 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

Monitoring when competitors begin ranking for new keywords can reveal product launches and marketing strategy changes. Instead of manually checking search results every day, you can automate the process with a Slack bot that sends alerts whenever a new company appears for keywords that matter for your brand.
In this tutorial, we’ll build a simple system that:
- Checks search results using the SerpApi's Google Search API.
- Detects when a competitor domain appears for a tracked keyword and sends an alert to a Slack channel.
- Run this process everyday using Python's schedule library.
Setting Up
This system will work in four steps:
- Send in requests to SerpApi's Google Search API for a list of relevant queries
- Extract all indexed pages
- Compare them with previously stored URLs
- Send alerts to Slack for new pages detected
We'll run this job every day using the Python schedule library. You can set the schedule as you like.
To start, you’ll need:
- A SerpApi account
- A Slack workspace (and a Slack Incoming Webhook URL)
- Python installed
Create a Slack webhook
- Go to Slack → Apps
- Search for Incoming Webhooks
- Create a webhook for your channel
You will get a Webhook URL like: https://hooks.slack.com/services/XXXX/XXXX/XXXX
Save this, as we'll need it later.
Code related setup steps
For this tutorial, we're going to use SerpApi's new Python library to get results from search.
- Install SerpApi's new Python
serpapilibrary, the python-dotenv library, tldextract library (for parsing the domains from URLs), and the schedule library in your environment:
pip install serpapi python-dotenv schedule tldextractserpapi is our new Python library. You can use this library to scrape search results from any of SerpApi's APIs.More About Our Python Libraries
We have two separate Python libraries serpapi and google-search-results, and both work perfectly fine. We are in the process of deprecating google-search-results, so I recommend using serpapi as that is our latest python library.
You may encounter issues if you have both libraries installed at the same time. If you have the old library installed and want to proceed with using our new library, please follow these steps:
- Uninstall
google-search-resultsmodule from your environment. - Make sure that neither
serpapinorgoogle-search-resultsare installed at that stage. - Install
serpapimodule, for example with the following command if you're usingpip:pip install serpapi
- To begin scraping data, create a free account on serpapi.com. You'll receive 250 free search credits each month to explore the API. Get your SerpApi API Key from this page.
- [Optional but Recommended] Set your API key in an environment variable, instead of directly pasting it in the code. Refer here to understand more about using environment variables. For this tutorial, I have saved the API key in an environment variable named "SERPAPI_API_KEY" in my .env file.
- [Optional but Recommended] Set up your Slack Webhook URL as an an environment variable as well. In your
.envfile, this will look like this:
SERPAPI_API_KEY=<YOUR PRIVATE API KEY>
SLACK_WEBHOOK_URL=<YOUR PRIVATE WEBHOOK URL>- Import classes needed for this project at the beginning of your code file and set up some constants we'll use later on:
import os
import serpapi
import requests
import json
import schedule
import time
import tldextract
from dotenv import load_dotenv
load_dotenv()
SERPAPI_KEY = os.environ["SERPAPI_API_KEY"]
queries = [] # List of queries for which you want to find the updated domains
DB_FILE = "known_domains.json"
SLACK_WEBHOOK = os.environ["SLACK_WEBHOOK_URL"]Provide the value of your slack webhook in the SLACK_WEBHOOK variable. It looks something like this: https://hooks.slack.com/services/XXXX/XXXX/XXXX.
Provide a list of queries you're looking to track competitors with. Example: ["ai images tool", "ai image generators", "image creation ai tools"]
Get all indexed domains for a list of queries
For the purpose of this post, we'll consider the first 30 organic results and use a simple list of 3 queries. You can increase or decrease this number as needed and change the queries as well depending on your use case.
A simple function to get the root domain from the URL using the tldextract library we installed earlier:
def get_root_domain(url):
extracted = tldextract.extract(url)
# Join the domain and suffix to get the root domain
return f"{extracted.domain}.{extracted.suffix}"Now, let's create a script com get_domains.py where we use SerpApi 's Google Search API to get the domains of the first 30 search results for a particular query.
def get_all_domains(query_list):
domains_for_each_query = {}
client = serpapi.Client(api_key=SERPAPI_KEY)
for query in query_list:
domains_for_each_query[query] = set()
for start in range(0, 30, 10):
results = client.search({
"engine": "google",
"google_domain": "google.com",
"q": query,
"start": start
})
if "organic_results" not in results:
break
for result in results["organic_results"]:
link = result.get("link")
if not link:
continue
root_domain = get_root_domain(link)
domains_for_each_query[query].add(root_domain)
return {k: list(v) for k, v in domains_for_each_query.items()}
This function sends a request to SerpApi's Google Search API and collects the root domains from the organic result links, and stores them per query. It uses a set to keep only unique domains and fetches up to the first 30 results (pagination with start). It returns a dictionary mapping each query to a list of unique domains found in the search results.
Save known domains
For the purpose of this example, let's assume the file known_domains.json stores all previously stored pages in JSON format. So, we now need to compare with the domains in this file to find newly added ones.
known_domains.json file will be empty. Next time, when you use the script, you'll only see the new ones added.Let's write some code to load the URLs from the file and save the new URLs to the file which we can use later on:
def load_domains():
try:
with open(DB_FILE) as f:
return dict(json.load(f))
except Exception:
return {}
def save_domains(domains):
with open(DB_FILE, "w") as f:
json.dump(domains, f)Send slack alerts
Let's write a simple function to send slack alerts for any new domains seen for each query. We'll use this later.
def send_slack_alert(domains):
# Filter out keys with no new values
domains = {k: v for k, v in domains.items() if v}
if not domains:
message = {
"text": "✅ No new companies detected for any query."
}
requests.post(SLACK_WEBHOOK, json=message)
return
for query in domains:
if domains.get(query) != []:
message = {
"text": f"🚨 New company detected for '{query}':\n" +
"\n".join(domains[query])
}
print(message)
requests.post(SLACK_WEBHOOK, json=message)
Once everything is set up, your Slack channel will receive alerts like this once a day if new domains detected for any query:
🚨 New company detected for 'image creation ai tools':
company1.com
company2.com
Detect new pages
Now let's work on code to specifically detect new pages by looking at already stored ones in known_domains.json.
def check_for_new_domains():
print("Checking for new domains...")
known_domains = load_domains()
current_domains = get_all_domains(QUERY_LIST)
new_domains = {}
for query in current_domains:
new_domains[query] = list(
set(current_domains[query]) - set(known_domains.get(query, []))
)
known_domains[query] = list(
set(known_domains.get(query, [])) | set(current_domains[query])
)
send_slack_alert(new_domains)
save_domains(known_domains)This function checks the search results for new domains appearing for each query compared to previously stored domains. It computes the difference between current domains and known domains, sends a Slack alert for any new ones, and then updates the stored list with the latest domains.
Run the bot on a schedule
Now the only thing left is to schedule this so it runs once everyday.
To do this, we'll use Python's schedule library.
# Schedule the bot to run every day at 9 AM
schedule.every().day.at("09:00").do(check_for_new_domains)
print("Query domain monitoring bot running...")
while True:
schedule.run_pending()
time.sleep(60)To keep the tasks running even after you close your terminal or IDE, you can choose to run the script as a persistent background process. For linux/macOS, use nohup or disown to detach the script from the terminal, e.g., python3 script.py & disown.
What the alert looks like
I ran the code twice with QUERY_LIST = ["ai images tool", "ai image generators", "image creation ai tools"]
The first time, I got some new pages (because a few new companies started ranking for the queries since when I ran it last)
The next time, since all the webpages were already seen, I got a message letting me know that no new pages were detected.
These were the alerts I received:
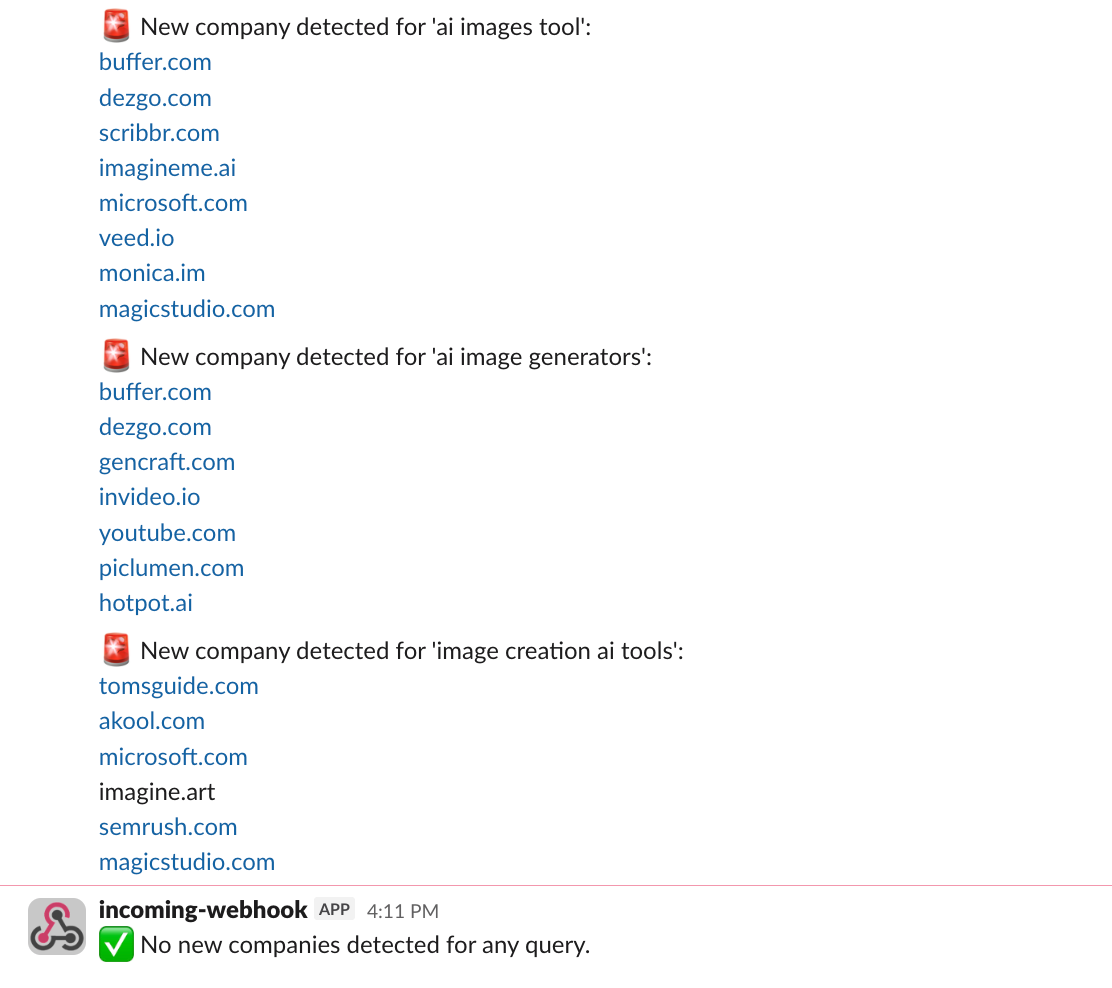
Now your team will instantly know when new companies start ranking for important keywords that matter for your brand.
Possible Enhancements
Once the basic setup works, you can extend it for a couple more use cases:
- Track ranking changes: Alert when a domain jumps from page 2 -> page 1
- Monitor multiple regions: Use different location parameters
- Track different features: Monitor if competitors appear in other parts of SERP like featured snippets, shopping results, and knowledge panels
Conclusion
By combining SerpApi, Slack, and a Python script, you can build a lightweight monitoring system that continuously tracks competitor activity in search.
With this, you’ll have a practical developer tool that saves hours of manual SERP monitoring and helps your team react faster to competitive changes. You can also use this tutorial to setup any other recurring tasks and send notifications to the slack channel.
You can find the entire code here:
Feel free to reach out to us at contact@serpapi.com for any questions.