 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

A guide to how you can find CertiK audited coins.
Intro
Currently, we don't have an API that supports extracting data from CertiK.
This blog post is to show you how you can do it yourself with the provided DIY solution below while we're working on releasing our proper API.
The solution can be used for personal use as it doesn't include the Legal US Shield that we offer for our paid production and above plans and has its limitations such as the need to bypass blocks, for example, CAPTCHA.
You can check our public roadmap to track the progress for this API:
What is CertiK?
According to Certik itself:
CertiK is a pioneer in blockchain security, utilizing best-in-class Formal Verification and AI technology to secure and monitor blockchains, smart contracts, and Web3 apps.
CertiK is giving coins audits and security scores after taking a look at the coin's contract if it has vulnerabilities in it or not. They are basically verifying if the contract is vulnerable to different sort of attacks.
We are scraping audited coins to avoid getting scam coins in the first place. CertiK is searching for vulnerabilities on each coin and give you a thorough analysis.
Live Demo
Imports
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import (
NoSuchElementException,
StaleElementReferenceException,
)
from selenium.webdriver.common.action_chains import ActionChains
import random
import time
import json
| Library | Purpose |
|---|---|
selenium |
to automate browser scraping |
random |
to select random user agents. |
time |
to put sleep times in order to avoid getting banned. |
json |
for extracting the data to a json file. |
We also need to import Options, By, Keys, NoSuchElementException, StaleElementReferenceException and ActionChains from selenium. I'll explain them further in the blog.
User-Agents
def pick_random_user_agent():
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 12_2_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:97.0) Gecko/20100101 Firefox/97.0",
"Mozilla/5.0 (X11; Linux i686; rv:97.0) Gecko/20100101 Firefox/97.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 12.2; rv:97.0) Gecko/20100101 Firefox/97.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 12_2_1) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.2 Safari/605.1.15",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 OPR/83.0.4254.27",
"Mozilla/5.0 (Windows NT 10.0; WOW64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 OPR/83.0.4254.27",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 OPR/83.0.4254.27",
]
user_agent = random.choice(user_agents)
return user_agent
We'll use user agents in order to hide our browser to the server. You can learn more about user agents with reading 'How to reduce the chance of being blocked while web scraping'.
We are going to randomly select a user agent from a list with random.choice() of user agents so we don't use the same every time.
Running Webdriver
def run_webdriver(user_agent):
global driver
options = Options()
options.add_argument("user-agent=" + user_agent)
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--headless")
options.add_argument("--window-size=1920,1080")
driver = webdriver.Chrome(options=options)
driver.get("https://www.certik.com")
The Options that we've imported from selenium will do it's job here. When we are giving an argument to our webdriver, we need to use options.add_argument().
You can learn more about it reading 'Chrome Options & Desired Capabilities in Selenium: Headless, AdBlocker, Incognito' at guru99.com.
You need to add "user-agent=" + user_agent as an argument to options in order to use user agents with Chrome.
After that, we need to add --no-sandbox, --disable-dev-shm-usage to not encounter the errors such as 'Running as root without --no-sandbox is not supported.' or 'Creating shared memory in /dev/shm/.org.chromium.Chromium.JwBSnH failed: No such file or directory (2)'.
To use the selenium headless, we need to add --headless argument to the options.
Lastly, we need to set window size to 1920x1080 with --window-size=1920,1080 to make our scrolling and mouse actions consistent.
We will run our driver with webdriver.Chrome(options=options). Then we are going to maximize our window.
To get a site with the webdriver, we need to use driver.get(URL).
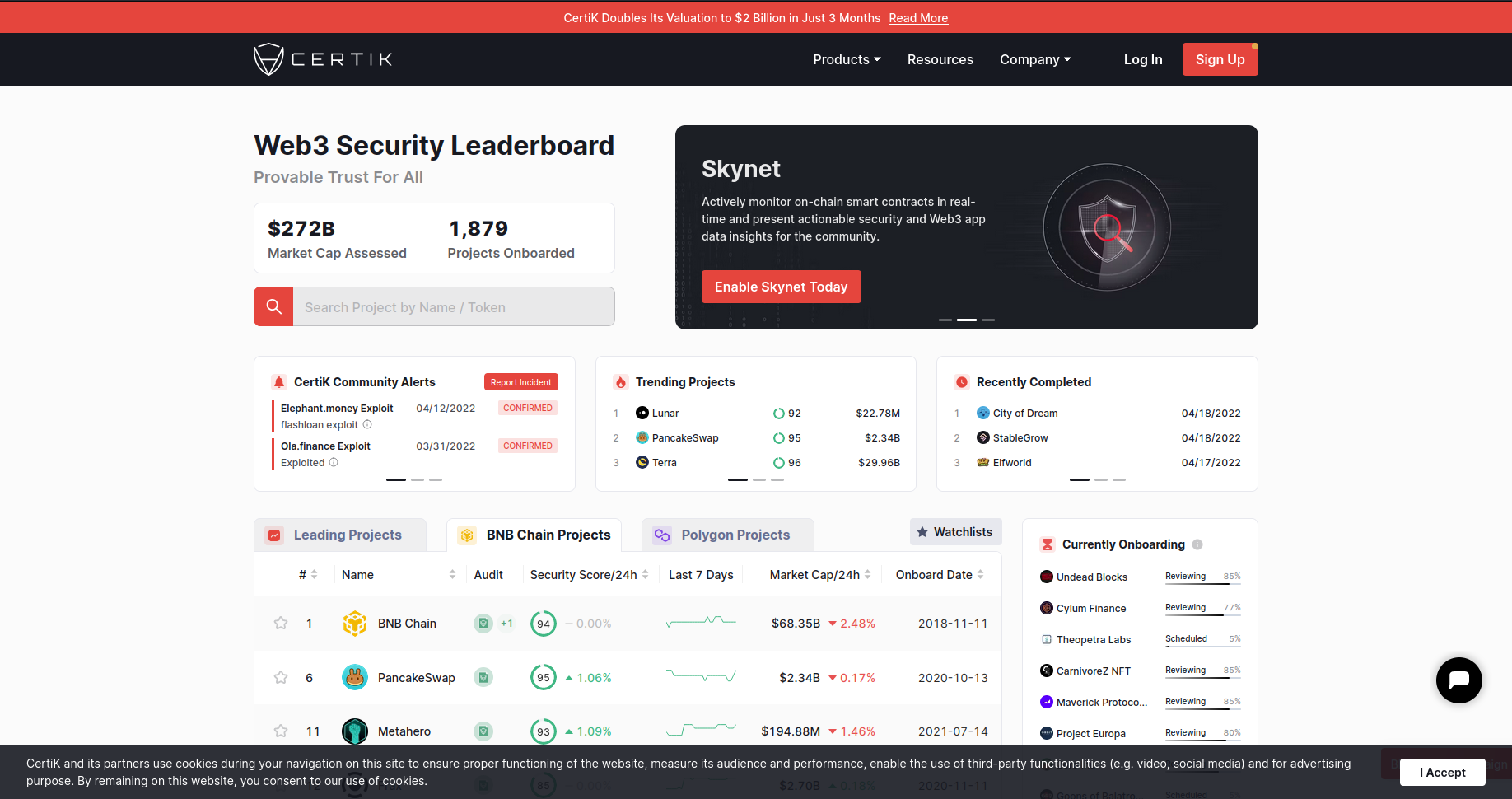
You will see this page when you run the run_webdriver().
Scraping CertiK
def certik_parser():
time.sleep(2)
market_cap = driver.find_elements(By.CLASS_NAME, "ant-table-column-has-sorters")[
-1
]
driver.find_element(By.TAG_NAME, "html").send_keys(Keys.ARROW_DOWN)
market_cap.location_once_scrolled_into_view
time.sleep(0.2)
market_cap.click()
driver.find_element(By.TAG_NAME, "html").send_keys(Keys.ARROW_DOWN)
market_cap.location_once_scrolled_into_view
time.sleep(0.2)
market_cap.click()
time.sleep(1)
driver.find_element(By.TAG_NAME, "html").send_keys(Keys.END)
item_list = driver.find_elements(By.CLASS_NAME, "ant-table-row")
item_array = {}
for item in item_list:
td_list = item.find_elements(By.TAG_NAME, "td")
coin_name = td_list[1].text
item_array[coin_name] = {}
item_array[coin_name]["Coin URL"] = (
td_list[1].find_element(By.TAG_NAME, "a").get_attribute("href")
)
item_array[coin_name]["Coin Rank"] = td_list[0].text
item_array[coin_name]["Coin Logo"] = (
td_list[1].find_element(By.TAG_NAME, "img").get_attribute("src")
)
item_array[coin_name]["Coin Score"] = td_list[3].text.replace("\n", " - ")
item_array[coin_name]["Coin Marketcap"] = td_list[5].text.replace("\n", " - ")
item_array[coin_name]["Coin Onboard Date"] = td_list[6].text
return item_array
I've put 2 second sleep time to wait for the site to fully load itself.
Our objective here is to get the last added coins on CertiK. We need to select it with using it's class name ant-table-column-has-sorters.
After that, the script is pressing arrow down button to stop the site from scrolling by itself. We need this to properly scroll to the market_cap element.
I was going to use 'Onboard Date' sorter in the first place but they seem to remove it when I wrote this blog post so we will stick to the 'Market Cap' for now.
This class name represents the elements the buttons such as 'Name, Audit, Security Score/24h' etc. To select 'Market Cap', we need to get all elements class named 'ant-table-column-has-sorters' and get the last element in the list with [-1]. Then we need to click on 'Market Cap' twice as you can see below.
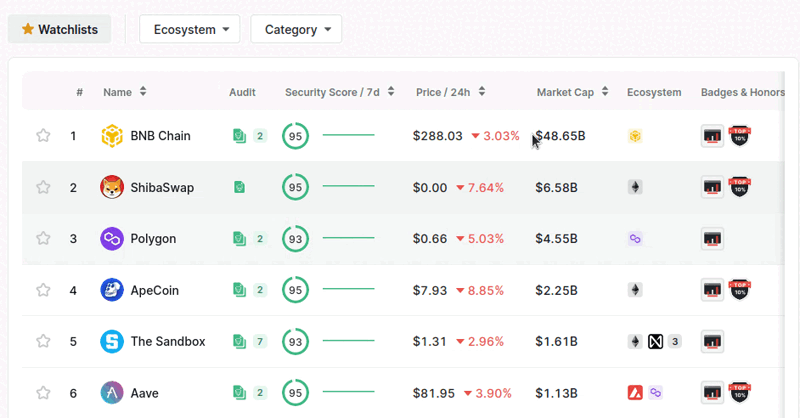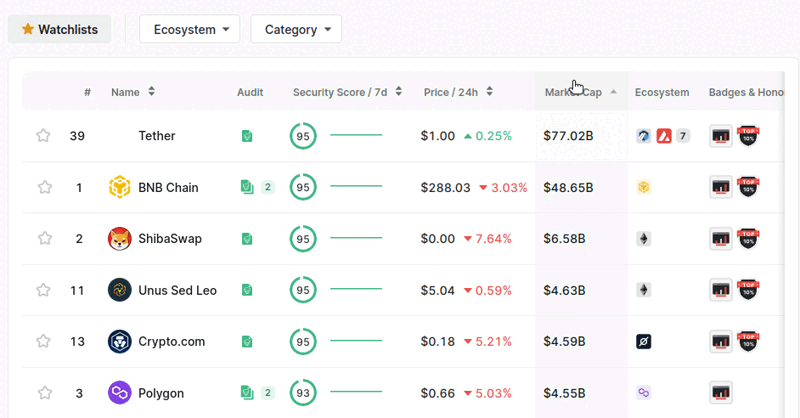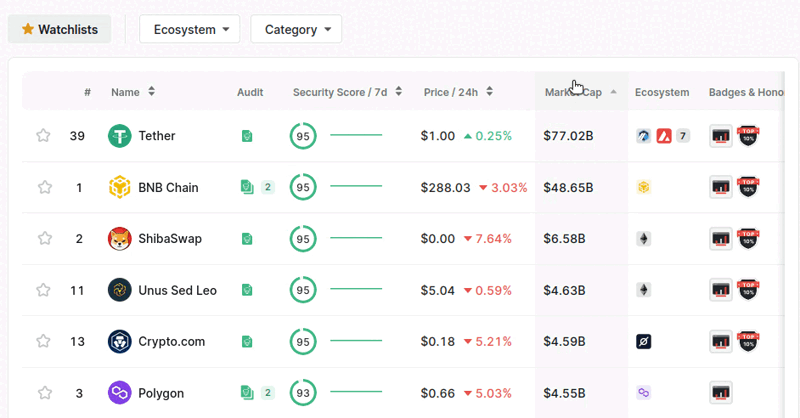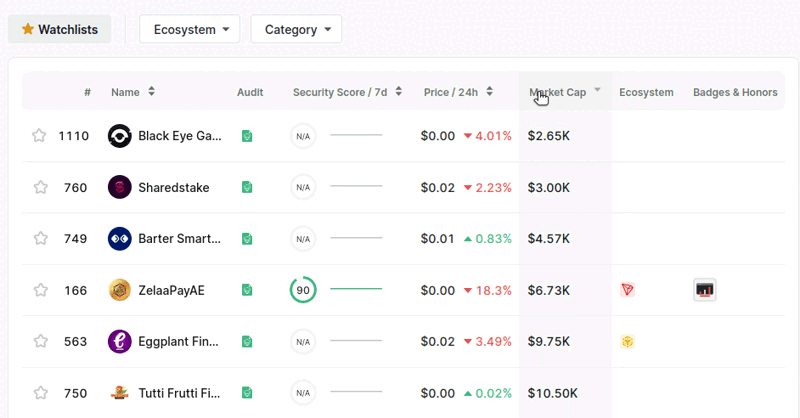
To click on it using webdriver, we need to scroll the button into view. In order to do that, we can use onboard_date.location_once_scrolled_into_view. Then we can use onboard_date.click() to click on it. We just need to click once to get last added coins.
After that, the script presses 'END' key to scroll down to bottom of the page. This allows the site to load all logos.
After that, we need to select each element class named ant-table-row with driver.find_elements(By.CLASS_NAME, "ant-table-row") to get each coin. You can see the process below.
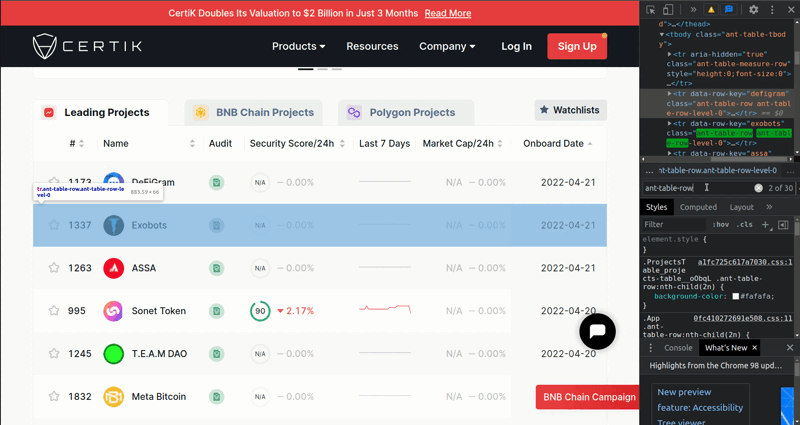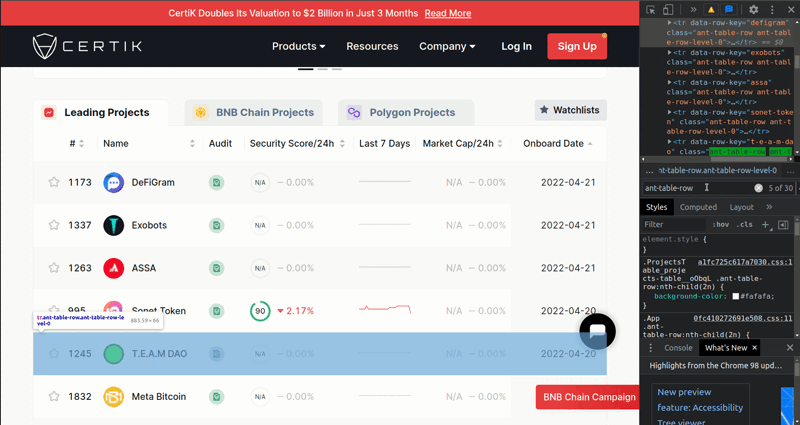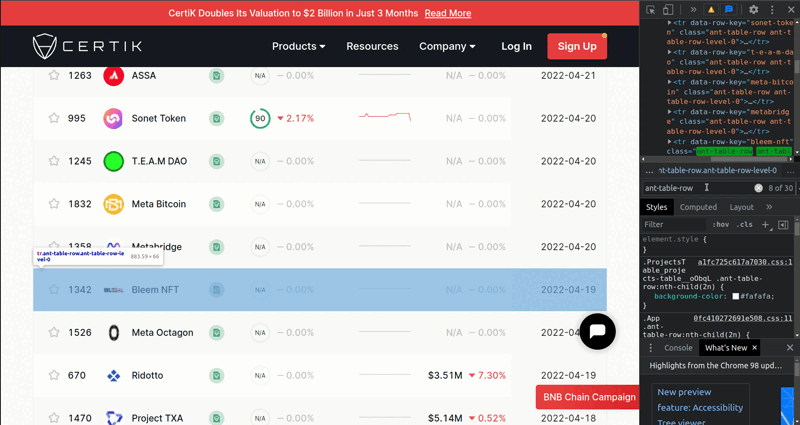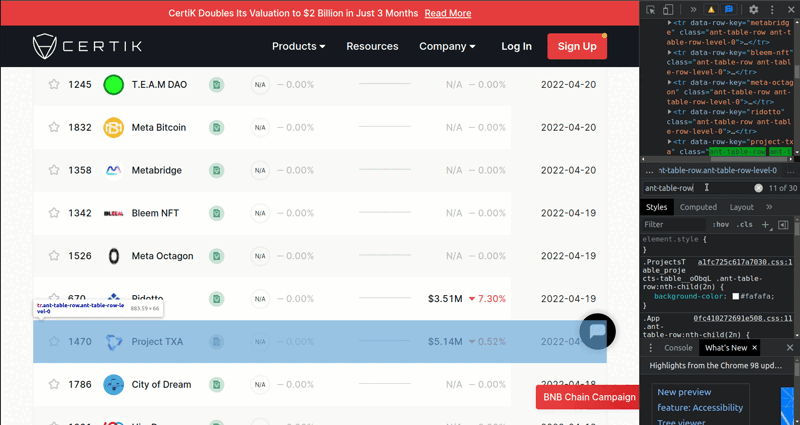
And we are going to scrape the rows with putting item_list to for loop. Each row separates horizontally with td tag name. So we need to get each element tag named 'td' to get Name, Audit, Security Score etc. one by one. To get the name, we need to use second 'td' from the td_list.
To do that, we can use td_list[1]. To get the text from an element, we need to use element.text. To get the URL from an element, we need to use element.get_attribute('href'). Lastly, to get the image from an element, we need to use element.get_attribute('src').
Getting data from coin pages
After getting the required data from the list, we are going to pass the item_array to a new definition called page_parser(). You can see it down below.
def page_parser(item_array):
for item in item_array.items():
print(item[0])
driver.get(item[1]["Coin URL"])
audit = driver.find_element(By.ID, "audit")
try:
risks_table = audit.find_element(By.CLASS_NAME, "ant-col-xl-19")
except NoSuchElementException or StaleElementReferenceException:
item_array[item[0]]["Risks"] = "Not Available"
else:
risks_div_list = risks_table.find_element(By.TAG_NAME, "div").find_elements(
By.XPATH, "div"
)
item_array[item[0]]["Risks"] = {}
item_array[item[0]]["Risks"]["Critical"] = (
[
risks_div_list[0].text.split("\n")[0],
risks_div_list[2].text.replace("\n", " / "),
risks_div_list[4].text,
]
if risks_div_list[2].text != ""
else [risks_div_list[0].text.split("\n")[0], "None"]
)
item_array[item[0]]["Risks"]["Major"] = (
[
risks_div_list[5].text.split("\n")[0],
risks_div_list[7].text.replace("\n", " / "),
risks_div_list[9].text,
]
if risks_div_list[7].text != ""
else [risks_div_list[5].text.split("\n")[0], "None"]
)
item_array[item[0]]["Risks"]["Medium"] = (
[
risks_div_list[10].text.split("\n")[0],
risks_div_list[12].text.replace("\n", " / "),
risks_div_list[14].text,
]
if risks_div_list[12].text != ""
else [risks_div_list[10].text.split("\n")[0], "None"]
)
item_array[item[0]]["Risks"]["Minor"] = (
[
risks_div_list[15].text.split("\n")[0],
risks_div_list[17].text.replace("\n", " / "),
risks_div_list[19].text,
]
if risks_div_list[17].text != ""
else [risks_div_list[15].text.split("\n")[0], "None"]
)
item_array[item[0]]["Risks"]["Informational"] = (
[
risks_div_list[20].text.split("\n")[0],
risks_div_list[22].text.replace("\n", " / "),
risks_div_list[24].text,
]
if risks_div_list[22].text != ""
else [risks_div_list[20].text.split("\n")[0], "None"]
)
We are going to loop with for item in item_array.items() to paginate.
When you print the item, you should see a dictionary like this.

If you try item[0], script will give you the name of the coin and if you try item[1], script will give you the data.
First, we are going to get our page with driver.get(item[1]['Coin URL']). Then we need to check if the coin has risks_table on the page. The 'risks_table' is this:
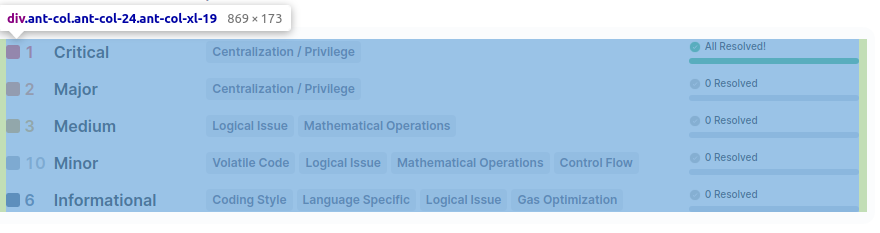
To check if risks_table is existing on the page, we need to try finding element class named ant-col-xl-19. If this element does not exist on the page, selenium should give us an error named NoSuchElementException.
The risks table is separating itself with 'div' tag name. After we get the elements, we are going to make a dictionary in item_array for each coin called 'Risks' with item_array[item[0]]['Risks'] = {}.
And we will put 5 different lists for each risk type in it. Then we'll check if the element has text in it. If not, we are just giving the list ["0", "None"].
After gathering the data from risks table, we need to get 'Platform' from here too.
if item_array[item[0]]["Risks"] == "Not Available":
platform = "Not Available"
else:
platform = risks_table.find_element(
By.XPATH, "../../../div[2]/div[1]/div[2]"
).text.split("\n")
item_array[item[0]]["Platform"] = platform
If you put .. to XPATH selector, the selector should get you the element's parent element. We need to get grand-grandparent element to navigate to the 'Platform'.
After gathering the data from risks table, we can continue gathering data from the 'Sentiment' table. Sentiment table looks like this:
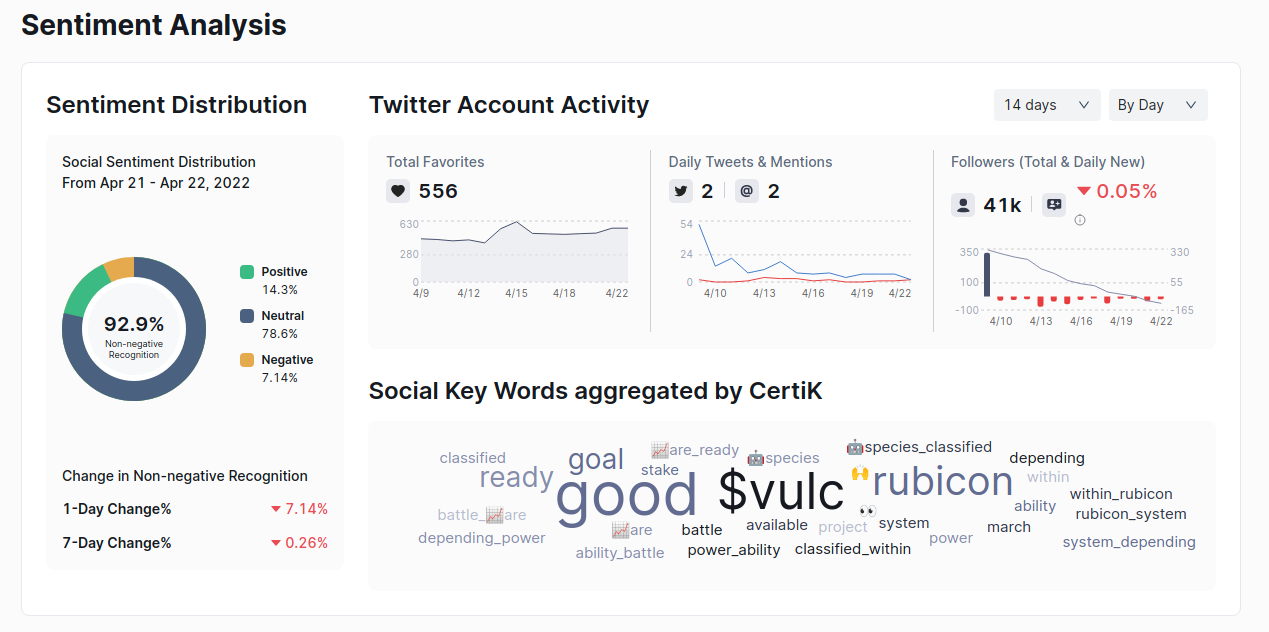
This section separates itself to 3 parts with 'div' tag. We are going to get each part using this:
try:
sentiment_section = driver.find_element(By.ID, "sentiment")
except NoSuchElementException:
item_array[item[0]]["Sentiment"] = "Not Available"
else:
item_array[item[0]]["Sentiment"] = {}
data_content = sentiment_section.find_element(By.CLASS_NAME, "data-content")
ant_row = data_content.find_element(By.XPATH, "div/div")
ant_col_list = ant_row.find_elements(By.XPATH, "div")
We need to get the first and the last item from ant_col_list. We don't need the middle item.
We are going to get 'Positive', 'Neutral', 'Negative', '1 Day Change', '7 Day Change' from Sentiment Distribution section.
sentiment = (
ant_col_list[0]
.find_element(By.XPATH, "div/div/div/div")
.find_elements(By.XPATH, "div")
)
sentiment_dist = sentiment[0].find_element(By.XPATH, "div[2]/div[2]/div")
sentiment_list = sentiment_dist.find_elements(By.XPATH, "div")
item_array[item[0]]["Sentiment"]["Positive"] = (
sentiment_list[0]
.find_element(By.XPATH, "div[2]/div[2]")
.text.replace("\n", "")
)
item_array[item[0]]["Sentiment"]["Neutral"] = (
sentiment_list[1]
.find_element(By.XPATH, "div[2]/div[2]")
.text.replace("\n", "")
)
item_array[item[0]]["Sentiment"]["Negative"] = (
sentiment_list[2]
.find_element(By.XPATH, "div[2]/div[2]")
.text.replace("\n", "")
)
We are going to use XPATH to locate each element.
sentiment_change = sentiment[1].find_elements(
By.CLASS_NAME, "ant-typography"
)
if "rgb(64, 184, 132)" in sentiment_change[0].get_attribute("style"):
sentiment_change_1_day = "+"
elif "rgb(231, 82, 82)" in sentiment_change[0].get_attribute("style"):
sentiment_change_1_day = "-"
else:
sentiment_change_1_day = "-"
sentiment_change_1_day += sentiment_change[0].text
When we are getting the changes, we need to determine if the value is negative or positive with looking the text's color because there's no indication within the element's text.
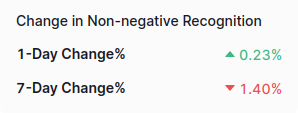
After getting the sentiment, we can continue to scrape 'Twitter Account Activity' section. You can see the process down below.
item_array[item[0]]["Twitter"] = {}
twitter_sections = (
ant_col_list[2]
.find_element(By.XPATH, "div")
.find_elements(By.XPATH, "div")
)
twitter_account_activity = twitter_sections[0].find_elements(
By.XPATH, "div"
)[1]
item_array[item[0]]["Twitter"][
"Favorites"
] = twitter_account_activity.find_element(
By.XPATH, "div[1]/div/div[1]/div[2]"
).text
item_array[item[0]]["Twitter"][
"Tweets"
] = twitter_account_activity.find_element(
By.XPATH, "div[4]/div/div[1]/div[2]"
).text
item_array[item[0]]["Twitter"][
"Mentions"
] = twitter_account_activity.find_element(
By.XPATH, "div[4]/div/div[1]/div[5]"
).text
item_array[item[0]]["Twitter"][
"Total Followers"
] = twitter_account_activity.find_element(
By.XPATH, "div[7]/div/div[1]/div[2]"
).text
if "rgb(64, 184, 132)" in twitter_account_activity.find_element(
By.XPATH, "div[7]/div/div[1]/div[2]"
).get_attribute("style"):
daily_follower = "+"
elif "rgb(231, 82, 82)" in twitter_account_activity.find_element(
By.XPATH, "div[7]/div/div[1]/div[2]"
).get_attribute("style"):
daily_follower = "-"
else:
daily_follower = ""
daily_follower += twitter_account_activity.find_element(
By.XPATH, "div[7]/div/div[1]/div[2]"
).text
item_array[item[0]]["Twitter"][
"Daily New Follower Percentage"
] = daily_follower
twitter_sections has 2 elements in it. First is the 'Account Activity' section and the second is the 'Social Key Words' section.
For 'Account Activity', we are going to scrape the elements highlighted down below.
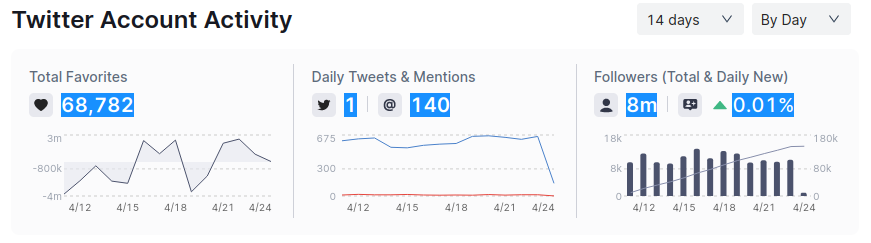
When scraping these elements, we'll use the same technique we just used before, locating element with XPATH first then getting the negative and positive symbols.
Last section we need to scrape from 'Sentiment Analysis' is the 'Key Words' section.

This process is fairly simple from the rest. We just need to locate the element and add the words to a list then add the list to the dictionary.
social_key_words = twitter_sections[1].find_elements(By.TAG_NAME, "text")
twitter_key_words = [key_word.text for key_word in social_key_words]
item_array[item[0]]["Twitter"]["Social Key Words"] = twitter_key_words
Finally, we can look how we can scrape the 'Security Score History' chart. You can see how the process looks down below.
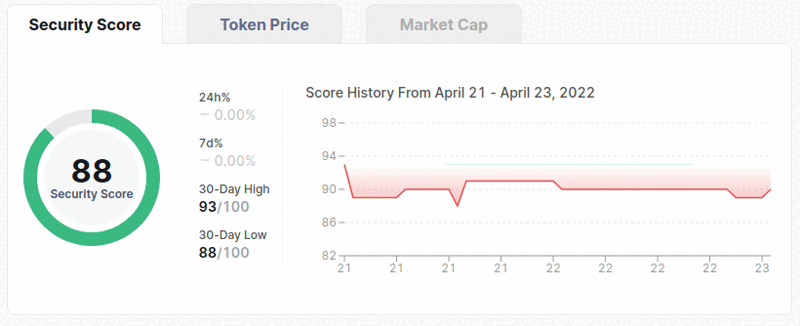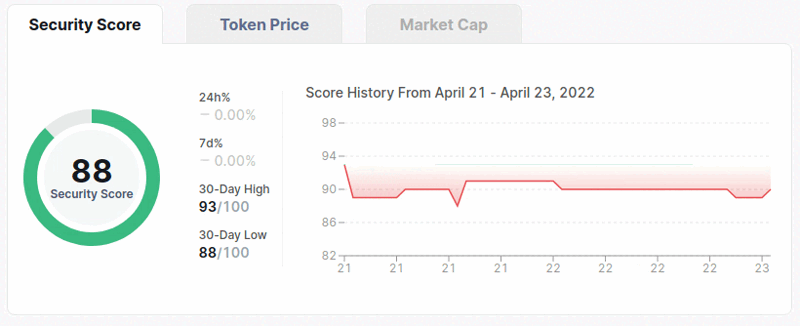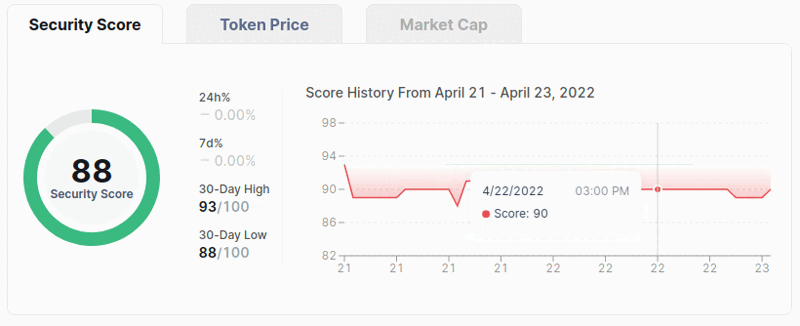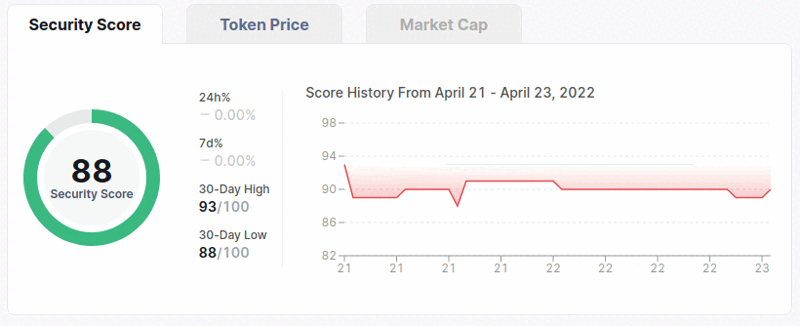
If we want to get any data for a date or time, we need to manually hover mouse over the chart to get it. As you can see, we are going to get the data with using the bottom line that has the dates on it.
if "N/A" not in item_array[item[0]]["Coin Score"]:
chart_xaxis = driver.find_element(By.CLASS_NAME, "xAxis").find_element(
By.TAG_NAME, "g"
)
chart_days = chart_xaxis.find_elements(By.CLASS_NAME, "recharts-layer")
data = []
for i, x in enumerate(chart_days):
if i == 0:
ActionChains(driver).move_to_element(x).move_by_offset(
5, -80
).perform()
else:
ActionChains(driver).move_to_element(x).move_by_offset(
0, -80
).perform()
time.sleep(0.1)
rechart_wrapper = driver.find_element(By.CLASS_NAME, "recharts-wrapper")
recharts_tooltip_wrapper = rechart_wrapper.find_element(
By.CLASS_NAME, "recharts-tooltip-wrapper"
)
date = recharts_tooltip_wrapper.find_element(
By.XPATH, "div/div[1]/div[1]"
).text
chart_time = recharts_tooltip_wrapper.find_element(
By.XPATH, "div/div[1]/div[2]"
).text
score = recharts_tooltip_wrapper.find_element(
By.XPATH, "div/div[2]/div[3]"
).text
data.append([date, chart_time, score])
item_array[item[0]]["Security Score Chart"] = data
else:
item_array[item[0]]["Security Score Chart"] = "Not available"
We are going to start this process by checking if this chart is available or not. For that, we can just look at the data that we've first scraped on 'Scraping CertiK' section. If the coin has 'N/A' on their security score, we know that the chart for this coin is not available.
If the table is available, we'll get the day elements from the bottom line.
if i == 0:
ActionChains(driver).move_to_element(x).move_by_offset(
5, -80
).perform()
else:
ActionChains(driver).move_to_element(x).move_by_offset(
0, -80
).perform()
The mouse hovering process is happening here. We need to use ActionChains that we've imported from selenium at the beginning. Firstly, we are moving the mouse to the day number.
After that we will move the mouse 20 pixels up to get on the line. perform() is doing this process one after another. The rest is easy, just locating the elements and getting text from it.
If the element is the first, we need to move the mouse slightly to right to hover the mouse on the table itself. We'll move the mouse 5 pixels right.
That's the last part for this definition.
Lastly, we just need to run our definitions and dump the dictionary to a JSON file.
user_agent = pick_random_user_agent()
run_webdriver(user_agent)
coin_array = certik_parser()
page_parser(coin_array)
with open("coin_array.json", "w+", encoding="utf-8") as f:
json.dump(coin_array, f, indent=2, ensure_ascii=False)
print('Data saved to coin_array.json\nFinishing...')
Conclusion
I would like to thank you for your time for reading this tutorial to the end.
From this blog post, you've learned how we can use the selenium module to scrape using Chrome browser.
I hope that this tutorial was helpful to you. You can see the full code down below and also on Replit.
Lastly, if you are interested in more scraping, you can check my other post called 'Scrape verified contracts on BSC Scan'.
Full Code
# -*- coding: UTF-8 -*-
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import (
NoSuchElementException,
StaleElementReferenceException,
)
from selenium.webdriver.common.action_chains import ActionChains
import random
import time
import json
def pick_random_user_agent():
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 12_2_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:97.0) Gecko/20100101 Firefox/97.0",
"Mozilla/5.0 (X11; Linux i686; rv:97.0) Gecko/20100101 Firefox/97.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 12.2; rv:97.0) Gecko/20100101 Firefox/97.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 12_2_1) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.2 Safari/605.1.15",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 OPR/83.0.4254.27",
"Mozilla/5.0 (Windows NT 10.0; WOW64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 OPR/83.0.4254.27",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 OPR/83.0.4254.27",
]
user_agent = random.choice(user_agents)
return user_agent
def run_webdriver(user_agent):
global driver
options = Options()
options.add_argument("user-agent=" + user_agent)
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--headless")
options.add_argument("--window-size=1920,1080")
driver = webdriver.Chrome(options=options)
driver.get("https://www.certik.com")
def certik_parser():
time.sleep(2)
market_cap = driver.find_elements(By.CLASS_NAME, "ant-table-column-has-sorters")[
-1
]
driver.find_element(By.TAG_NAME, "html").send_keys(Keys.ARROW_DOWN)
market_cap.location_once_scrolled_into_view
time.sleep(0.2)
market_cap.click()
driver.find_element(By.TAG_NAME, "html").send_keys(Keys.ARROW_DOWN)
market_cap.location_once_scrolled_into_view
time.sleep(0.2)
market_cap.click()
time.sleep(1)
driver.find_element(By.TAG_NAME, "html").send_keys(Keys.END)
item_list = driver.find_elements(By.CLASS_NAME, "ant-table-row")
item_array = {}
for item in item_list:
td_list = item.find_elements(By.TAG_NAME, "td")
coin_name = td_list[1].text
item_array[coin_name] = {}
item_array[coin_name]["Coin URL"] = (
td_list[1].find_element(By.TAG_NAME, "a").get_attribute("href")
)
item_array[coin_name]["Coin Rank"] = td_list[0].text
item_array[coin_name]["Coin Logo"] = (
td_list[1].find_element(By.TAG_NAME, "img").get_attribute("src")
)
item_array[coin_name]["Coin Score"] = td_list[3].text.replace("\n", " - ")
item_array[coin_name]["Coin Marketcap"] = td_list[5].text.replace("\n", " - ")
item_array[coin_name]["Coin Onboard Date"] = td_list[6].text
return item_array
def page_parser(item_array):
for item in item_array.items():
print(item[0])
driver.get(item[1]["Coin URL"])
audit = driver.find_element(By.ID, "audit")
try:
risks_table = audit.find_element(By.CLASS_NAME, "ant-col-xl-19")
except NoSuchElementException or StaleElementReferenceException:
item_array[item[0]]["Risks"] = "Not Available"
else:
risks_div_list = risks_table.find_element(By.TAG_NAME, "div").find_elements(
By.XPATH, "div"
)
item_array[item[0]]["Risks"] = {}
item_array[item[0]]["Risks"]["Critical"] = (
[
risks_div_list[0].text.split("\n")[0],
risks_div_list[2].text.replace("\n", " / "),
risks_div_list[4].text,
]
if risks_div_list[2].text != ""
else [risks_div_list[0].text.split("\n")[0], "None"]
)
item_array[item[0]]["Risks"]["Major"] = (
[
risks_div_list[5].text.split("\n")[0],
risks_div_list[7].text.replace("\n", " / "),
risks_div_list[9].text,
]
if risks_div_list[7].text != ""
else [risks_div_list[5].text.split("\n")[0], "None"]
)
item_array[item[0]]["Risks"]["Medium"] = (
[
risks_div_list[10].text.split("\n")[0],
risks_div_list[12].text.replace("\n", " / "),
risks_div_list[14].text,
]
if risks_div_list[12].text != ""
else [risks_div_list[10].text.split("\n")[0], "None"]
)
item_array[item[0]]["Risks"]["Minor"] = (
[
risks_div_list[15].text.split("\n")[0],
risks_div_list[17].text.replace("\n", " / "),
risks_div_list[19].text,
]
if risks_div_list[17].text != ""
else [risks_div_list[15].text.split("\n")[0], "None"]
)
item_array[item[0]]["Risks"]["Informational"] = (
[
risks_div_list[20].text.split("\n")[0],
risks_div_list[22].text.replace("\n", " / "),
risks_div_list[24].text,
]
if risks_div_list[22].text != ""
else [risks_div_list[20].text.split("\n")[0], "None"]
)
if item_array[item[0]]["Risks"] == "Not Available":
platform = "Not Available"
else:
platform = risks_table.find_element(
By.XPATH, "../../../div[2]/div[1]/div[2]"
).text.split("\n")
item_array[item[0]]["Platform"] = platform
try:
sentiment_section = driver.find_element(By.ID, "sentiment")
except NoSuchElementException:
item_array[item[0]]["Sentiment"] = "Not Available"
else:
item_array[item[0]]["Sentiment"] = {}
data_content = sentiment_section.find_element(By.CLASS_NAME, "data-content")
ant_row = data_content.find_element(By.XPATH, "div/div")
ant_col_list = ant_row.find_elements(By.XPATH, "div")
sentiment = (
ant_col_list[0]
.find_element(By.XPATH, "div/div/div/div")
.find_elements(By.XPATH, "div")
)
sentiment_dist = sentiment[0].find_element(By.XPATH, "div[2]/div[2]/div")
sentiment_list = sentiment_dist.find_elements(By.XPATH, "div")
item_array[item[0]]["Sentiment"]["Positive"] = (
sentiment_list[0]
.find_element(By.XPATH, "div[2]/div[2]")
.text.replace("\n", "")
)
item_array[item[0]]["Sentiment"]["Neutral"] = (
sentiment_list[1]
.find_element(By.XPATH, "div[2]/div[2]")
.text.replace("\n", "")
)
item_array[item[0]]["Sentiment"]["Negative"] = (
sentiment_list[2]
.find_element(By.XPATH, "div[2]/div[2]")
.text.replace("\n", "")
)
sentiment_change = sentiment[1].find_elements(
By.CLASS_NAME, "ant-typography"
)
if "rgb(64, 184, 132)" in sentiment_change[0].get_attribute("style"):
sentiment_change_1_day = "+"
elif "rgb(231, 82, 82)" in sentiment_change[0].get_attribute("style"):
sentiment_change_1_day = "-"
else:
sentiment_change_1_day = "-"
sentiment_change_1_day += sentiment_change[0].text
if "rgb(64, 184, 132)" in sentiment_change[1].get_attribute("style"):
sentiment_change_7_day = "+"
elif "rgb(231, 82, 82)" in sentiment_change[1].get_attribute("style"):
sentiment_change_7_day = "-"
else:
sentiment_change_7_day = "-"
sentiment_change_7_day += sentiment_change[1].text
item_array[item[0]]["Sentiment"]["1 Day Change"] = sentiment_change_1_day
item_array[item[0]]["Sentiment"]["7 Day Change"] = sentiment_change_7_day
item_array[item[0]]["Twitter"] = {}
twitter_sections = (
ant_col_list[2]
.find_element(By.XPATH, "div")
.find_elements(By.XPATH, "div")
)
twitter_account_activity = twitter_sections[0].find_elements(
By.XPATH, "div"
)[1]
item_array[item[0]]["Twitter"][
"Favorites"
] = twitter_account_activity.find_element(
By.XPATH, "div[1]/div/div[1]/div[2]"
).text
item_array[item[0]]["Twitter"][
"Tweets"
] = twitter_account_activity.find_element(
By.XPATH, "div[4]/div/div[1]/div[2]"
).text
item_array[item[0]]["Twitter"][
"Mentions"
] = twitter_account_activity.find_element(
By.XPATH, "div[4]/div/div[1]/div[5]"
).text
item_array[item[0]]["Twitter"][
"Total Followers"
] = twitter_account_activity.find_element(
By.XPATH, "div[7]/div/div[1]/div[2]"
).text
if "rgb(64, 184, 132)" in twitter_account_activity.find_element(
By.XPATH, "div[7]/div/div[1]/div[2]"
).get_attribute("style"):
daily_follower = "+"
elif "rgb(231, 82, 82)" in twitter_account_activity.find_element(
By.XPATH, "div[7]/div/div[1]/div[2]"
).get_attribute("style"):
daily_follower = "-"
else:
daily_follower = ""
daily_follower += twitter_account_activity.find_element(
By.XPATH, "div[7]/div/div[1]/div[2]"
).text
item_array[item[0]]["Twitter"][
"Daily New Follower Percentage"
] = daily_follower
social_key_words = twitter_sections[1].find_elements(By.TAG_NAME, "text")
twitter_key_words = [key_word.text for key_word in social_key_words]
item_array[item[0]]["Twitter"]["Social Key Words"] = twitter_key_words
if "N/A" not in item_array[item[0]]["Coin Score"]:
chart_xaxis = driver.find_element(By.CLASS_NAME, "xAxis").find_element(
By.TAG_NAME, "g"
)
chart_days = chart_xaxis.find_elements(By.CLASS_NAME, "recharts-layer")
data = []
for i, x in enumerate(chart_days):
if i == 0:
ActionChains(driver).move_to_element(x).move_by_offset(
5, -80
).perform()
else:
ActionChains(driver).move_to_element(x).move_by_offset(
0, -80
).perform()
time.sleep(0.1)
rechart_wrapper = driver.find_element(By.CLASS_NAME, "recharts-wrapper")
recharts_tooltip_wrapper = rechart_wrapper.find_element(
By.CLASS_NAME, "recharts-tooltip-wrapper"
)
date = recharts_tooltip_wrapper.find_element(
By.XPATH, "div/div[1]/div[1]"
).text
chart_time = recharts_tooltip_wrapper.find_element(
By.XPATH, "div/div[1]/div[2]"
).text
score = recharts_tooltip_wrapper.find_element(
By.XPATH, "div/div[2]/div[3]"
).text
data.append([date, chart_time, score])
item_array[item[0]]["Security Score Chart"] = data
else:
item_array[item[0]]["Security Score Chart"] = "Not available"
user_agent = pick_random_user_agent()
run_webdriver(user_agent)
coin_array = certik_parser()
page_parser(coin_array)
with open("coin_array.json", "w+", encoding="utf-8") as f:
json.dump(coin_array, f, indent=2, ensure_ascii=False)