 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

Scraping YouTube videos enables developers and businesses to extract detailed YouTube video metadata at scale, including titles, descriptions, view counts, thumbnails, channel names, related videos, and comments/replies. It streamlines what would otherwise require complex scraping and anti‑blocking measures.

Video Tutorial
Prefer to watch a video? Enjoy this tutorial
Get your API Key
First, ensure to register at SerpApi to get your API Key. You can get 250 free searches per month. Use this API Key to access all of our APIs, including the YouTube Video API.
Available parameters
In addition to running the basic search, you can view all YouTube Video API parameters here.
How to scrape YouTube video data with Python
- Create a new
main.pyfile - Install requests with:
pip install requestsHere is what the basic setup looks like:
import requests
SERPAPI_API_KEY = "YOUR_REAL_SERPAPI_API_KEY"
params = {
"api_key": SERPAPI_API_KEY, #replace with the actual API Key
# soon
}
search = requests.get("https://serpapi.com/search", params=params)
response = search.json()
print(response)With these few lines of code, we can access all of the search engines available at SerpApi, including the YouTube Video API.
import requests
SERPAPI_API_KEY = "YOUR_SERPAPI_API_KEY"
params = {
"api_key": SERPAPI_API_KEY,
"engine": "youtube_video",
"v": "j3YXfsMPKjQ" # YouTube video ID
}
search = requests.get("https://serpapi.com/search", params=params)
response = search.json()
print(response)To make it easier to see the response, let's add indentation.
import json
# ...
# ...
# all previous code
print(json.dumps(response, indent=2))Here is the result:
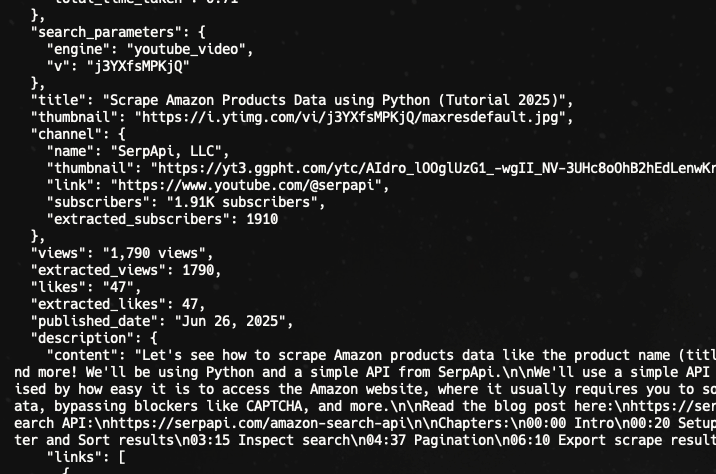
Scraping comments from a video
Here is how to scrape the comments on a video.
From the request we performed previously, you should be able to see this in the response.

We can scrape the "Top comments" or "Newest first" comments using the token that is available for each. We can put this token in the next_page_token parameter.
Here is an example:
params = {
"api_key": SERPAPI_API_KEY,
"engine": "youtube_video",
"v": "j3YXfsMPKjQ", # YouTube video ID
"next_page_token": "Eg0SC2ozWVhmc01QS2pRGAYyOCIRIgtqM1lYZnNNUEtqUTABeAIwAUIhZW5nYWdlbWVudC1wYW5lbC1jb21tZW50cy1zZWN0aW9u"
}
search = requests.get("https://serpapi.com/search", params=params)
response = search.json()
print(json.dumps(response, indent=2))Here is the result:
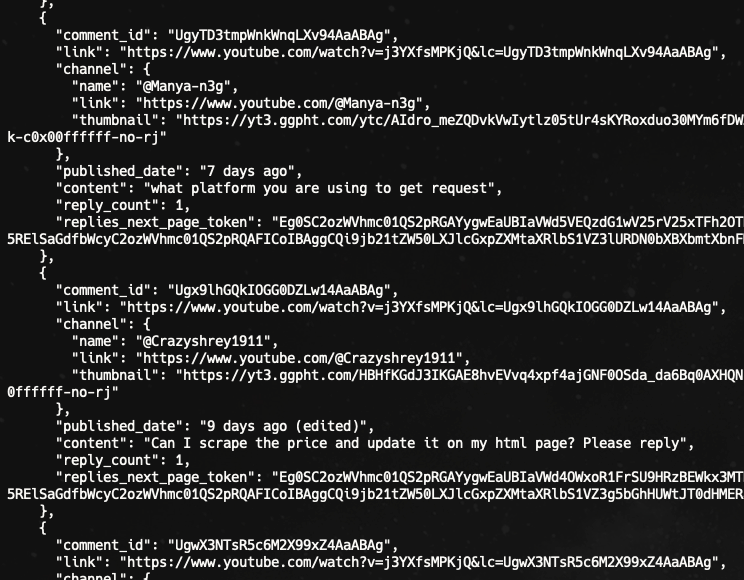
Scrape all comments
By default, YouTube shares 20 comments per page. If you want to scrape more than that, you can keep checking if comments_next_page_token is available on the response and use the token for the next request.
total_comments = len(response.get('comments', [])) # only for visual
next_page_token = response.get('comments_next_page_token')
while next_page_token:
params["next_page_token"] = next_page_token
search = requests.get("https://serpapi.com/search", params=params)
response = search.json()
total_comments += len(response.get('comments', []))
next_page_token = response.get('comments_next_page_token')
print(f"Total comments fetched: {total_comments}")In the above example, we simply show the total comments. You can do whatever you want with the comments inside the loop.
Scraping replies
If you're interested in scraping the reply on the comment, you can repeat the same action, but this time using the replies_next_page_token.
Bonus
You can also scrape YouTube search results using our YouTube Search API. Here is the Python tutorial:

You can check this tutorial if you're interested in scraping YouTube Video Transcript using programming languages like Python or Javascript.
Why Use It?
- Real‑time data: Fetch up‑to‑date video details.
- Rich metadata access: Retrieve comments and nested replies, related videos, and viewer stats in one request.
- Automated proxy and captcha handling: SerpApi manages the complexities of scraping so you can focus on analysis.
Key Features
| Feature | Benefit |
|---|---|
| Comprehensive video metadata | Includes title, description, duration, chapters, views, publishing date, channel, thumbnails |
| Comments & replies | Access nested comments for engagement analysis |
| Related videos | Discover context and competition around a video |