 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

Have you ever wondered how some businesses seem to know precisely when to drop their prices, launch a new product, or pivot into a new category? It often feels like they have a crystal ball. But the truth is, they don't - they just know how to use data. And regarding product data, there's no bigger goldmine than Amazon.
Why does this matter to you?
Over one million Amazon sellers already use API-powered tools for automation. Whether it's competitive intelligence, spotting trending products, or finding new opportunities, APIs make it possible to act quickly and confidently.
In this post, I want to take you on a journey into how you can use SerpApi's Amazon Search API to uncover insights that give you a serious competitive edge.
Along the way, I'll share relatable scenarios, ask you questions, and even walk through some step-by-step code examples so you can put this into practice right away.
Competitor Tracking: Are You Falling Behind Without Knowing It?
Let's start with a simple question: What are your competitors doing today? Not last week, not last month, but right now. If you sell products online, competitors can change prices, run flash sales, or suddenly gain traction with reviews at any moment.
Imagine this:
You run a mid-sized electronics shop. Last week, you launched a Bluetooth speaker. It's doing okay, but suddenly sales dipped. Why? Because a competitor dropped their price overnight and picked up 200 glowing reviews in just a few days.
Without tracking, you're blind. With SerpApi, you're not.
Here's a quick Python example:
from serpapi import GoogleSearch
import json
def extract_amazon_data(api_key, search_term):
"""
Extract titles, prices, and review counts from Amazon search results using SerpApi
Args:
api_key (str): Your SerpApi API key
search_term (str): The search term for Amazon products
Returns:
list: List of dictionaries containing product information
"""
# Set up search parameters
params = {
"api_key": api_key,
"engine": "amazon",
"k": search_term
}
# Perform the search
search = GoogleSearch(params)
results = search.get_dict()
# Extract product data
products = []
# Check if organic results exist
if "organic_results" in results:
for item in results["organic_results"]:
product_data = {}
# Extract title
if "title" in item:
product_data["title"] = item["title"]
# Extract price
if "price" in item:
product_data["price"] = item["price"]
elif "price_raw" in item:
product_data["price"] = item["price_raw"]
# Extract review count
if "reviews" in item:
product_data["review_count"] = item["reviews"]
elif "rating" in item and isinstance(item["rating"], dict) and "reviews" in item["rating"]:
product_data["review_count"] = item["rating"]["reviews"]
# Only add products that have at least a title
if "title" in product_data:
products.append(product_data)
return products
def print_products(products):
"""
Print the extracted product information in a formatted way
Args:
products (list): List of product dictionaries
"""
print(f"\nFound {len(products)} products:\n")
print("-" * 80)
for i, product in enumerate(products, 1):
print(f"Product {i}:")
print(f" Title: {product.get('title', 'N/A')}")
print(f" Price: {product.get('price', 'N/A')}")
print(f" Review Count: {product.get('review_count', 'N/A')}")
print("-" * 80)
def save_to_json(products, filename="amazon_products.json"):
"""
Save the extracted product data to a JSON file
Args:
products (list): List of product dictionaries
filename (str): Name of the output JSON file
"""
with open(filename, 'w', encoding='utf-8') as f:
json.dump(products, f, indent=2, ensure_ascii=False)
print(f"\nData saved to {filename}")
def main():
"""
Main function to run the Amazon data extraction
"""
# Your API key and search term
api_key = "your-api-key"
search_term = "Bluetooth Speakers"
print(f"Searching for: {search_term}")
print("Extracting product data...")
try:
# Extract the data
products = extract_amazon_data(api_key, search_term)
# Print the results
print_products(products)
# Save to JSON file
save_to_json(products)
# Print summary
print(f"\nSummary:")
print(f"- Total products found: {len(products)}")
print(f"- Products with prices: {sum(1 for p in products if 'price' in p)}")
print(f"- Products with review counts: {sum(1 for p in products if 'review_count' in p)}")
except Exception as e:
print(f"Error occurred: {str(e)}")
print("Please check your API key and internet connection.")
if __name__ == "__main__":
main()
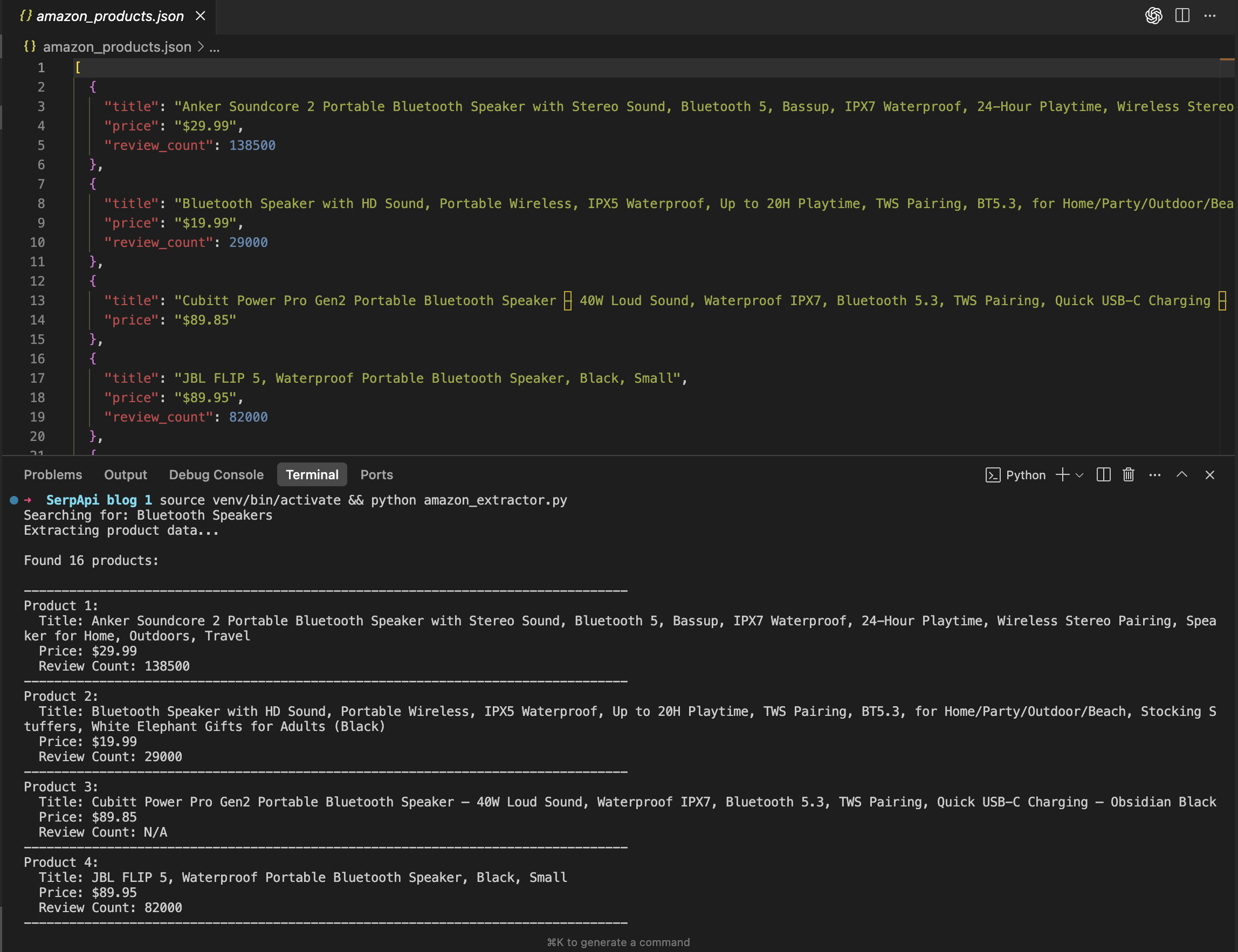
This Python file contains the function to pull live data for Bluetooth speakers, such as titles, prices, and review counts. Run this daily, log the results, and you'll spot when a competitor slashes prices or suddenly surges in reviews.
All the source code is available in this github repo.
Spotting Trending Products: What's Gaining Momentum on Amazon
Here's another question: What if you knew which products were starting to trend before everyone else did? Imagine the advantage in ad targeting, inventory planning, or content creation.
A story from the fitness niche.
Not long ago, resistance bands were the hot item in home fitness. They were simple, cheap, and everyone rushed in to sell them. But as the space became crowded, profit margins shrank. The companies that thrived were the ones that pivoted quickly, moving into higher-value categories like smart kettlebells, compact treadmills, and connected yoga mats. They didn't wait for the trend to peak; they acted when the signs first appeared.
We're seeing a similar pattern now in consumer tech. Products like portable projectors and smart air purifiers are climbing fast in both reviews and search activity. That early surge signals genuine consumer demand. The window to act is before these items become saturated because by then, margins will already be very low.
How can you do the same?
SerpApi's Amazon Search API lets you query categories like Best Sellers and see what's moving up the charts.
from serpapi import GoogleSearch
import json
import re
from typing import List, Dict, Any, Optional
from dataclasses import dataclass, asdict
from datetime import datetime
@dataclass
class ProductData:
"""Data class to store product information"""
position: int
asin: str
title: str
price: Optional[float]
rating: Optional[float]
reviews: Optional[int]
bought_last_month: Optional[str]
revenue_estimate: Optional[float]
link: str
thumbnail: str
page_found: int # Track which page the product was found on
class ImprovedSmartHomeTrendingAnalyzer:
"""Improved analyzer for Amazon Smart Home trending products with duplicate handling"""
def __init__(self, api_key: str):
self.api_key = api_key
self.smart_home_node = "6563140011" # Smart Home category node ID
def parse_quantity(self, quantity_str: str) -> int:
"""Parse quantity string like '10K+ bought in past month' to integer"""
if not quantity_str:
return 0
# Extract number and multiplier
match = re.search(r'(\d+(?:\.\d+)?)([KMB]?)\+?', quantity_str.upper())
if not match:
return 0
number = float(match.group(1))
multiplier = match.group(2)
if multiplier == 'K':
return int(number * 1000)
elif multiplier == 'M':
return int(number * 1000000)
elif multiplier == 'B':
return int(number * 1000000000)
else:
return int(number)
def calculate_revenue_estimate(self, price: float, quantity_str: str) -> float:
"""Calculate estimated revenue from price and quantity sold"""
if not price or not quantity_str:
return 0.0
quantity = self.parse_quantity(quantity_str)
return price * quantity
def extract_products_from_results(self, results: Dict[str, Any], page_num: int) -> List[ProductData]:
"""Extract and parse product data from API results"""
products = []
if "organic_results" not in results:
return products
for item in results["organic_results"]:
try:
# Extract basic information
position = item.get("position", 0)
asin = item.get("asin", "")
title = item.get("title", "")
link = item.get("link", "")
thumbnail = item.get("thumbnail", "")
# Extract price
price = None
if "extracted_price" in item:
price = item["extracted_price"]
elif "price" in item:
# Try to extract price from string like "$19.99"
price_match = re.search(r'\$?(\d+(?:\.\d+)?)', str(item["price"]))
if price_match:
price = float(price_match.group(1))
# Extract rating
rating = item.get("rating")
if rating is not None:
rating = float(rating)
# Extract review count
reviews = item.get("reviews")
if reviews is not None:
reviews = int(reviews)
# Extract quantity sold
bought_last_month = item.get("bought_last_month", "")
# Calculate revenue estimate
revenue_estimate = self.calculate_revenue_estimate(price, bought_last_month)
product = ProductData(
position=position,
asin=asin,
title=title,
price=price,
rating=rating,
reviews=reviews,
bought_last_month=bought_last_month,
revenue_estimate=revenue_estimate,
link=link,
thumbnail=thumbnail,
page_found=page_num
)
products.append(product)
except Exception as e:
print(f"Error processing product on page {page_num}: {e}")
continue
return products
def fetch_smart_home_best_sellers(self, pages: int = 3) -> List[ProductData]:
"""Fetch Smart Home best sellers from multiple pages with duplicate handling"""
all_products = []
seen_asins = set()
for page in range(1, pages + 1):
print(f"Fetching page {page}...")
params = {
"api_key": self.api_key,
"engine": "amazon",
"amazon_domain": "amazon.com",
"language": "en_US",
"s": "exact-aware-popularity-rank", # Best Sellers sort
"node": self.smart_home_node, # Smart Home category
"page": page
}
try:
search = GoogleSearch(params)
results = search.get_dict()
if "error" in results:
print(f"Error on page {page}: {results['error']}")
continue
page_products = self.extract_products_from_results(results, page)
print(f"Found {len(page_products)} products on page {page}")
# Filter out duplicates and add to main list
new_products = []
for product in page_products:
if product.asin and product.asin not in seen_asins:
seen_asins.add(product.asin)
new_products.append(product)
elif product.asin in seen_asins:
print(f"Duplicate found: {product.asin} on page {page}")
all_products.extend(new_products)
print(f"Added {len(new_products)} new products from page {page}")
except Exception as e:
print(f"Error fetching page {page}: {e}")
continue
return all_products
def rank_by_reviews(self, products: List[ProductData]) -> List[ProductData]:
"""Rank products by number of reviews (descending)"""
return sorted(products, key=lambda x: x.reviews or 0, reverse=True)
def rank_by_rating(self, products: List[ProductData]) -> List[ProductData]:
"""Rank products by rating (descending)"""
return sorted(products, key=lambda x: x.rating or 0, reverse=True)
def rank_by_revenue(self, products: List[ProductData]) -> List[ProductData]:
"""Rank products by estimated revenue (descending)"""
return sorted(products, key=lambda x: x.revenue_estimate or 0, reverse=True)
def rank_by_trending_score(self, products: List[ProductData]) -> List[ProductData]:
"""Rank products by a composite trending score"""
def calculate_trending_score(product: ProductData) -> float:
# Normalize and weight different factors
rating_score = (product.rating or 0) * 20 # 0-100 scale
review_score = min((product.reviews or 0) / 1000, 100) # Cap at 100
revenue_score = min((product.revenue_estimate or 0) / 10000, 100) # Cap at 100
# Weight the scores (rating 40%, reviews 30%, revenue 30%)
return (rating_score * 0.4) + (review_score * 0.3) + (revenue_score * 0.3)
return sorted(products, key=calculate_trending_score, reverse=True)
def print_ranking(self, products: List[ProductData], title: str, limit: int = 10):
"""Print a formatted ranking of products"""
print(f"\n{'='*80}")
print(f"{title}")
print(f"{'='*80}")
for i, product in enumerate(products[:limit], 1):
print(f"\n{i}. {product.title[:60]}...")
print(f" ASIN: {product.asin}")
print(f" Page: {product.page_found}, Position: {product.position}")
print(f" Price: ${product.price:.2f}" if product.price else " Price: N/A")
print(f" Rating: {product.rating:.1f}/5.0" if product.rating else " Rating: N/A")
print(f" Reviews: {product.reviews:,}" if product.reviews else " Reviews: N/A")
print(f" Sold Last Month: {product.bought_last_month}")
print(f" Est. Revenue: ${product.revenue_estimate:,.2f}" if product.revenue_estimate else " Est. Revenue: N/A")
def generate_comprehensive_json(self, products: List[ProductData]) -> Dict[str, Any]:
"""Generate a comprehensive JSON with all product data"""
# Calculate statistics
total_products = len(products)
products_with_price = len([p for p in products if p.price])
products_with_rating = len([p for p in products if p.rating])
products_with_reviews = len([p for p in products if p.reviews])
products_with_quantity = len([p for p in products if p.bought_last_month])
avg_price = sum(p.price for p in products if p.price) / products_with_price if products_with_price else 0
avg_rating = sum(p.rating for p in products if p.rating) / products_with_rating if products_with_rating else 0
total_revenue = sum(p.revenue_estimate for p in products if p.revenue_estimate)
# Generate rankings
top_by_reviews = self.rank_by_reviews(products)[:10]
top_by_rating = self.rank_by_rating(products)[:10]
top_by_revenue = self.rank_by_revenue(products)[:10]
top_trending = self.rank_by_trending_score(products)[:10]
# Convert products to dictionaries
products_data = []
for product in products:
product_dict = asdict(product)
products_data.append(product_dict)
comprehensive_data = {
"analysis_metadata": {
"analysis_date": datetime.now().isoformat(),
"category": "Smart Home Best Sellers",
"api_parameters": {
"engine": "amazon",
"amazon_domain": "amazon.com",
"language": "en_US",
"sort": "exact-aware-popularity-rank",
"node": self.smart_home_node,
"pages_analyzed": 3
},
"total_products_found": total_products,
"duplicates_removed": True
},
"statistics": {
"products_with_price": products_with_price,
"products_with_rating": products_with_rating,
"products_with_reviews": products_with_reviews,
"products_with_quantity_data": products_with_quantity,
"average_price": round(avg_price, 2),
"average_rating": round(avg_rating, 2),
"total_estimated_revenue": round(total_revenue, 2)
},
"rankings": {
"top_by_reviews": [asdict(p) for p in top_by_reviews],
"top_by_rating": [asdict(p) for p in top_by_rating],
"top_by_revenue": [asdict(p) for p in top_by_revenue],
"top_trending": [asdict(p) for p in top_trending]
},
"all_products": products_data
}
return comprehensive_data
def save_comprehensive_json(self, data: Dict[str, Any], filename: str = None):
"""Save comprehensive analysis to JSON file"""
if filename is None:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"smart_home_comprehensive_analysis_{timestamp}.json"
with open(filename, 'w', encoding='utf-8') as f:
json.dump(data, f, indent=2, ensure_ascii=False)
print(f"\nComprehensive analysis saved to: {filename}")
return filename
def main():
"""Main function to run the improved Smart Home trending analysis"""
# Your API key
api_key = "your-api-key"
print("🏠 Improved Smart Home Trending Products Analyzer")
print("=" * 60)
# Initialize analyzer
analyzer = ImprovedSmartHomeTrendingAnalyzer(api_key)
try:
# Fetch products from multiple pages with duplicate handling
print("Fetching Smart Home best sellers with duplicate detection...")
products = analyzer.fetch_smart_home_best_sellers(pages=3)
if not products:
print("No products found. Please check your API key and try again.")
return
print(f"\n✅ Successfully fetched {len(products)} unique products")
# Generate comprehensive JSON
print("\n📊 Generating comprehensive JSON analysis...")
comprehensive_data = analyzer.generate_comprehensive_json(products)
# Save comprehensive JSON
json_file = analyzer.save_comprehensive_json(comprehensive_data)
# Print summary
print(f"\n📋 ANALYSIS SUMMARY")
print(f"{'='*50}")
print(f"Total Unique Products: {comprehensive_data['analysis_metadata']['total_products_found']}")
print(f"Average Price: ${comprehensive_data['statistics']['average_price']}")
print(f"Average Rating: {comprehensive_data['statistics']['average_rating']}/5.0")
print(f"Total Estimated Revenue: ${comprehensive_data['statistics']['total_estimated_revenue']:,.2f}")
print(f"Comprehensive JSON saved to: {json_file}")
# Show top 5 from each ranking
print(f"\n🔥 TOP 5 BY REVIEWS:")
top_reviews = analyzer.rank_by_reviews(products)
for i, p in enumerate(top_reviews[:5], 1):
print(f"{i}. {p.title[:50]}... - {p.reviews:,} reviews")
print(f"\n💰 TOP 5 BY REVENUE:")
top_revenue = analyzer.rank_by_revenue(products)
for i, p in enumerate(top_revenue[:5], 1):
print(f"{i}. {p.title[:50]}... - ${p.revenue_estimate:,.2f}")
except Exception as e:
print(f"❌ Error occurred: {str(e)}")
print("Please check your API key and internet connection.")
if __name__ == "__main__":
main()This example checks the Smart Home category on Amazon. Run it weekly and log the results, and you'll notice which products are climbing, which ones plateau, and which suddenly fall. That data helps you decide whether to expand inventory, shift ad budgets, or pivot into a related niche.
All the source code is available in this github repo.
The key isn't just knowing what's selling - it's knowing what's gaining momentum. And on Amazon, momentum is often the best leading indicator of what customers will care about tomorrow.
Finding New Opportunities: Where Are the Gaps?
Not every winning move comes from competing head-to-head. Sometimes the smartest play is spotting what's missing in the market. Amazon data is a great lens for this.
Example: Smart home security devices
Right now, smart home products are booming, especially budget-friendly security cameras. Search volume is high, but many top sellers have mixed reviews mentioning poor connectivity or limited cloud storage. That's a sign of unmet demand: people want affordable security, but they're frustrated with reliability.
Extracting insights at scale
By pulling product ratings and review counts, then running a quick analysis, you can highlight where demand is high but satisfaction is low. To go deeper, you can also analyze the reviews' text. For example, if many reviews mention "connectivity issues" or "cloud storage too expensive," that points to specific pain points you can address.
This kind of keyword scan surfaces recurring frustrations. Combined with search volume data, it tells you where opportunity hides.
From Data to Action: What's Your Next Move?
Amazon's marketplace isn't static. With over 350 million products and data that changes minute by minute, manual tracking is impossible. That's why businesses rely on SerpApi's Amazon Search API to automate insights. This API deliver structured, real-time access to information such as titles, prices, reviews, and inventory status - at scale and with accuracy levels above 99.9% for enterprise systems.
Putting it all together
Throughout this post, we explored three use cases powered by SerpApi's Amazon Search API:
- Competitor tracking → Monitor pricing shifts, promotions, and review surges.
- Spotting trends → Identify which categories are heating up before everyone else notices.
- Finding opportunities → Surface gaps where demand is high but satisfaction is low.
Individually, each use case is powerful. But the real magic is in the cycle: competitor tracking leads you to trends, trends reveal unmet needs, and unmet needs inspire new products that create competitors of their own. Data flows into strategy, and strategy feeds back into data.
Amazon is more than a marketplace. It's a living, breathing dataset of customer behavior. If you learn how to read it with the right tools, you move from guessing to leading. With SerpApi's Amazon Search API, you gain programmatic access to:
- Real-time product data updated within seconds
- Scalable insights across thousands of listings
- Actionable intelligence to guide pricing, product launches, and marketing
So, what's your next move? Don't just observe the market, shape it. Use these approaches to turn Amazon's constant churn into your competitive advantage.
Conclusion
I hope this guide gave you clear, practical ideas for using SerpApi's Amazon Search API in your own market research - whether that's tracking competitors, spotting trends, or uncovering new opportunities. If you have feedback, feature requests, or just want to discuss what you're building, feel free to reach out to me directly at gabriela@serpapi.com.
We're continuing to expand our Amazon integrations. Many of you have asked for deeper access to product details here:

This request is on our roadmap and your input helps shape what we prioritize next. Stay tuned for more updates.
Related Posts
If you found this guide useful, you might also enjoy:

