 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 C++
C++

If you're interested in extracting information from YouTube easily, you're in the right place! Whether you're working on a personal project, academic research, or professional analysis, understanding how to gather data from YouTube can be incredibly useful. We'll be using YouTube Search API.

Video Tutorial
If you prefer to watch a video, feel free to take a look at this one:
Tools Introduction
We'll use the new official Python library by SerpApi: serpapi-python .
That's the only tool that we need!

As a side note: You can use this library to scrape search results from other search engines, not just YouTube.
Usually, you'll write your DIY solution using something like BeautifulSoup, Selenium, Puppeteer, Requests, etc., to scrape YouTube. You can relax since we perform all these heavy tasks for you. No need to worry about all the problems you might've encountered while implementing your web scraping solution.
Step-by-step scraping YouTube data with Python
Without further ado, let's start and collect data from the YouTube site.
Step 1: Setup and preparation
- Sign up for free at SerpApi. You can get 100 free searches per month.
- Get your SerpApi Api Key from this page.
- Create a new
.envfile, and assign a new env variable with value from API_KEY above.SERPAPI_KEY=$YOUR_SERPAPI_KEY_HERE - Install python-dotenv to read the
.envfile withpip install python-dotenv - Install SerpApi's Python library with
pip install serpapi - Create new
main.pyfile for the main program.
Your folder structure will look like this:
|_ .env
|_ main.py
Step 2: Write the code for scraping YouTube search result
To use the YouTube Search API, we only need the search query as a parameter. Here is how the basic search works:
import os
import serpapi
from dotenv import load_dotenv
# Load env file and API_Key
load_dotenv()
api_key = os.getenv('SERPAPI_KEY')
# Perform a basic search
client = serpapi.Client(api_key=api_key)
search = client.search(
engine="youtube",
search_query="fit and fun" # You can change this query to anything
)
print(search)Here is the JSON response. As we can see, it matches what YouTube is actually showing.
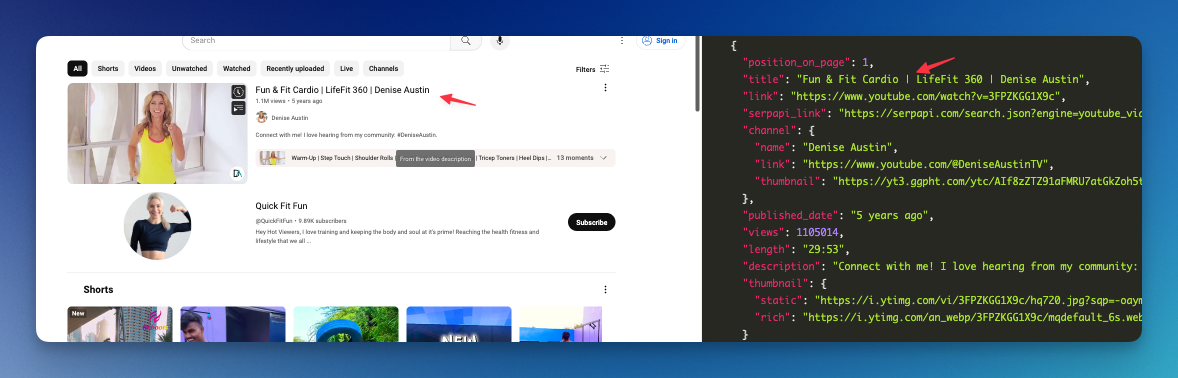
Optional: You can also add a gl or hl parameter to adjust the result with the geolocation or language that you want.
Paginate YouTube result
By default, this API only returns the first page of the results. Just like searching on the YouTube site directly, we need to do a pagination in order to grab all the results.
You can add a token for the next page on the sp parameter. We provide this next_page_token at each response on the serpapi_pagination > next_page_token response.
Here is a simple example for grabbing the next page:
client = serpapi.Client(api_key=api_key)
search = client.search(
engine="youtube",
search_query="fit and fun",
)
if "serpapi_pagination" in search:
search = client.search(
engine="youtube",
search_query="fit and fun",
sp=search["serpapi_pagination"]["next_page_token"]
)
# second page resultNow let's automate this process with a while loop:
client = serpapi.Client(api_key=api_key)
search = client.search(
engine="youtube",
search_query="fit and fun",
)
# first page results, print number of video results
print(len(search["video_results"]))
MAX_PAGES = 10
while "serpapi_pagination" in search:
search = client.search(
engine="youtube",
search_query="fit and fun",
sp=search["serpapi_pagination"]["next_page_token"]
)
print(len(search["video_results"]))
# It's recommended to limit the number of pages to avoid infinite loop
MAX_PAGES -= 1
if MAX_PAGES <= 0:
break
print("done")What data is available from this API?
You're able to get the following data:
- search video results
- Youtube ads_results
- Top news / latest
- Channel result
- Movie result
- Playlist result
- Shorts result
BONUS: Scraping video detail on Youtube
You can also get the video detail data from YouTube Video API. You'll need the video ID as a parameter. Use the video ID as v parameter value.
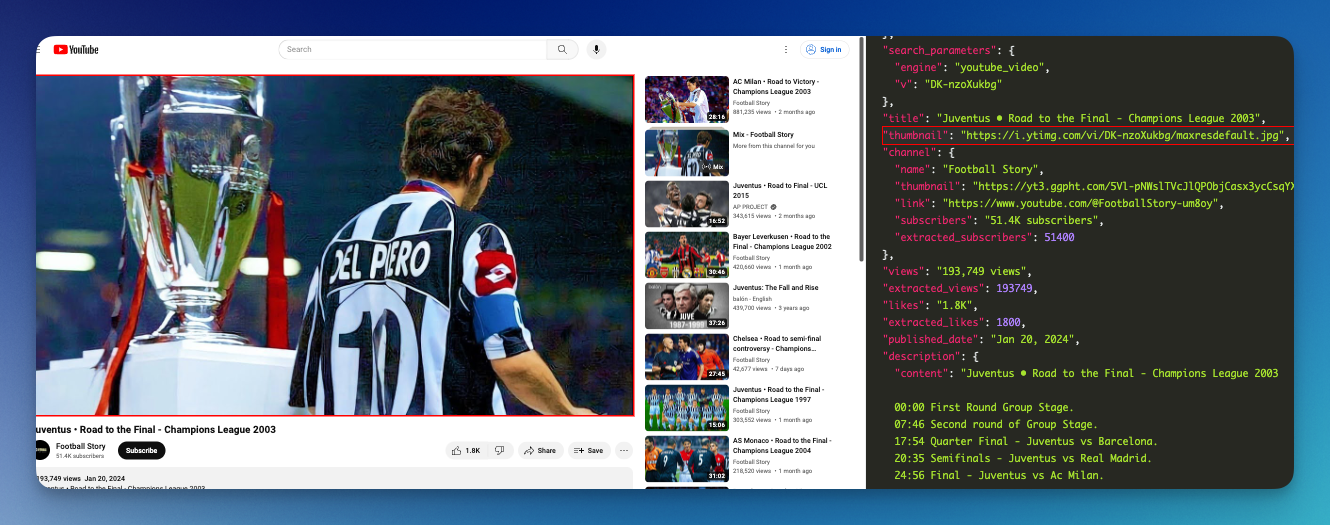
Here is the code sample:
client = serpapi.Client(api_key=api_key)
search = client.search(
engine="youtube_video",
v="DK-nzoXukbg"
)
print(search)With this, you can collect information about this video including:
- title
- thumbnail
- views
- likes
- description
- chapters
- related_videos
Here is the complete tutorial for scraping YouTube videos:

That's it! I hope you enjoyed reading this guide.