 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

What will be scraped

DuckDuckGo Related Searches API
The difference in using an API solution and DIY solution is that you'll get a faster response since there's no need to render the page.
Additionally, iterating over structured JSON is a faster process rather than writing parser from scratch and maintaining it overtime, and figuring out how to bypass blocks.
import json
from serpapi import GoogleSearch
params = {
"api_key": "...", # https://serpapi.com/manage-api-key
"engine": "duckduckgo",
"q": "fus ro dah",
"kl": "us-en"
}
search = GoogleSearch(params)
results = search.get_dict()
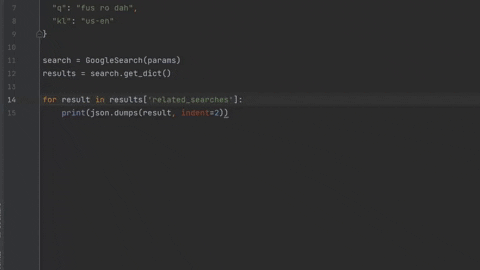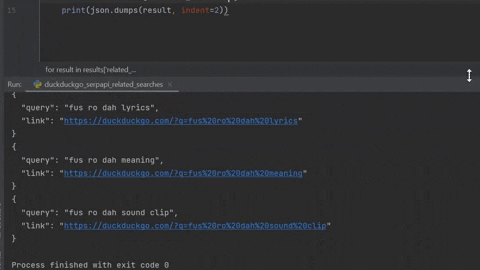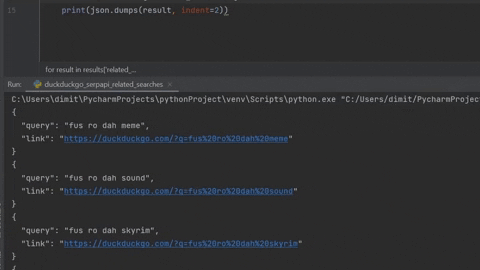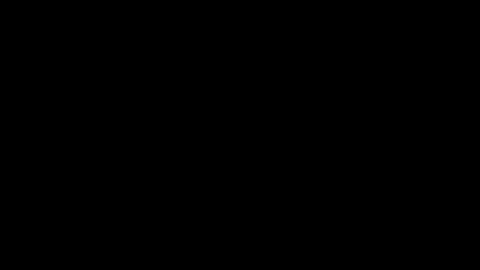
for result in results['related_searches']:
print(json.dumps(result, indent=2))
DIY Process
For some reason request-html can't locate elements at the bottom of the page when using xpath or css selectors, and scrolldown= parameter didn't help either.
This time selenium was used since it is the easiest way to get the data but at the same time, not the fastest.
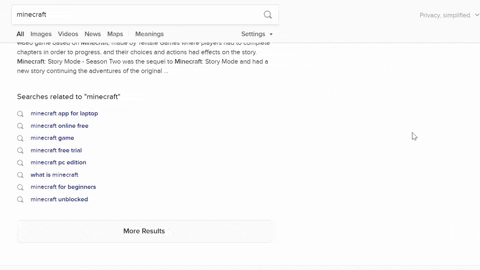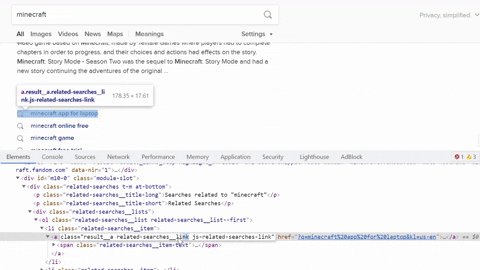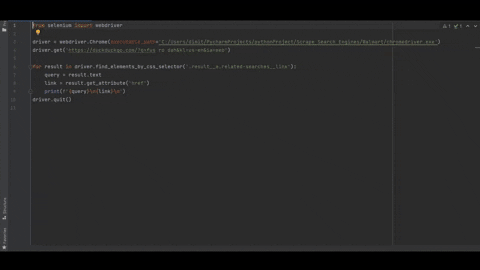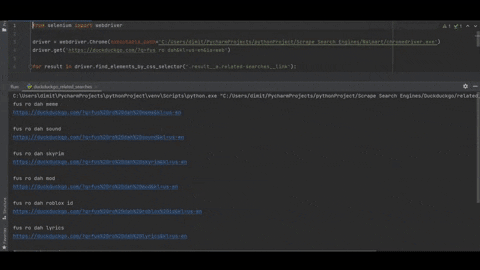
Selecting CSS selector to grab query and a link and running the script.
Note №1: running selenium in headless mode didn't return any results, or I was doing something wrong.
Note №2: the data could be extracted from the <script> tag without selenium use, but it will be a much more time-consuming process.
Full DIY Code
from selenium import webdriver
driver = webdriver.Chrome(executable_path='/path/to/chromedriver.exe')
driver.get('https://duckduckgo.com/?q=fus ro dah&kl=us-en&ia=web')
for result in driver.find_elements_by_css_selector('.result__a.related-searches__link'):
query = result.text
link = result.get_attribute('href')
print(f'{query}\n{link}\n')
driver.quit()
------------------
'''
fus ro dah meme
https://duckduckgo.com/?q=fus%20ro%20dah%20meme&kl=us-en
fus ro dah sound
https://duckduckgo.com/?q=fus%20ro%20dah%20sound&kl=us-en
fus ro dah skyrim
https://duckduckgo.com/?q=fus%20ro%20dah%20skyrim&kl=us-en
...
'''
