 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

What will be scraped

Process
Selecting container, link, and where photo is being used.

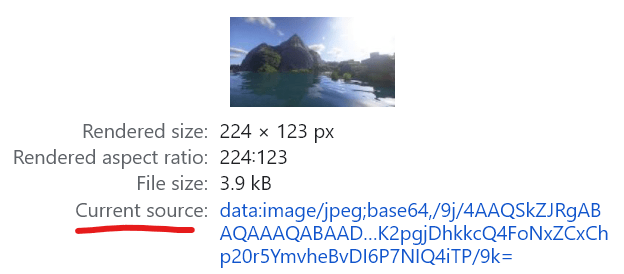
Extracting thumbnail
To extract the thumbnail, we need to look at <img> tag with id dimg_XX (XX - some number).
If you open source code (Ctrl + U) and try to find dimg_36 (or other digits depending on the HTML code) you'll see that there are 2 occurrences that will be found, and one of them will be somewhere in the <script> tags, that's what we need.
In order to extract thumbnails we need to use regex to get them from the <script> tags, because if you would parse data from a src attribute, the output you would get would be like this: data:image/gif;base64,R0lGODlhAQABAIAAAP///////yH5BAEKAAEALAAAAAABAAEAAAICTAEAOw== which is a base64 encoded picture.
More about this topic could be found on Developer Mozilla
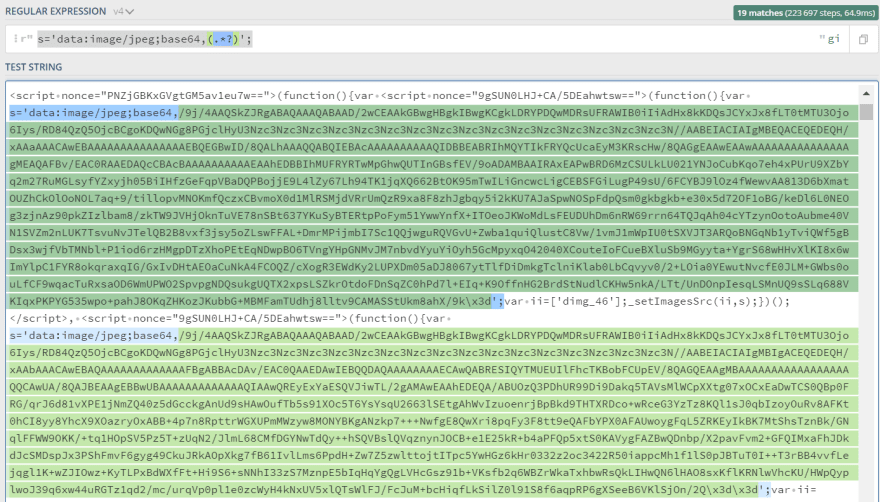
The regular expression is extremely simple:
s='data:image/jpeg;base64,(.*?)';
Regular Expression explanation:
- looking for
s='data:image/jpeg;base64, - creating a capture group
(.*?)which will grab everything, and ending with';symbols. - only the capture group will be extracted without other parts.
Screenshot to illustrate what is being captured by a regular expression which you can find here:
After that, the decoded base64 string can be saved using the PIL module. More can be found on StackOverflow answer.
Full code
import requests, lxml, re, urllib.parse, base64
from bs4 import BeautifulSoup
from PIL import Image
from io import BytesIO
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
params = {
"q": "minecraft shareds photo",
"sourceid": "chrome",
}
html = requests.get("https://www.google.com/search", params=params, headers=headers)
soup = BeautifulSoup(html.text, 'lxml')
for result in soup.select('div[jsname=dTDiAc]'):
link = f"https://www.google.com{result.a['href']}"
being_used_on = result['data-lpage']
print(f'Link: {link}\nBeing used on: {being_used_on}\n')
# finding all script (<script>) tags
script_img_tags = soup.find_all('script')
# https://regex101.com/r/L3IZXe/4
img_matches = re.findall(r"s='data:image/jpeg;base64,(.*?)';", str(script_img_tags))
for index, image in enumerate(img_matches):
try:
# https://stackoverflow.com/a/6966225/15164646
final_image = Image.open(BytesIO(base64.b64decode(str(image))))
# https://www.educative.io/edpresso/absolute-vs-relative-path
# https://stackoverflow.com/a/31434485/15164646
final_image.save(f'your/absolute_or_relative/path/inline_image_{index}.jpg', 'JPEG')
except:
pass
------------------
# part of the output:
'''
Link: https://www.google.com/search?q=minecraft+shaders+photo&tbm=isch&source=iu&ictx=1&fir=1DCWjzl0od3bFM%252Cc4Qd0ZKVFnHrsM%252C_&vet=1&usg=AI4_-kTAvknTGktfEC1K8ciH7Ot7GsAFkA&sa=X&ved=2ahUKEwiAiaDV6_HxAhVBeawKHfbtDCIQ9QF6BAgWEAE#imgrc=1DCWjzl0od3bFM
Being used on: https://pixabay.com/illustrations/minecraft-shader-minecraft-wallpaper-1970876/
Link: https://www.google.com/search?q=minecraft+shaders+photo&tbm=isch&source=iu&ictx=1&fir=bwVoAE4HTl8GXM%252Cz3y5GvasoN8hFM%252C_&vet=1&usg=AI4_-kRfUHjrz711om99elb_i3GwJuTBnw&sa=X&ved=2ahUKEwiAiaDV6_HxAhVBeawKHfbtDCIQ9QF6BAgVEAE#imgrc=bwVoAE4HTl8GXM
Being used on: https://www.pcgamesn.com/minecraft/minecraft-shaders-best-graphics-mods
...
'''
Saved images in the background:

GIF to illustrate the output:

Google Inline Images API
The biggest difference is that you don't have to figure out from where to parse certain elements in order to get a proper image size since it's already done for the end-user.
Other than that, there's no need to maintain the parser or find ways if your script request gets blocked.
Example code to integrate:
import json
from serpapi import GoogleSearch
params = {
"api_key": "YOUR_API_KEY", # your serpapi api key
"engine": "google", # search engine
"q": "minecraft shaders photo", # search query
"hl": "en" # language
}
search = GoogleSearch(params) # where data extraction happens
results = search.get_dict() # JSON -> Python dict
print(json.dumps(results['inline_images'], indent=2, ensure_ascii=False))
------------------------
'''
[
{
"link": "/search?q=minecraft+shaders+photo&hl=en&tbm=isch&source=iu&ictx=1&fir=bwVoAE4HTl8GXM%252Cz3y5GvasoN8hFM%252C_&vet=1&usg=AI4_-kRfUHjrz711om99elb_i3GwJuTBnw&sa=X&ved=2ahUKEwit6Jq38PHxAhUkSTABHfJyCn8Q9QF6BAgWEAE#imgrc=bwVoAE4HTl8GXM",
"thumbnail": "https://serpapi.com/searches/60f6e03895bf92b91f6fb3d6/images/9cce8031b6aba2675322296c8d247839d434db3be723a5fec2f933d8b4bd4d1e.jpeg"
}
]
...
'''
