 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

In the dynamic landscape of digital content creation there are many challenges related to delivering relevant and engaging episodes that resonate with the target audience. Traditional brainstorming is great to get started, but often falls short of providing a comprehensive understanding of what the audience is interested in, or has questions about.
This post explores how to use SerpApi to automate collecting data from various sources like Google Search, Google Trends, and Google News to strategize podcast content and unearth valuable insights to optimize episode planning.
Why Use SerpApi?
To sustain audience growth and increase engagement, it's likely important to understand your audience's pain points, identify trending topics, and anticipate what information is relevant to attract new listeners. All this information is available on search engines and can be scraped using SerpApi.
SerpApi manages the intricacies of scraping and returns structured JSON results, which allows you to save time and effort. We take care of proxies and any CAPTCHAs that might be encountered, so that you don't have to worry about your searches being blocked.
We also do all the work to maintain all of our parsers. This is important, as Google and other search engines are constantly experimenting with new layouts, new elements, and other changes. By taking care of this for you on our side, we eliminate a lot of time and complexity from your workflow.
Goal
We'll explore how we can strategically turn the vast expanse of online search queries and information into a rich source of actionable data points for podcasts. To do this, we will use SerpApi's (using Python) to access search results in JSON format. In this blog post, we'll extract lots of data from search engines using SerpApi to perform a variety of analysis:
- Identify high intent questions through the People Also Ask section in Google Search results
- Explore adjacent areas of interest via the Related Searches section in Google Search results
- Gauge topic popularity using Google Trends data
- Get latest developments from Google News
SerpApi offers multiple APIs to gather this information. We're going to use Google Search API, Google Trends API, and Google News API to gather all of this information. Using these APIs, you can automate the process of collecting this information by creating a script to get a podcast content strategy report on any topic of your choosing.
I'll go over each one below.
Getting Started With Using SerpApi
You can use our APIs in multiple languages, but for the purposes of this blog post, I'm going to be using Python.
To begin scraping data, first, create a free account on serpapi.com. You'll receive one hundred free search credits each month to explore the API.
- Get your SerpApi API Key from this page.
- [Optional but Recommended] Set your API key in an environment variable, instead of directly pasting it in the code. Refer here to understand more about using environment variables. For this tutorial, I have saved the API key in an environment variable named "SERPAPI_API_KEY" in my .env file.
- Next, on your local computer, you need to install the
google-search-resultsPython library:pip install google-search-results
You can use this library to scrape search results from any of SerpApi's APIs.
More About Our Python Libraries
We have two separate Python libraries serpapi and google-search-results, and both work perfectly fine. However, serpapi is a new one, and all the examples you can find on our website are from the old one google-search-results. If you'd like to use our Python library with all the examples from our website, you should install the google-search-results module instead of serpapi.
For this blog post, I am using google-search-results because all of our documentation references this one.
You may encounter issues if you have both libraries installed at the same time. If you have the old library installed and want to proceed with using our new library, please follow these steps:
- Uninstall
google-search-resultsmodule from your environment. - Make sure that neither
serpapinorgoogle-search-resultsare installed at that stage. - Install
serpapimodule, for example with the following command if you're usingpip:pip install serpapi
Identifying High Intent Questions
Google's People Also Ask section represents a direct articulation of user queries related to specific search terms. We can use SerpApi to scrape these questions for the podcast topic or related keywords to understand the questions potential listeners are seeking answers for. This will also allow us to identify recurring themes and angles to address within an episode.
Let's take the topic "AI's drawbacks" for instance for our podcast.
We'll head to our playground and search for this using our Google Search API:
Here is the response with the "People Also Ask" section:
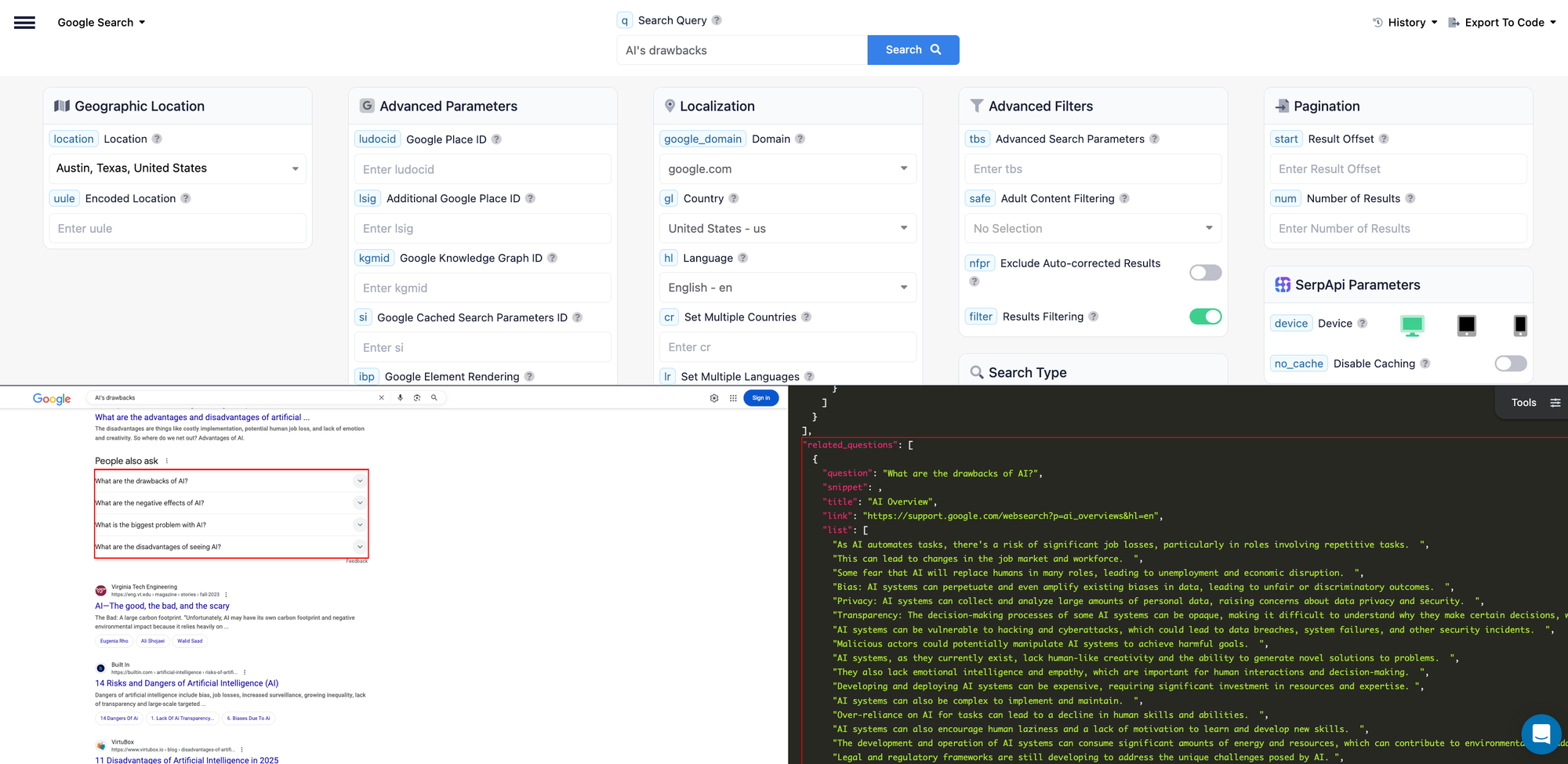
We can dig deeper and do another search for "Algorithmic bias with AI" - which is one of the common drawback of AI and see what questions come up:
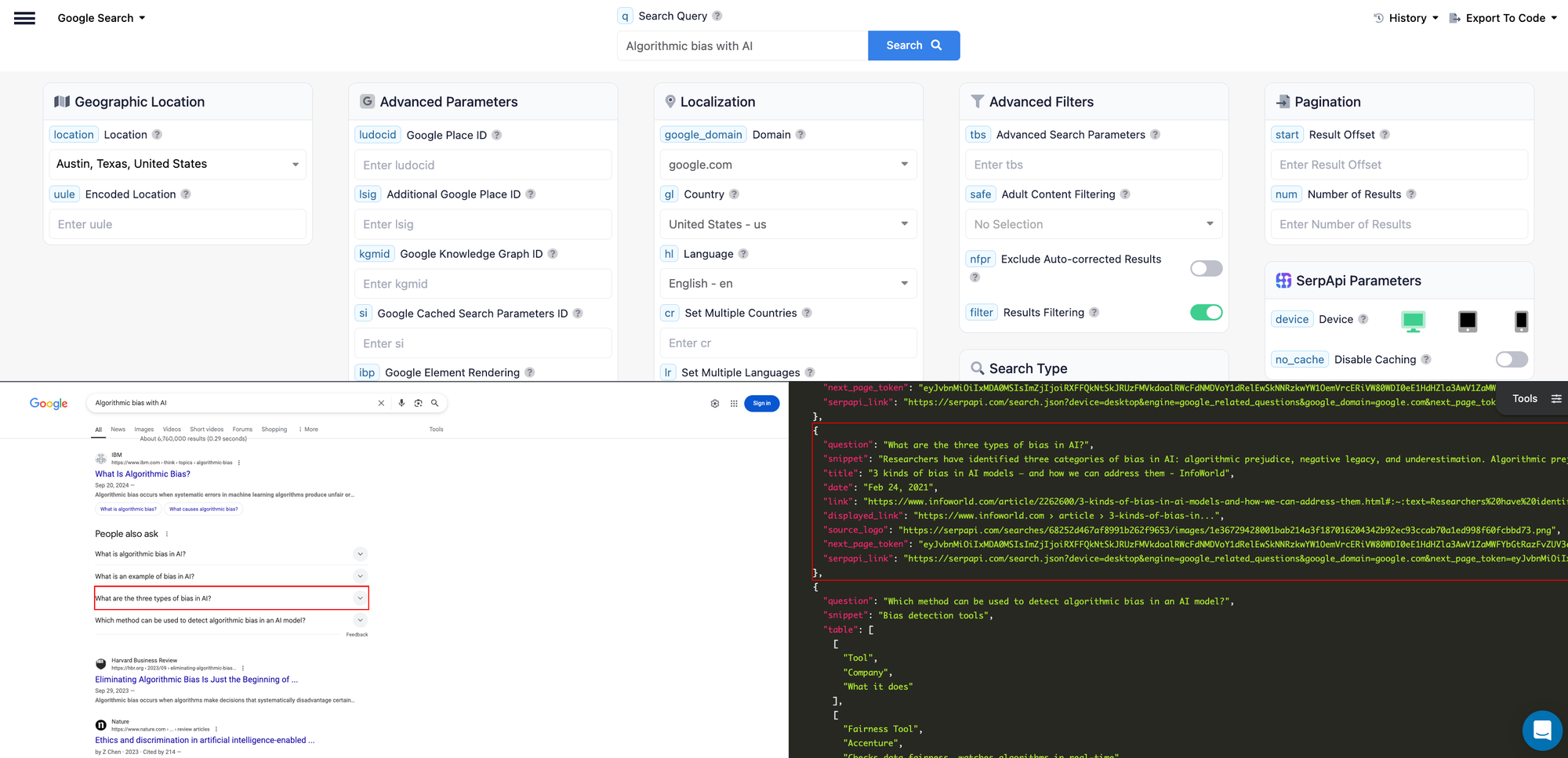
As you can see in the screenshot above, we can extract questions like "what are three types of bias in AI" or "Which method can be used to detect algorithmic bias in an AI model" and use the questions and their answers in our podcast content. This helps us understand what users want to know more about related to the topic.
Now, to get the Python code for this, you can use the "Export To Code" option in the top right of the playground, and select the language as Python.
Here is the code to run this on your end, and extract all of the related questions for any query:
from serpapi import GoogleSearch
import os, json
from dotenv import load_dotenv
load_dotenv()
api_key = os.environ["SERPAPI_API_KEY"]
params = {
"q": "AI's drawbacks",
"api_key": api_key,
"engine": "google",
"google_domain": "google.com",
"gl": "us",
"hl": "en",
"location": "Austin, Texas, United States",
"device": "desktop"
}
search = GoogleSearch(params)
results = search.get_dict()
related_questions = results["related_questions"]
for block in related_questions:
print(block["question"])
params = {
"q": "Algorithmic bias with AI",
"api_key": api_key,
"engine": "google",
"google_domain": "google.com",
"gl": "us",
"hl": "en",
"location": "Austin, Texas, United States",
"device": "desktop"
}
search = GoogleSearch(params)
results = search.get_dict()
related_questions = results["related_questions"]
for block in related_questions:
print(block["question"])Explore Adjacent Interest via Related Searches
Google's Related Searches section can reveal topics closely associated with a primary search term. For podcasters, this can uncover adjacent areas of interest within the audience, and can potentially help in leading to the expansion of content themes and attract a broader listener base. It can help identify ideas for complementary episodes or series that cater to tangential interests.
Let's consider an example of this: We'll consider the same topic "Algorithmic bias with AI" for instance for our podcast.
We'll head to our playground and search for this using our Google Search API:
Here is the response with the "Related Searches" section:
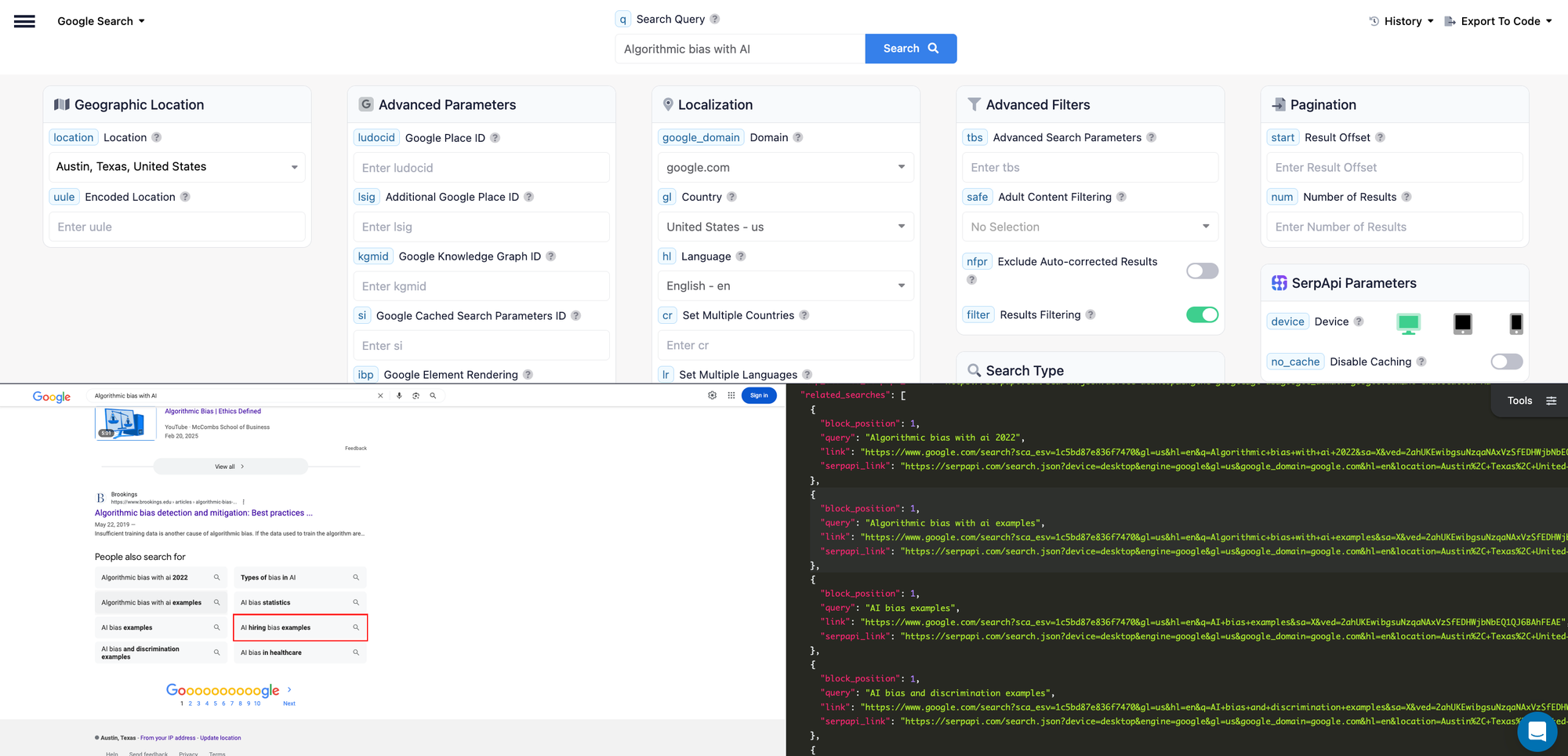
As you can see in the screenshot above, we can extract related topics people are interested in like "AI hiring bias examples" or "AI bias in healthcare" and use them as future podcast topics. This helps us understand identify complementary episode ideas.
Now, to get the Python code for this, you can use the "Export To Code" option in the top right of the playground, and select the language as Python.
Here is the code to run this on your end, and extract all of the related questions for any query:
from serpapi import GoogleSearch
import os, json
from dotenv import load_dotenv
load_dotenv()
api_key = os.environ["SERPAPI_API_KEY"]
params = {
"q": "Algorithmic bias with AI",
"api_key": api_key,
"engine": "google",
"google_domain": "google.com",
"gl": "us",
"hl": "en",
"location": "Austin, Texas, United States",
"device": "desktop"
}
search = GoogleSearch(params)
results = search.get_dict()
related_searches = results["related_searches"]
for block in related_searches:
print(block["query"])Gauge Topic Popularity Using Google Trends
After identifying key questions and related terms via our Google Search API, you can use Google Trends to analyze their search volume over time and compare their relative popularity.
For example if the search results reveal numerous questions about bias in hiring, Google Trends can show us the interest in this specific area of AI bias compared to broader terms like "AI Bias".
Let's consider an example of this: We'll consider the same topic "Algorithmic bias with AI" for instance and use our API to get Interest over time data from Google Trends for the query "AI bias,AI bias in healthcare,AI hiring bias" to compare the three.
We'll head to our playground and search for this using our Google Search API:
Here is the response with interest over time data for all three:
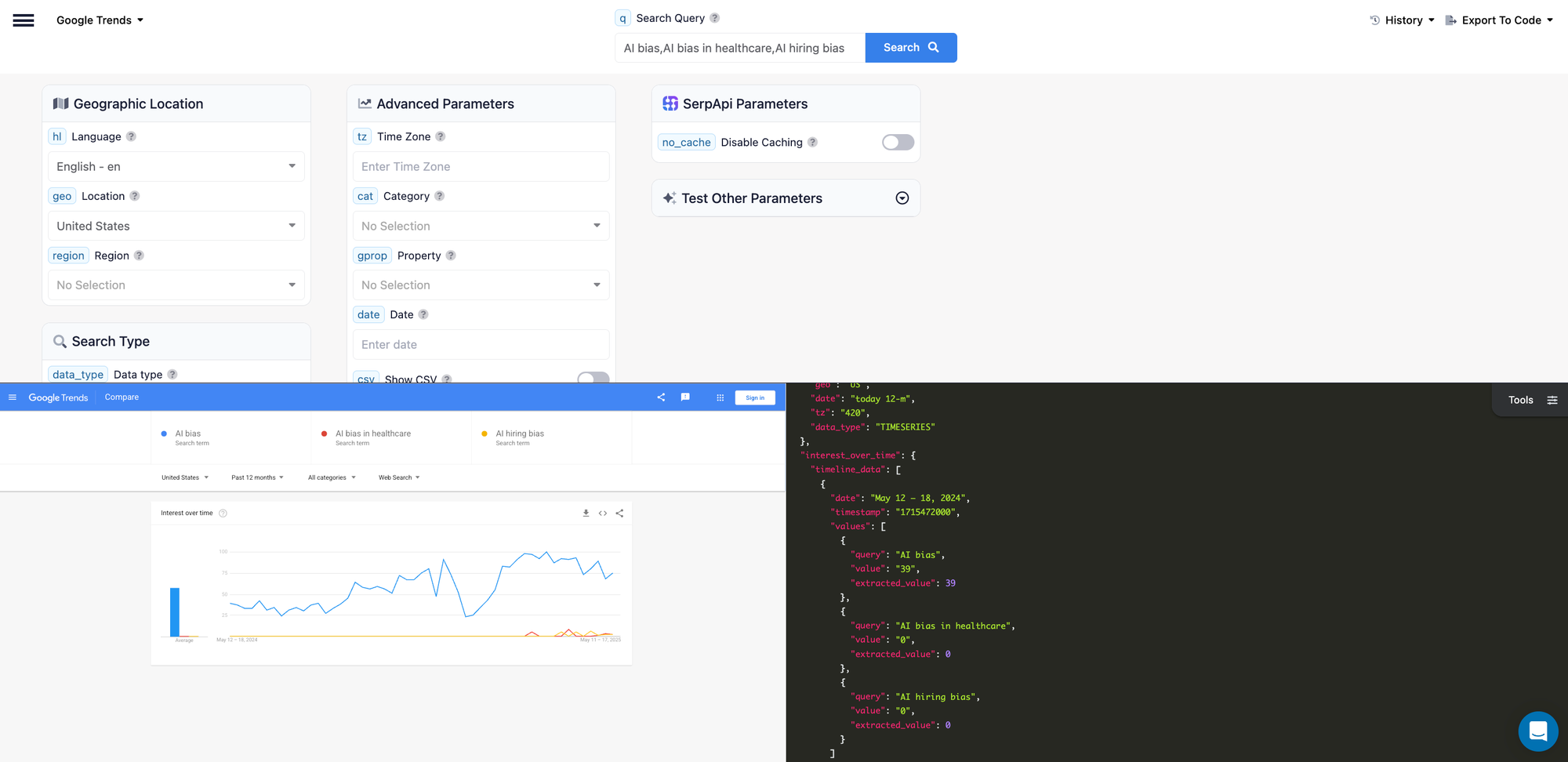
Now, to get the Python code for this, you can use the "Export To Code" option in the top right of the playground, and select the language as Python.
Here is the code to run this on your end, and extract this Google Trends data:
from serpapi import GoogleSearch
import os, json
from dotenv import load_dotenv
load_dotenv()
api_key = os.environ["SERPAPI_API_KEY"]
params = {
"api_key": api_key,
"engine": "google_trends",
"q": "AI bias,AI bias in healthcare,AI hiring bias",
"data_type": "TIMESERIES",
"hl": "en",
"geo": "US"
}
search = GoogleSearch(params)
results = search.get_dict()
# This provides two kinds of data - timeline_data and averages, which you can use depending on your use case
interest_over_time_results = results["interest_over_time"]
print(interest_over_time_results)Get latest developments from Google News
Staying current is critical for many podcasts on fast moving or changing fields like AI. SerpApi provides Google News API which can allow us to monitor breaking stories, policy changes, high profile cases, or new research which shows up on Google News.
Let's consider the same example above, and search for news related "Algorithmic Bias" such as "Algorithmic Bias lawsuit".
tbm parameter set to nws, which will return all the data from the news tab on Google Search. We'll head to our playground and search for this using our Google Search API:
Here is the response we get:
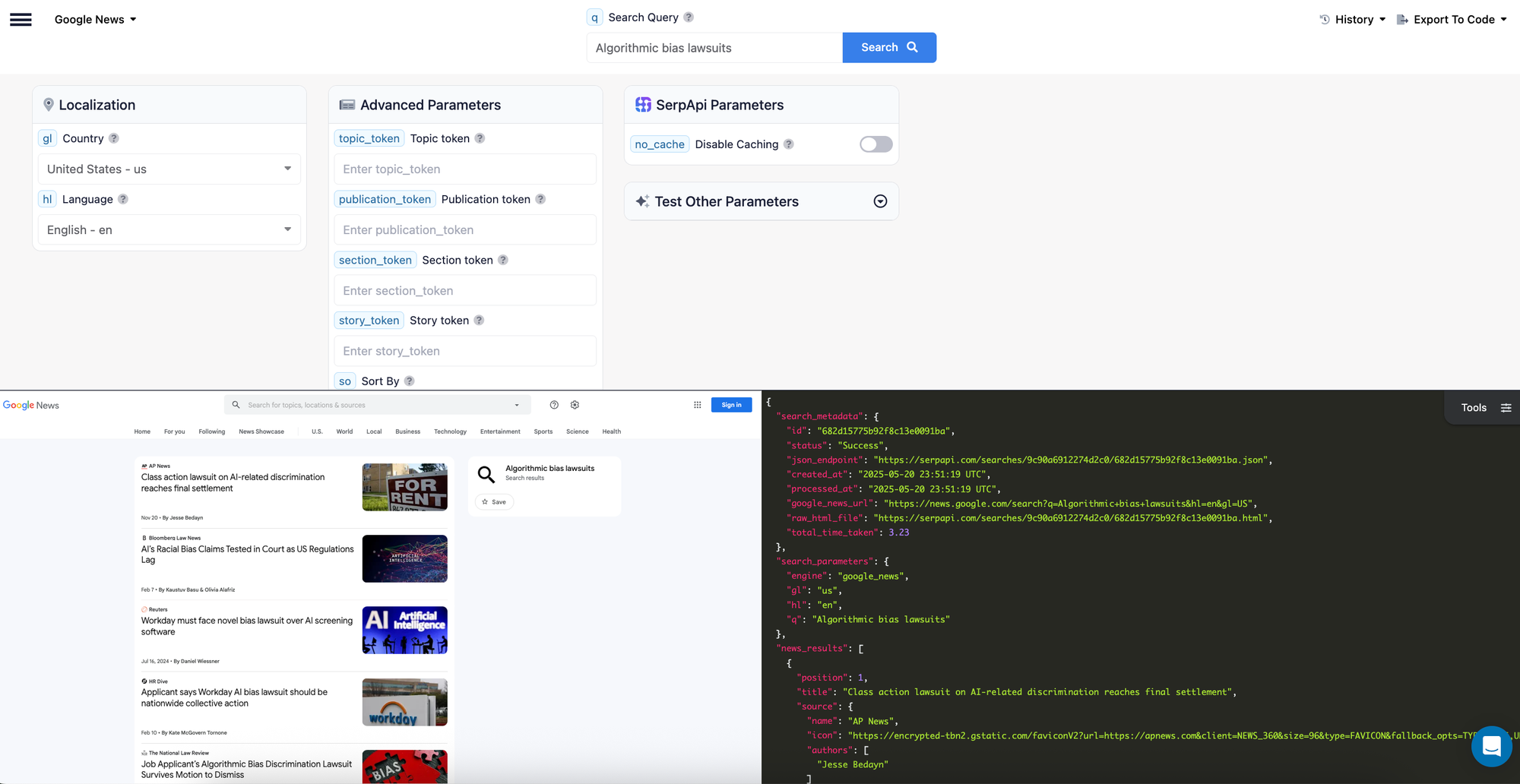
Now, to get the Python code for this, you can use the "Export To Code" option in the top right of the playground, and select the language as Python.
Here is the code to run this on your end, and extract this Google News data:
from serpapi import GoogleSearch
import os, json
from dotenv import load_dotenv
load_dotenv()
api_key = os.environ["SERPAPI_API_KEY"]
params = {
"api_key": api_key,
"engine": "google_news",
"q": "Algorithmic Bias Lawsuits",
"hl": "en",
"geo": "US"
}
search = GoogleSearch(params)
results = search.get_dict()
news_results = results["news_results"]
print(news_results)Creating an Automated Report with this Data
You can use all the code snippets above to generate a quick and detailed report for any topic of your choice. You can also use SerpApi to automate this process to collect all of this information for different topics that you are creating podcasts for.
Here is the complete code for your use: https://github.com/sonika-serpapi/automate-podcast-strategy-blogpost
Conclusion
We've explored how to leverage SerpApi to transform publicly available search data into a rich source of actionable data for podcasts. SerpApi provides a powerful tool to tap into collective curiosity and helps you effectively craft your podcast content strategy.
I hope you found this tutorial helpful to understand how to use SerpApi to automate the process of collecting lots of data at once to strategize content for podcasts. If you have any questions, don't hesitate to reach out to me at sonika@serpapi.com.
Relevant Links
Related Posts



