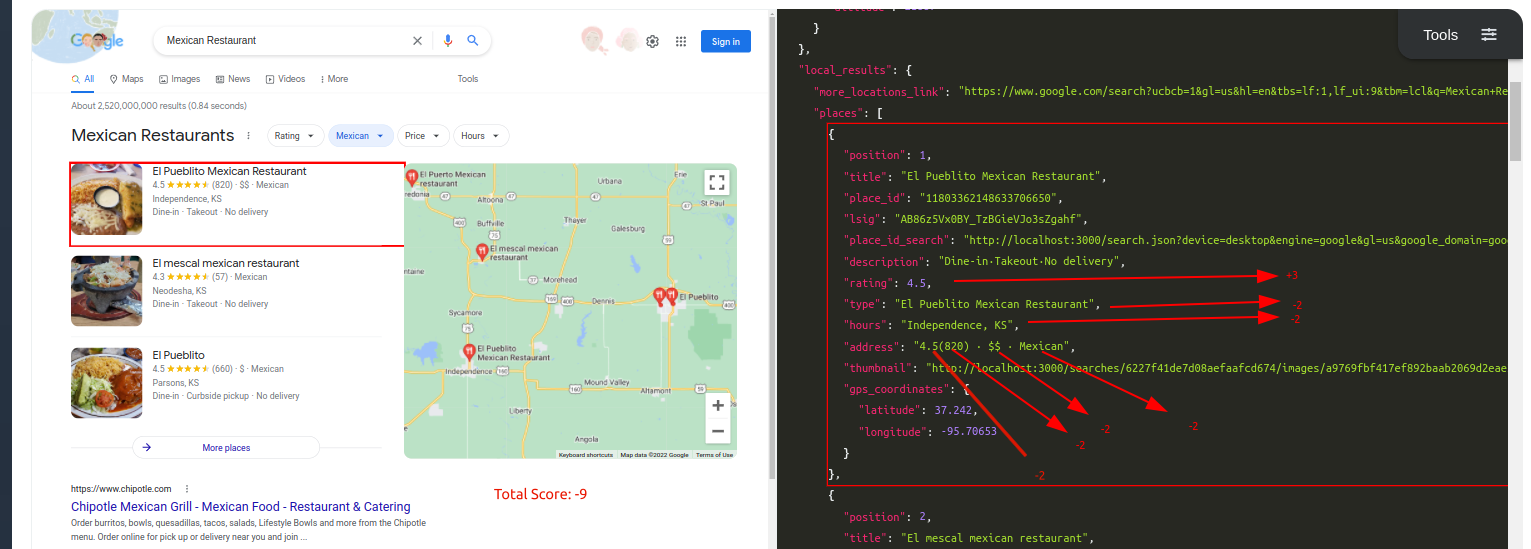
Query: Mexican RestaurantTraditional Parser Score: -9ML-Hybrid Parser Score: 15 (All Correct)
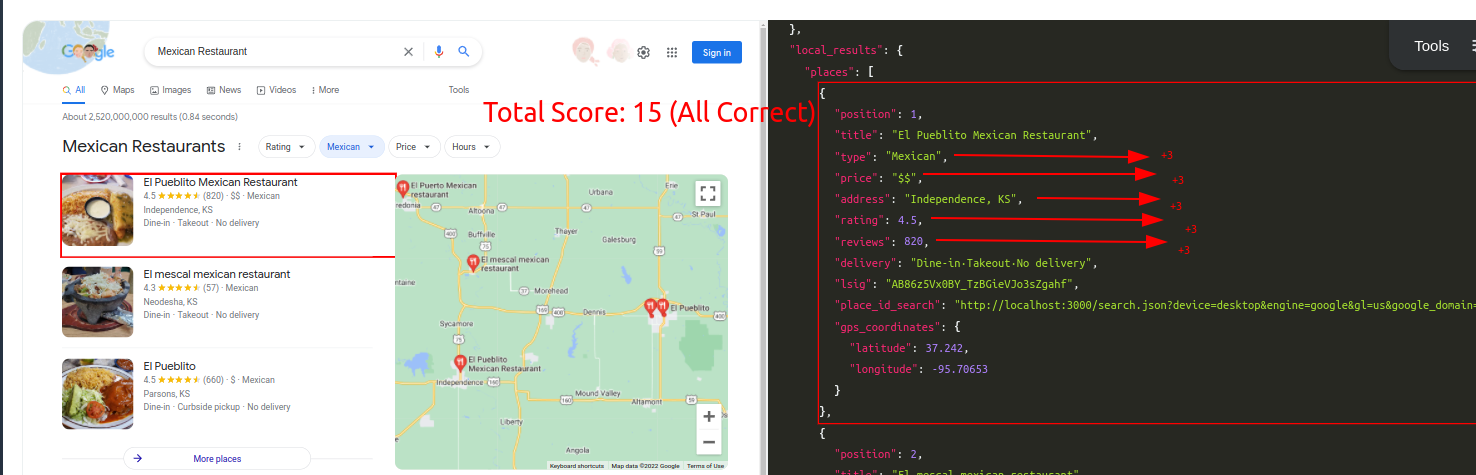
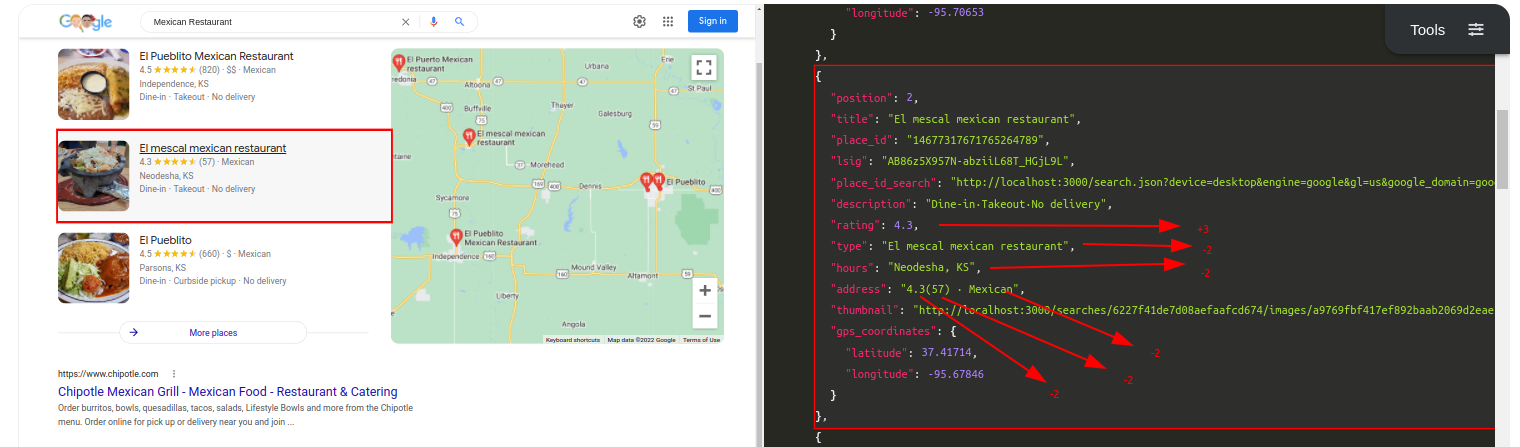
Query: Mexican RestaurantTraditional Parser Score: -7ML-Hybrid Parser Score: 12 (All Correct)
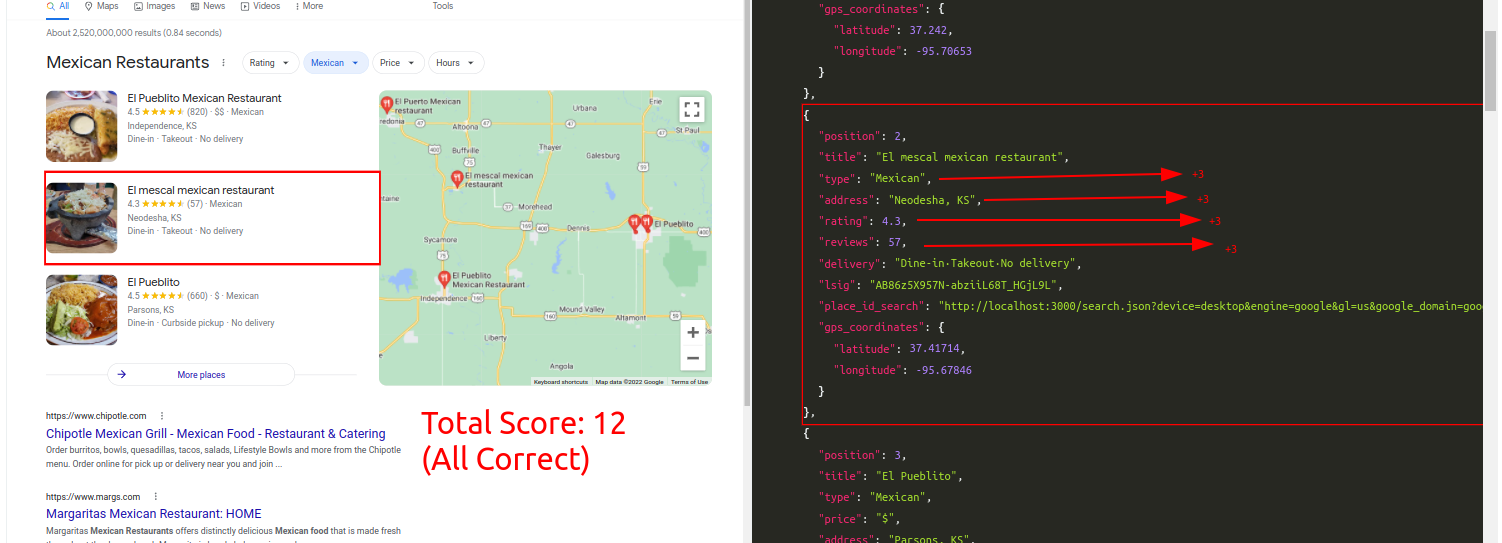
Query: Mexican RestaurantTraditional Parser Score: -7ML-Hybrid Parser Score: 12
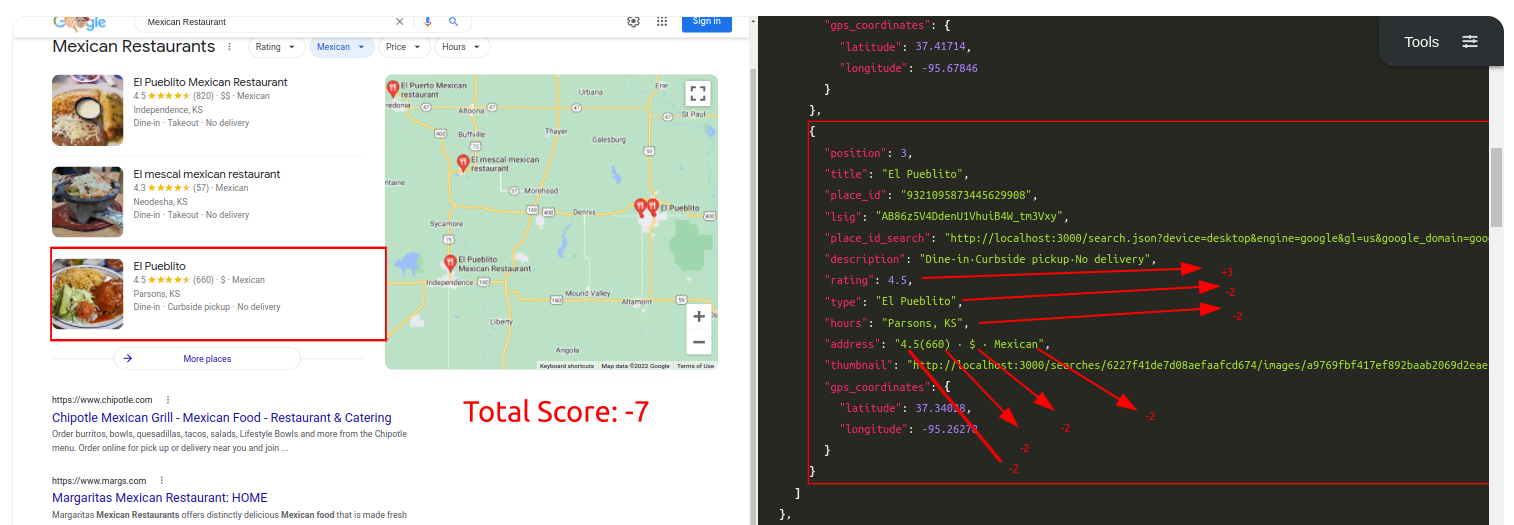
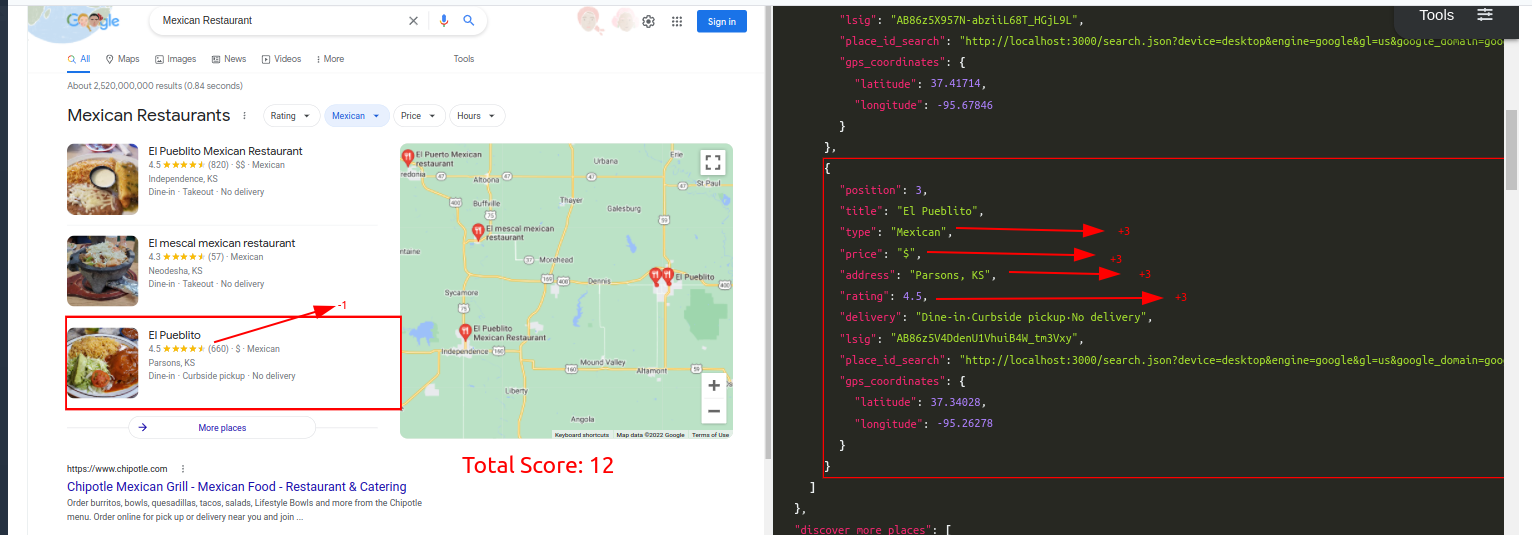
Query: Insurance AgencyTraditional Parser Score: -9ML-Hybrid Parser Score: 15 (All Correct)
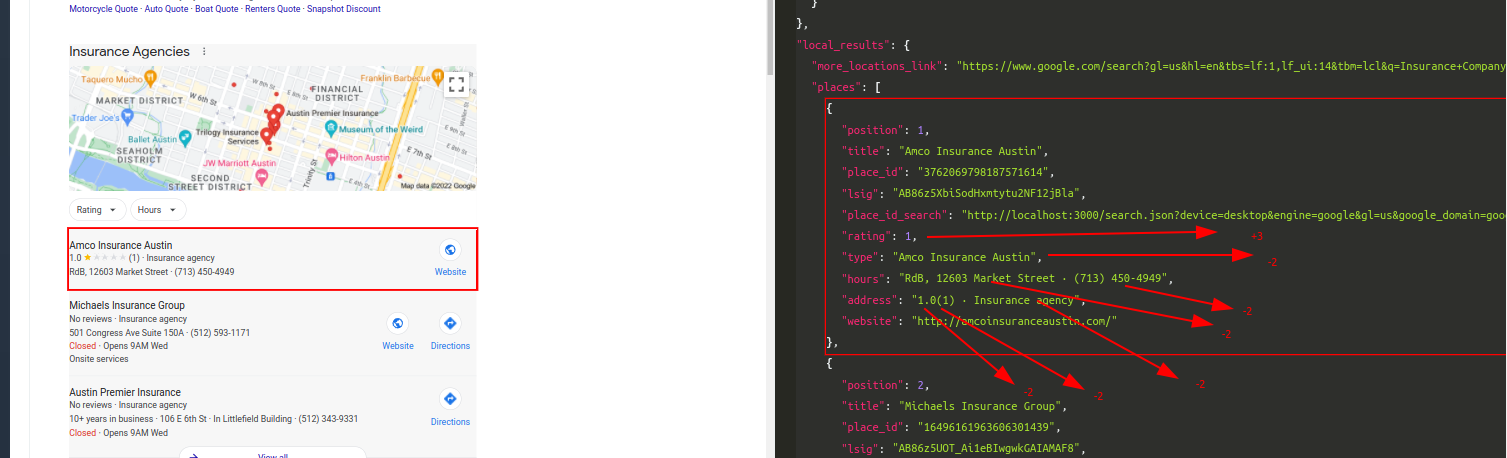
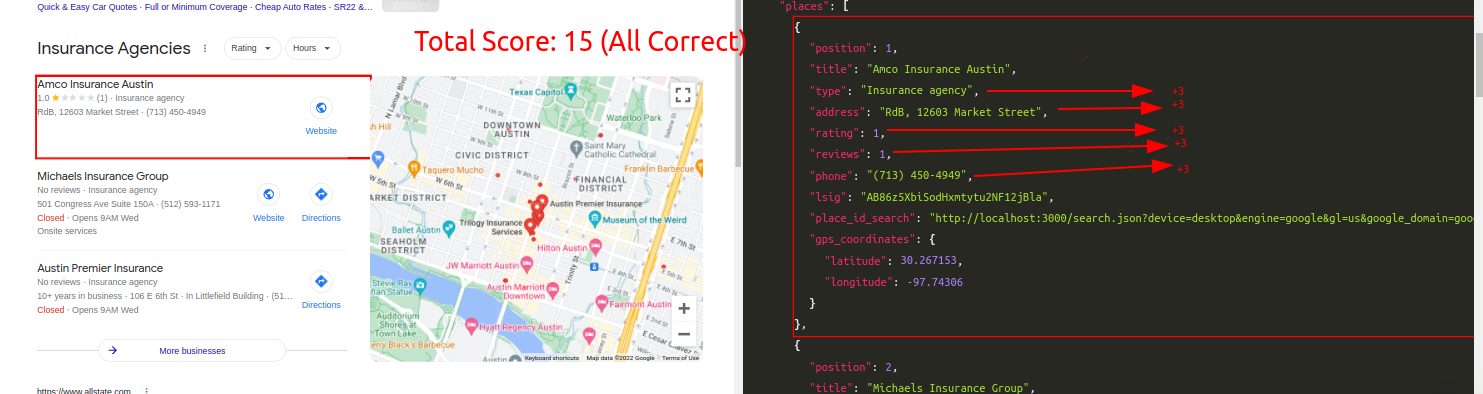
Query: Insurance AgencyTraditional Parser Score: -6ML-Hybrid Parser Score: 11
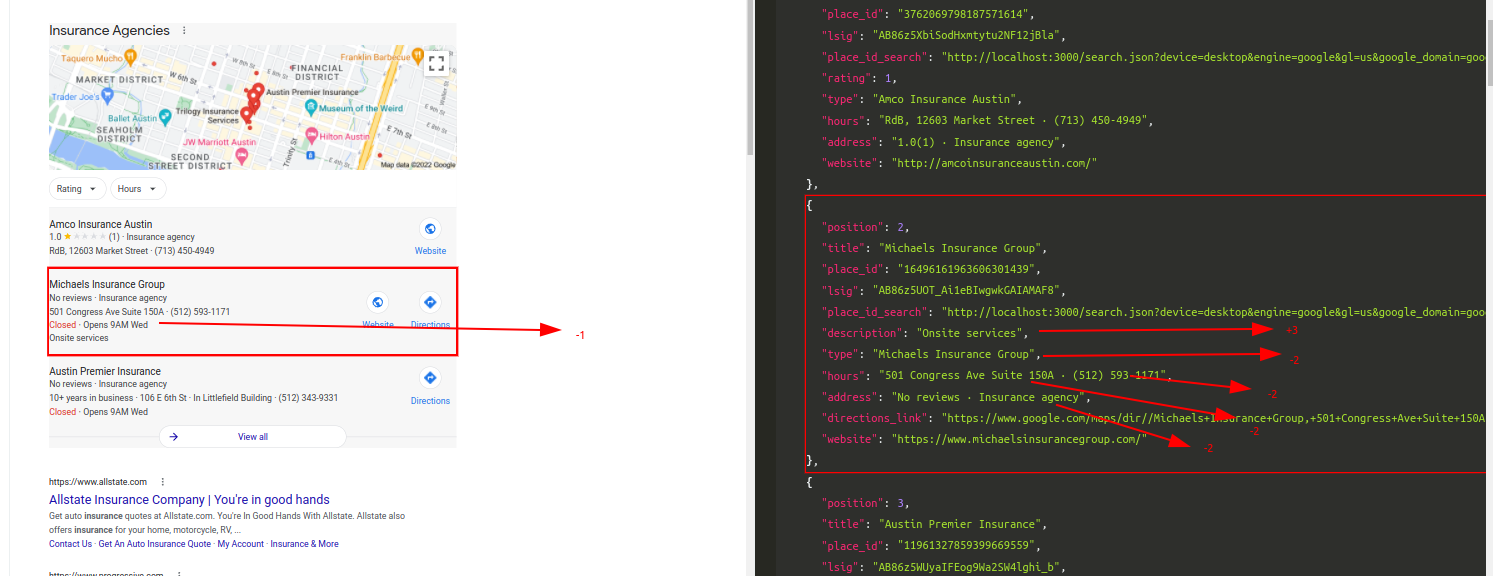
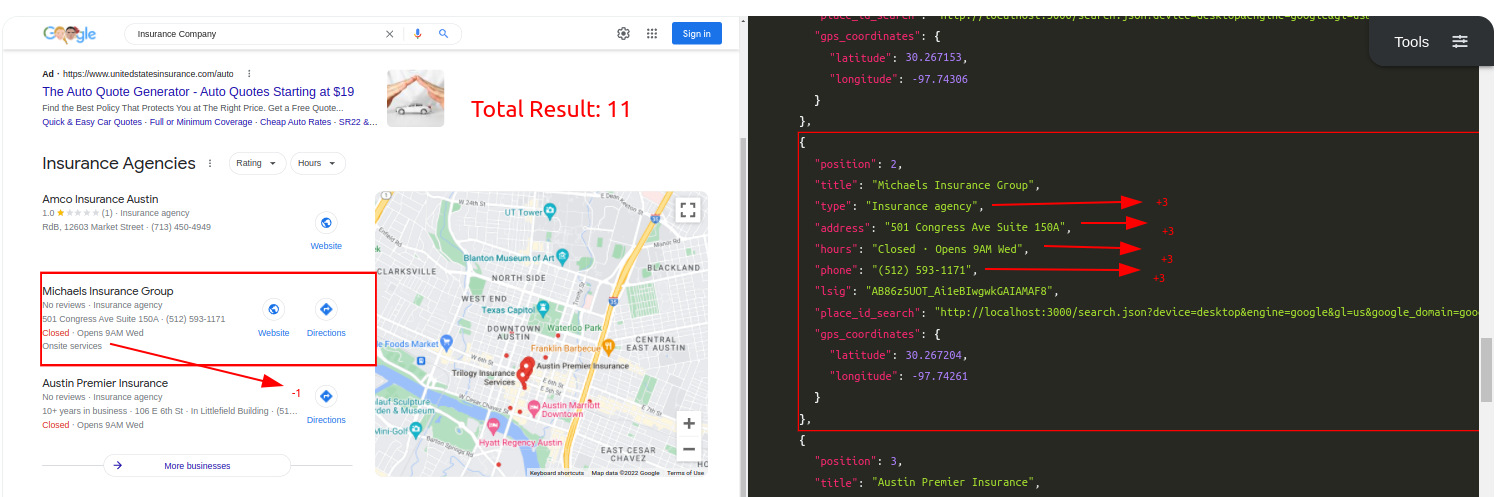
Query: Insurance AgencyTraditional Parser Score: -9ML-Hybrid Parser Score: 12 (All Correct)
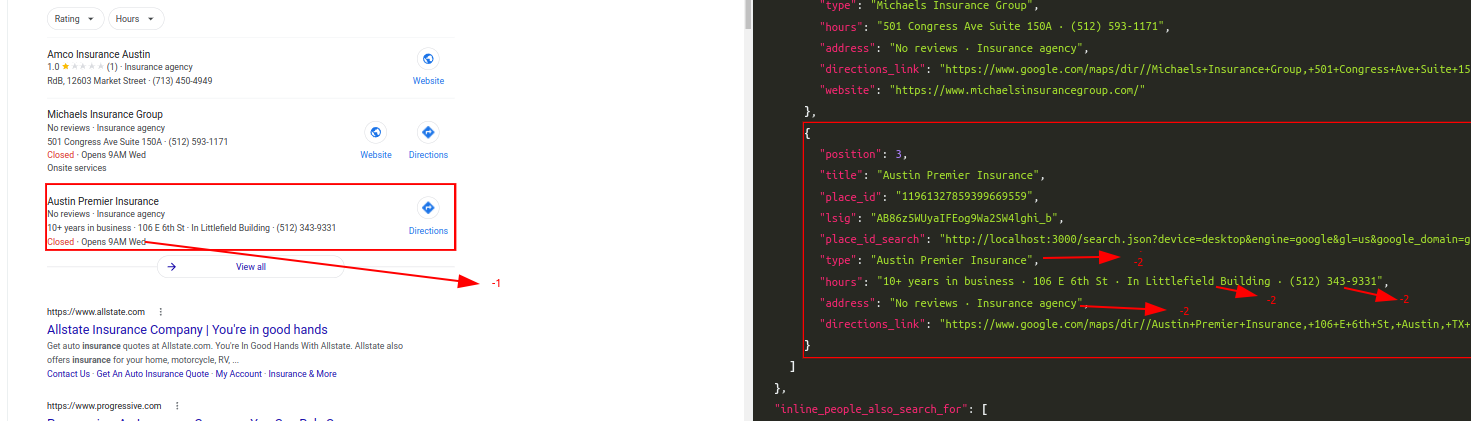
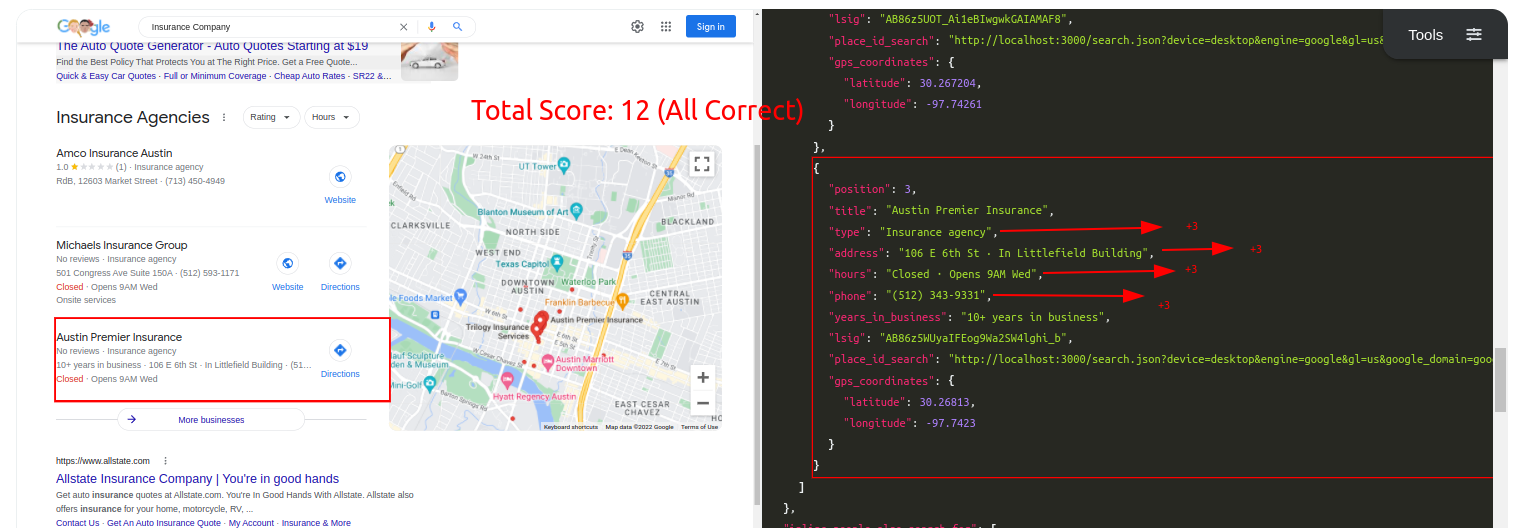
Query: CoffeeTraditional Parser Score: -9ML-Hybrid Parser Score: 15 (All Correct)
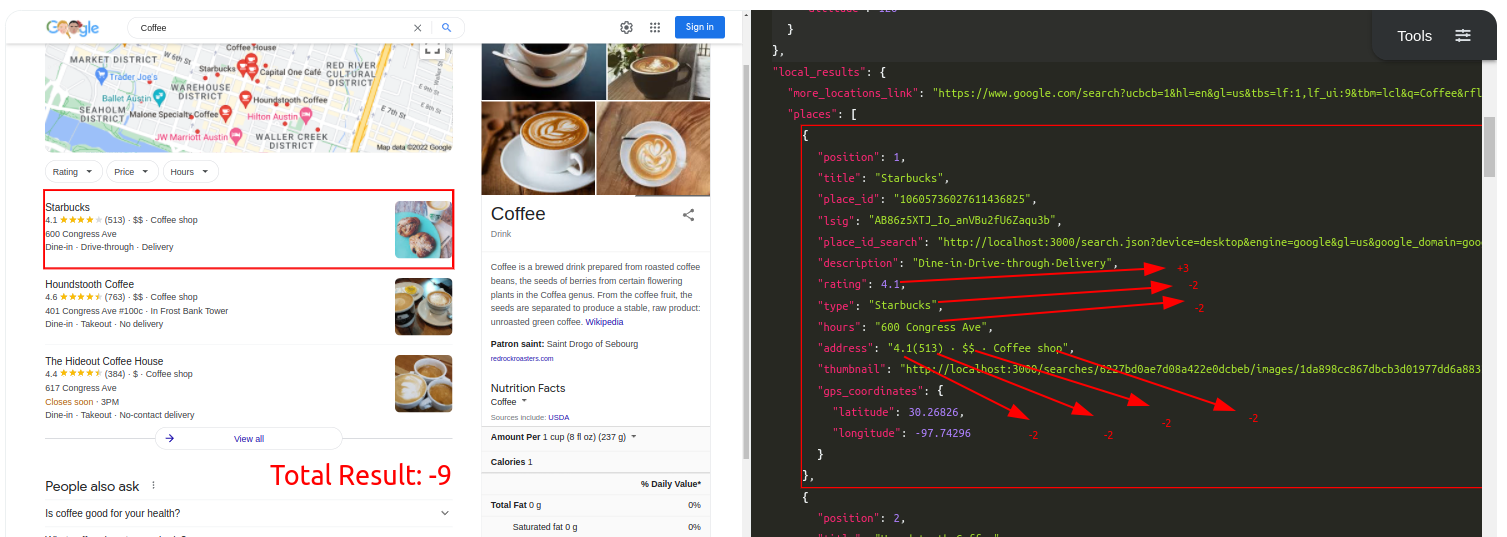
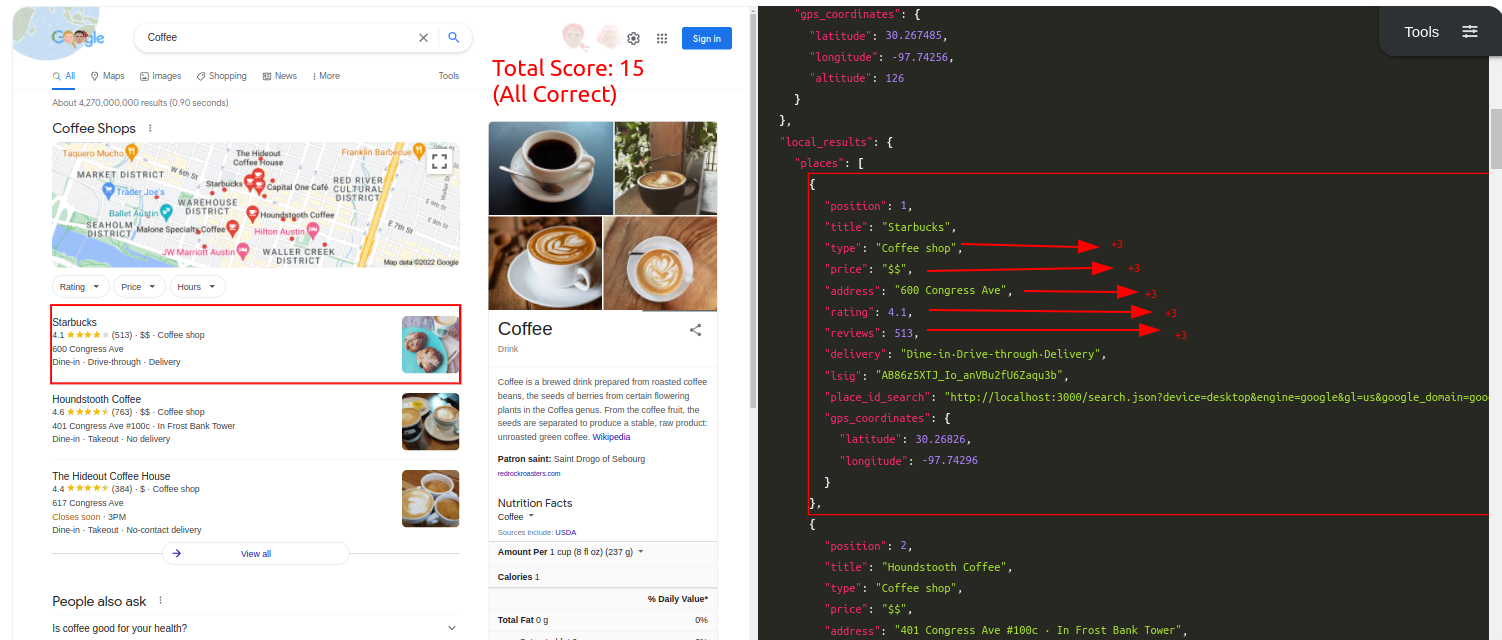
Query: CoffeeTraditional Parser Score: -12ML-Hybrid Parser Score: 15 (All Correct)
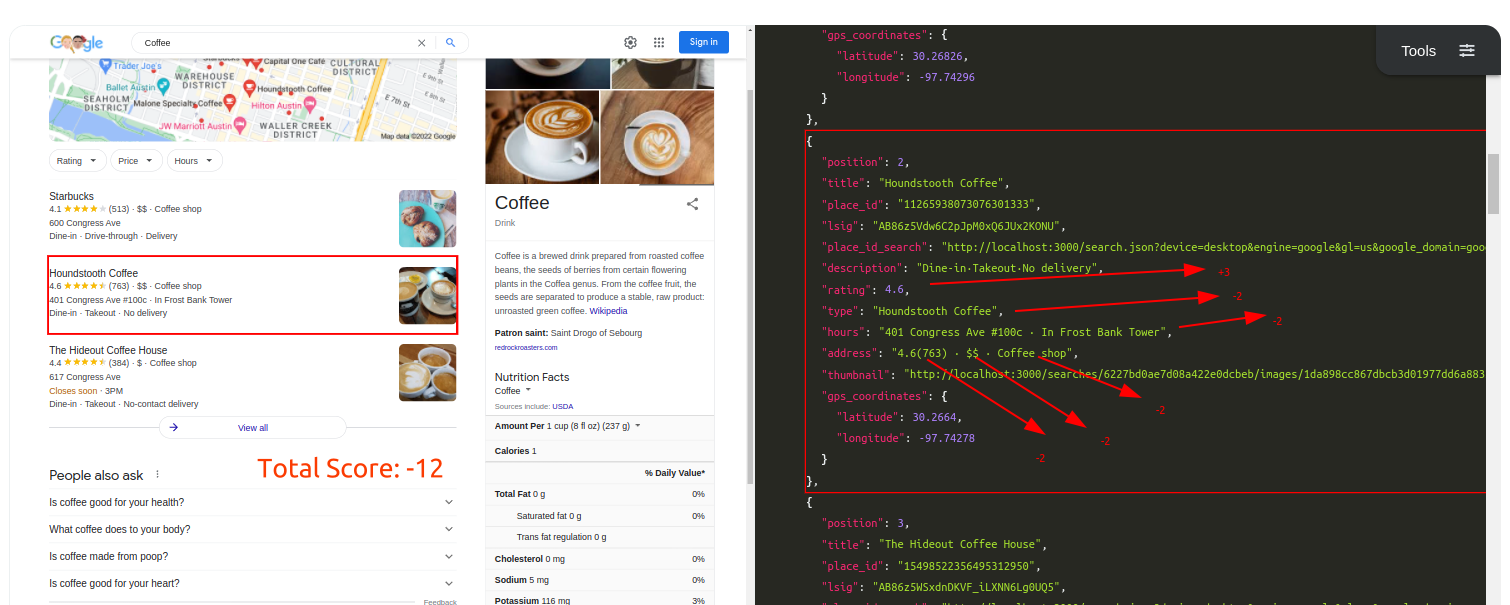
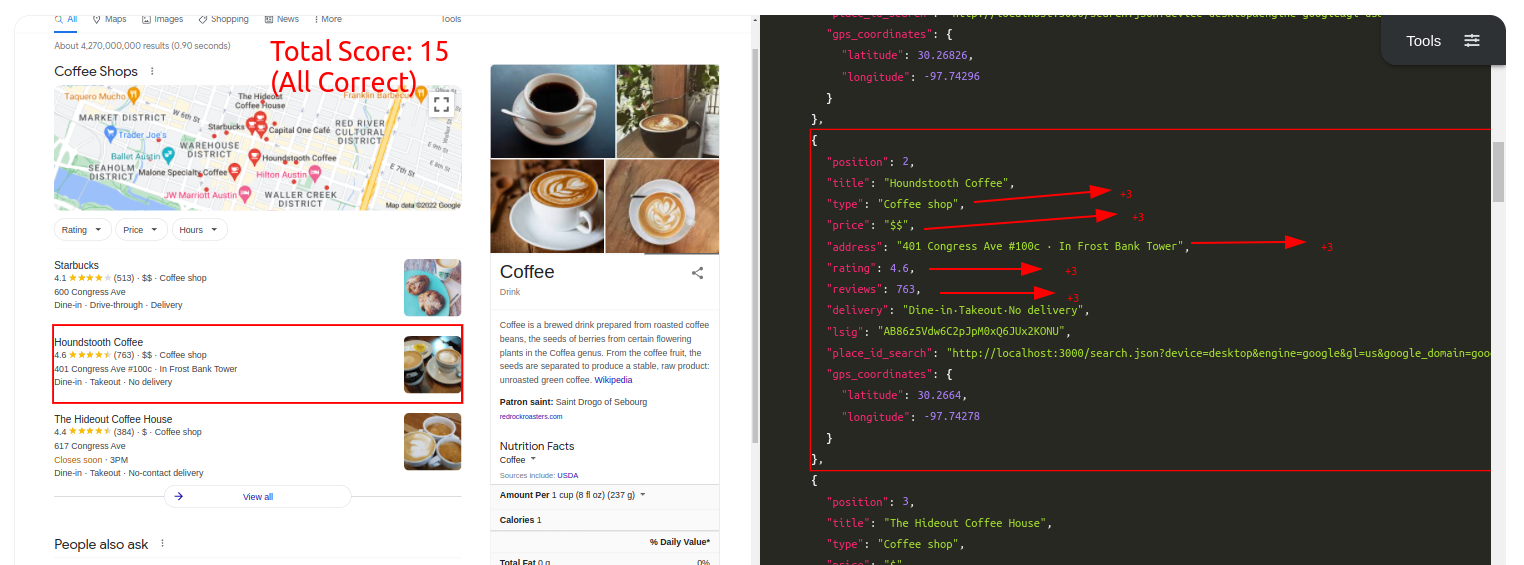
Query: CoffeeTraditional Parser Score: -8ML-Hybrid Parser Score: 18 (All Correct)
How ML-Hybrid Parser works?
First of all, I must state that I didn't expand the vocabulary used to sustain n-gram classifier model behind the parser yet. I wanted to see how it performs with low level data feed, and where it goes rogue. This means it could be improved in the future.
Two core benefits from the ML model are:
- It can predict a single string
- It can decide if a string should be divided from a separator (with minor deviancy cases that are being handled like the traditional parser)
The way it decides if a string should be divided is simple:
- It divides the string from specified points and gets the maximum output probability of prediction of each separated text. What does it mean:
It means that if you give the model a string it gives you an output as an array consisting of different float numbers. The size of the array is the number of targeted keys you want to predict. This array consists of floats that represent probability values, and the index of the maximum of these floats will give you the key you want to predict. However, right now we are interested in the value of the maximum of these floats.
Ex: output for "5540 N Lamar Blvd #12" = [0.6, 0.4]
output for "Austin, TX 78756" = [0.8, 0.2] - The model takes the average of these maximum probability values
Ex: average output for separation = (0.6 + 0.8)/2 = 0.7 - Then, it takes the maximum probability output of combined text
Ex: output for "5540 N Lamar Blvd #12 ⋅ Austin, TX 78756" = [0.9, 0.1] - Finally it compares both to make a decision if it is wiser to split the text. Since
0.9is greater than0.7, it'll choose not to split the text. Notice that all three texts would give usaddresskey.
In addition to these, the main difference from a traditional parser is how it gathers the texts in the first place.
In traditional parser you have a definite set of objectives in which you navigate through different conditions to parse the element you require. ML-Hybrid is supported with many regex conditions too. However, in the end it is a mesh of text, and a race for a key. It is useful for two things:
- You don't have to write a complex parser for a single key, initial parser will likely be enough.
- You don't have to update CSS targets or go through a mix of conditions, you can update the keys and retrain the model with two simple commands if a new key appears. You don't have to do it in old keys.
Conclusion
This blog post is definite proof that ML-Hybrid model can be applied for parsing purposes with much more efficiency, and sustainability.
I'd like to thank the reader for the attention, and I'd like to thank the brilliant people of SerpApi for all their support in carrying the flag in new fields, even in these trying times.
Next week, we'll talk about how we'll further improve the model, comparison benchmarks for runtimes, and also General Testing Purposes for Machine Learning.