 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++


Intro
We currently don't have an API for scraping verified contracts on BSC Scan.
This blog post is written to show the DIY solution that can be used for personal use while waiting for our proper solution.
The reason DIY solution can be used for personal use only is that it doesn't include the Legal US Shield that we offer for our paid production and above plans.
You can check our public roadmap to track the progress for this API:
Disclaimer
This blog is only for educational purposes. You can look at BscScan and EtherScan, more specifically platforms that serve tokens with verified contracts.
In this blog, we will scrape BscScan to get tokens on BSC(Binance Smart Chain). Some of these coins are very likely to be scams. Please make investments if you know how to identify scam coins.
Also, we don't have an API that supports extracting data from BSC Scan. This blog post is to show you how you can do it yourself.
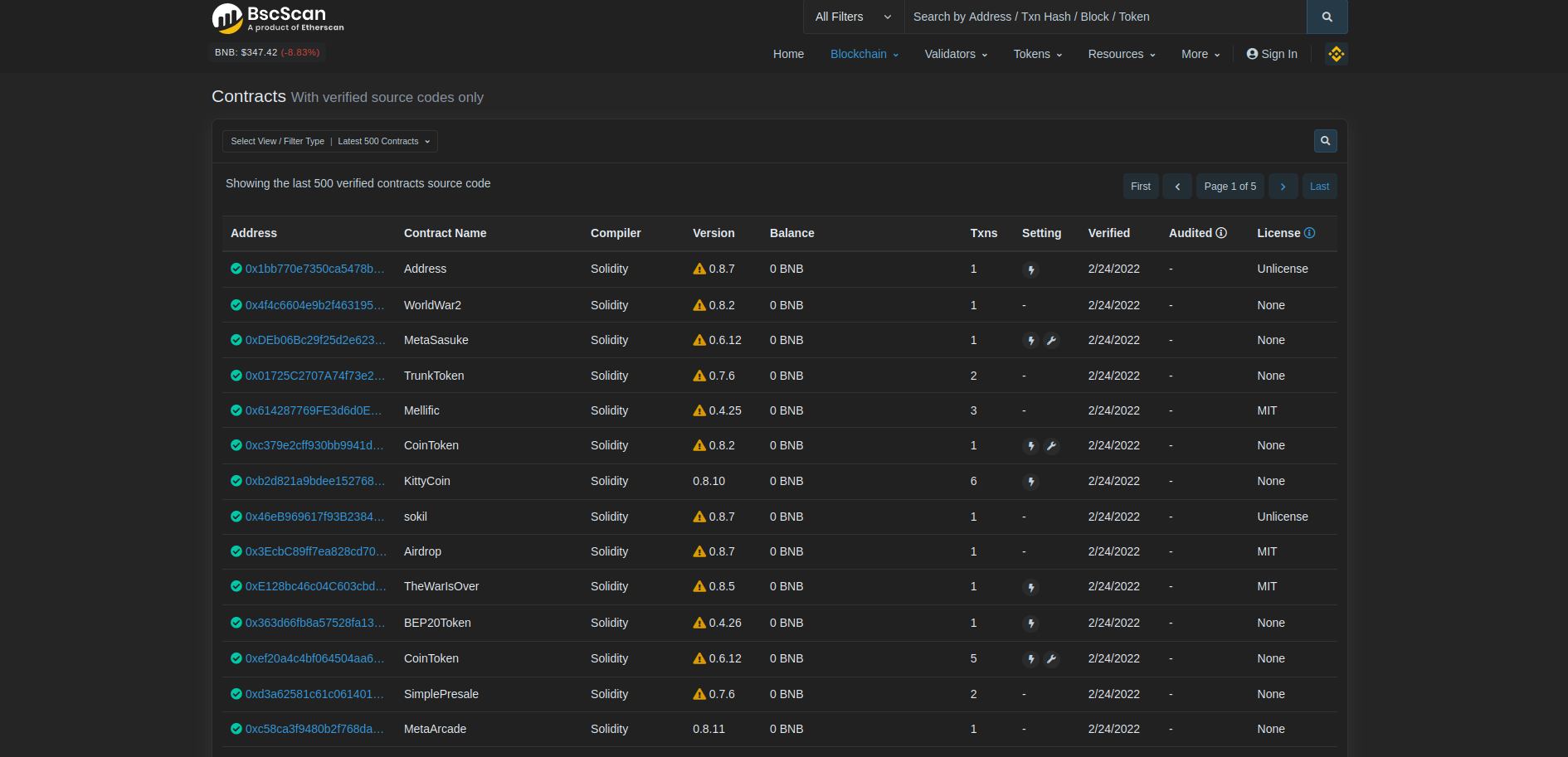
There's a page called 'Verified Contracts' on BscScan. We can get the latest verified contracts from verified source codes only. It's giving the latest 25 records of verified contracts here. But we are going to maximize this record count. You can change this by adding ps=100 parameter on URL like this:
https://bscscan.com/contractsVerified?ps=100
Let's import our modules first.
import requests # Get the HTML
import random # To select random user agents
import json # Save extracted data from the JSON
from bs4 import BeautifulSoup # Parse HTML
from time import sleep # Delay between requests| Library | Purpose |
|---|---|
requests |
o parse this html |
pandas |
to convert parsed HTML to DataFrame |
Beautifulsoup |
to show alternative parsing method. |
time |
to put sleep times in order to avoid getting banned. |
json |
for extracting the data to a json file. |
random |
to select random user agents. |
We need to use user-agents when we are scraping. Because the websites we scrape can identify our automated actions, if we are a bot or not pretty easily without them.
Also, we don't want to use old user-agents that are using Chrome version 70 in 2022.
You can read 'How to reduce the chance of being blocked while web scraping' to learn more about user-agents.
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 12_2_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:97.0) Gecko/20100101 Firefox/97.0",
"Mozilla/5.0 (X11; Linux i686; rv:97.0) Gecko/20100101 Firefox/97.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 12.2; rv:97.0) Gecko/20100101 Firefox/97.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 12_2_1) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.2 Safari/605.1.15",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 OPR/83.0.4254.27",
"Mozilla/5.0 (Windows NT 10.0; WOW64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 OPR/83.0.4254.27",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 OPR/83.0.4254.27"
]I've gathered these user-agents from list of the latest user agents. They are listing the latest possible versions of user agents there.
Please check it and change it if the user agents that I've used are old so you can keep the project working as long as possible. We can select randomly from this list to use as many user agents as possible. Let's make a definition for this.
def pick_random_user_agent():
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 12_2_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:97.0) Gecko/20100101 Firefox/97.0",
"Mozilla/5.0 (X11; Linux i686; rv:97.0) Gecko/20100101 Firefox/97.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 12.2; rv:97.0) Gecko/20100101 Firefox/97.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 12_2_1) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.2 Safari/605.1.15",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 OPR/83.0.4254.27",
"Mozilla/5.0 (Windows NT 10.0; WOW64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 OPR/83.0.4254.27",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 OPR/83.0.4254.27"
]
header = {"user-agent": random.choice(user_agents)}
return headerThe request library requires the user-agent parameter in order to add some user agents when it is fetching the page you desire. We'll use the random module to randomly select a user-agent from the 'user_agents' with random.choice(user_agents) then return the header so we can use it with requests.
Then we need to make a definition to get Bscscan Verified Contracts page.
def get_bscscan():
header = pick_random_user_agent()
while True:
response = requests.get(
"https://bscscan.com/contractsVerified?ps=100",
headers=header,
timeout=5
)
if response.status_code == 200:
break
else:
header = pick_random_user_agent()
return response.contentFirst we will define header with header = pick_random_user_agent() Then we need to get the html page using requests.get. To use headers within it, we just need to use headers=header parameter.
The timeout represents when the requests will abort and give error if it has encountered with an error. We always need to get 200 as a status code since it means the GET requests is OK.
You can see all HTTP status codes from Wikipedia list of HTTP status codes. If we don't get 200 as a status code, we should change the user agent if there is a problem. Then we need to return response.content in order to use it with pandas and BeautifulSoup.
Let's start scraping bscscan with pandas. Because verified contracts are tables, we'll be using pandas.
def parse_body(body):
parsed_body = pandas.read_html(body)[0]
results_array = []
for i, row in parsed_body.iterrows():
contract = {
"position": i,
"name": row["Contract Name"],
"compiler": row["Compiler"],
"compiler_version": row["Version"],
"license": row["License"],
"balance": row["Balance"],
"transactions": row["Txns"],
"address": row["Address"],
"contract_url": "https://bscscan.com/address/" + row["Address"],
"token_url": "https://bscscan.com/token/" + row["Address"] + "#balances",
"holders_url": "https://bscscan.com/token/tokenholderchart/"
+ row["Address"]
+ "?range=500",
}
results_array.append(contract)
return results_arrayIf you print parsed_body, you will get something like this:

We are going to make a dictionary for every row in DataFrame and append these dictionaries to results_array list. To get what you wanted from dataframe one by one you can just use row['Column Name']. For urls, let's just add the token address to the URL to come up with necessary links.
For holders_url, we are going to add range=500 to get the first 500 holders for a token. We will get to this part again soon. Finally we are going to return results_array to use it for paginating every token's page to get more deep information.
So first, we need to make a definition for getting the token page.
def get_token_page(link):
header = pick_random_user_agent()
while True:
response = requests.get(link, headers=header, timeout=5)
if response.status_code == 200:
break
else:
header = pick_random_user_agent()
return response.contentIt's the same process with get_bscscan() definition. We are just passing the link to definition.
Parsing Token Pages
def parse_token_page(body):
token_page = get_token_page(body["token_url"])
sleep(0.5)
parsed_body = BeautifulSoup(token_page, "html.parser")
page_dictionary = {}
name_element = parsed_body.select_one(".media-body .small")
if name_element is None:
page_dictionary = "Not Existing"
elif name_element is not None:
page_dictionary["name"] = name_element.text[:-1]
overview_element = parsed_body.select_one(
".card:has(#ContentPlaceHolder1_tr_valuepertoken)"
)
if overview_element is not None:
overview_dictionary = {}
token_standart = overview_element.select_one(".ml-1 b")
if token_standart is not None:
overview_dictionary["token_standart"] = token_standart.text
token_price = overview_element.select_one(".d-block span:nth-child(1)")
if token_price is not None:
overview_dictionary["token_price"] = float(token_price.text.replace('$', ''))
token_marketcap = overview_element.select_one("#pricebutton")
if token_marketcap is not None:
overview_dictionary["token_marketcap"] = float(
token_marketcap.text[2:-1].replace('$', '')
)
token_supply = overview_element.select_one(".hash-tag")
if token_supply is not None:
overview_dictionary["token_supply"] = float(
token_supply.text.replace(",", "")
)
token_holders = overview_element.select_one(
"#ContentPlaceHolder1_tr_tokenHolders .mr-3"
)
if token_holders is not None:
overview_dictionary["token_holders"] = int(token_holders.text[1:-11].replace(',', ''))
token_transfers = overview_element.select_one("#totaltxns")
if token_transfers is not None:
overview_dictionary["token_transfers"] = int(token_transfers.text.replace(',', '')) if token_transfers.text != '-' else 0
token_socials = overview_element.select_one(
"#ContentPlaceHolder1_trDecimals+ div .col-md-8"
)
if token_socials is not None:
overview_dictionary["token_socials"] = token_socials.text
if overview_dictionary["token_holders"] != 0:
parsed_body = BeautifulSoup(
get_token_page(body["holders_url"]), "html.parser"
)
holders_dictionary = {}
holder_addresses = parsed_body.select(
"#ContentPlaceHolder1_resultrows a"
)
holder_quantities = parsed_body.select("td:nth-child(3)")
holder_percentages = parsed_body.select("td:nth-child(4)")
for rank in range(len(holder_addresses)):
holders_dictionary[rank] = {}
holders_dictionary[rank]["address"] = holder_addresses[rank].text
holders_dictionary[rank]["quantity"] = float(
holder_quantities[rank].text.replace(",", "")
)
holders_dictionary[rank]["percentage"] = float(
holder_percentages[rank].text[:-1].replace(",", "")
)
page_dictionary["holders_dictionary"] = holders_dictionary
page_dictionary["overview_dictionary"] = overview_dictionary
return page_dictionaryFirst, we are going to pass every item in results_array to this definition one by one. To get the html from token page, we are going to use get_token_page definition. We are going to put a time sleep for half a second to avoid getting banned from the site.
This time, rather than pandas, we are going to use BeautifulSoup to parse the token page. Once we get the token page, we are going to pass it to BeautifulSoup to parse it. We need to give it the parsing method such as "html.parser".
We are going to make a dictionary called page_dictionary to append all token data from pages to this. Let's begin to scrape some data from parsed body. Let's look at the name_element first. parsed_body.select_one() finds only the first element that matches the selector you've given in it.
We are going to get the element's selector by using a Chrome extension called Selector Gadget. You can see how we can select name with Selector Gadget. Just click the element you want to get. Then click on yellow elements if you don't want to get them with the element you've chosen. Lastly, you can copy the selector for the exact element(s) you want to use.
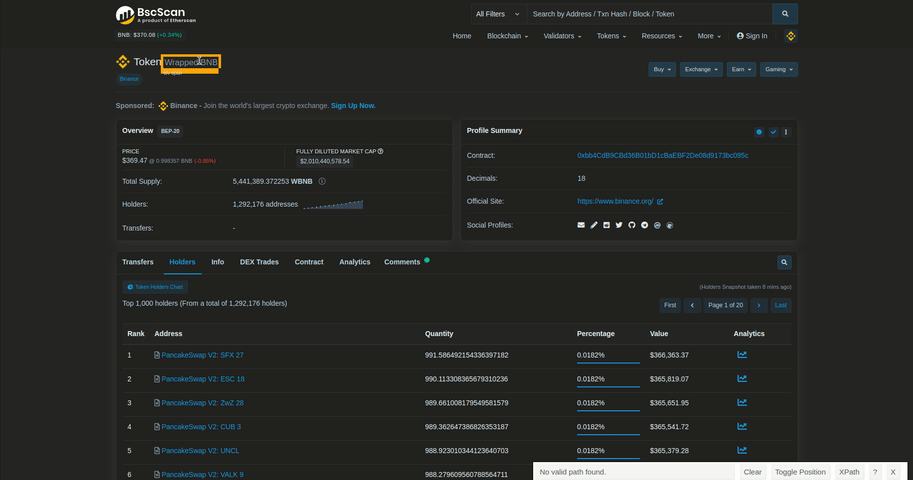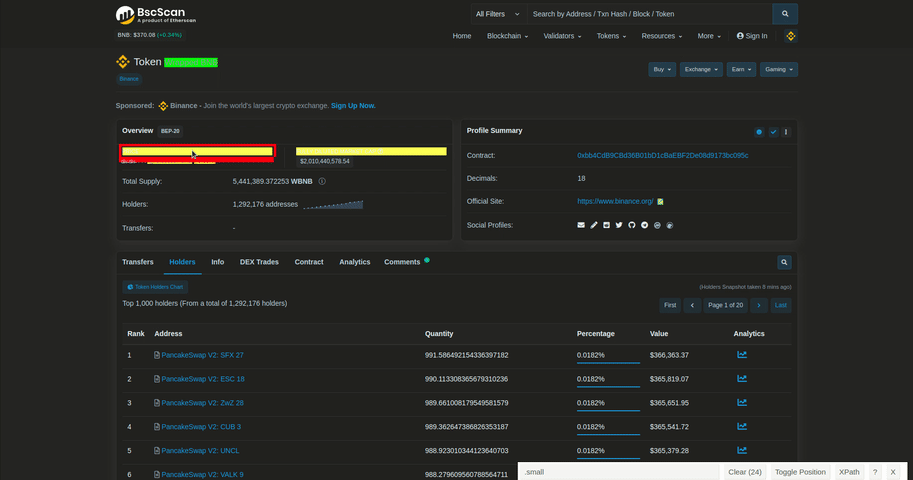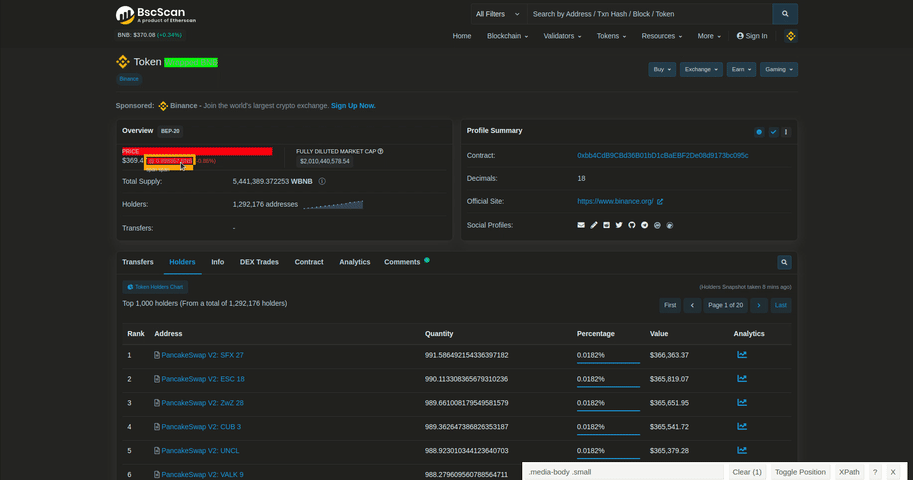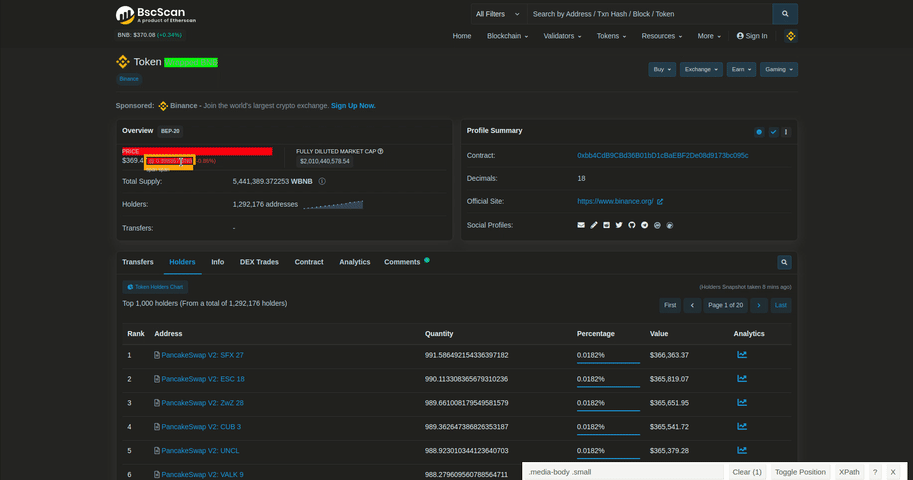
We can get some token's data such as market cap, price from overview card. To get it, we can use .card:has(#ContentPlaceHolder1_tr_valuepertoken). Let's gather some data from overview_element if it is already existing.
We are going to make a dictionary called overview_dictionary and append the elements that we can scrape in here. We can just do the exact same process when parsing other parts of interest. You can see the necessary scraping process above.
Once we do that, we can gather holders for the token. If you try to get the holders data with Selector Gadget, you are going to get a selector called tokeholdersiframe. If you go and inspect this element, you will see that the holders table is actually coming from another HTML.
We can get the URL for this from results_array. Once we parse the holders with BeautifulSoup, we can get all of the addresses, quantities and percentages by using parsed_body.select(). Once we gathered all of them, we can make a for loop to append them to the holders_dictionary.
Then we are going to append holders_dictionary and overview_dictionary to page_dictionary. Lastly we are going to return page_dictionary to save it to a JSON file.
I'm putting replace to replace ',' on marketcap, holders, transfers etc. because python is not seeing numbers with commas as thousand, million or billion.
body = get_bscscan()
results_array = parse_body(body)
for token_dictionary in results_array:
page_dictionary = parse_token_page(token_dictionary)
token_dictionary["page_dictionary"] = page_dictionary
print(token_dictionary)
with open("results.json", "w+") as f:
json.dump(results_array, f, indent=2)This is the process with the definitions that we have used.
Conclusion
We can get some newly created coins by using this code. But I'm not recommending you to make big investments in these because it is risky. Don't make investments in these if you don't know how to identify scam coins. There are a lot of scamming going on with these coins.
You can see the full code below. Thank you for taking your time.
Full Code
import requests, pandas, random, json
from bs4 import BeautifulSoup
from time import sleep
def pick_random_user_agent():
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 12_2_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:97.0) Gecko/20100101 Firefox/97.0",
"Mozilla/5.0 (X11; Linux i686; rv:97.0) Gecko/20100101 Firefox/97.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 12.2; rv:97.0) Gecko/20100101 Firefox/97.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 12_2_1) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.2 Safari/605.1.15",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 OPR/83.0.4254.27",
"Mozilla/5.0 (Windows NT 10.0; WOW64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 OPR/83.0.4254.27",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 OPR/83.0.4254.27"
]
header = {"user-agent": random.choice(user_agents)}
return header
def get_bscscan():
header = pick_random_user_agent()
while True:
response = requests.get(
"https://bscscan.com/contractsVerified?ps=100", headers=header, timeout=5
)
if response.status_code == 200:
break
else:
header = pick_random_user_agent()
return response.content
def parse_body(body):
parsed_body = pandas.read_html(body)[0]
results_array = []
for i, row in parsed_body.iterrows():
contract = {
"position": i,
"name": row["Contract Name"],
"compiler": row["Compiler"],
"compiler_version": row["Version"],
"license": row["License"],
"balance": row["Balance"],
"transactions": row["Txns"],
"address": row["Address"],
"contract_url": "https://bscscan.com/address/" + row['Address'],
"token_url":
"https://bscscan.com/token/" + row['Address'] + "#balances",
"holders_url":
"https://bscscan.com/token/tokenholderchart/"
+ row['Address']
+ "?range=500",
}
results_array.append(contract)
return results_array
def get_token_page(link):
header = pick_random_user_agent()
while True:
response = requests.get(link, headers=header, timeout=5)
if response.status_code == 200:
break
else:
header = pick_random_user_agent()
return response.content
def parse_token_page(body):
token_page = get_token_page(body["token_url"])
sleep(0.5)
parsed_body = BeautifulSoup(token_page, "html.parser")
page_dictionary = {}
name_element = parsed_body.select_one(".media-body .small")
if name_element is None:
page_dictionary = "Not Existing"
elif name_element is not None:
page_dictionary["name"] = name_element.text[:-1]
overview_element = parsed_body.select_one(
".card:has(#ContentPlaceHolder1_tr_valuepertoken)"
)
if overview_element is not None:
overview_dictionary = {}
token_standart = overview_element.select_one(".ml-1 b")
if token_standart is not None:
overview_dictionary["token_standart"] = token_standart.text
token_price = overview_element.select_one(".d-block span:nth-child(1)")
if token_price is not None:
overview_dictionary["token_price"] = float(token_price.text.replace('$', ''))
token_marketcap = overview_element.select_one("#pricebutton")
if token_marketcap is not None:
overview_dictionary["token_marketcap"] = float(
token_marketcap.text[2:-1].replace('$', '')
)
token_supply = overview_element.select_one(".hash-tag")
if token_supply is not None:
overview_dictionary["token_supply"] = float(
token_supply.text.replace(",", "")
)
token_holders = overview_element.select_one(
"#ContentPlaceHolder1_tr_tokenHolders .mr-3"
)
if token_holders is not None:
overview_dictionary["token_holders"] = int(token_holders.text[1:-11].replace(',', ''))
token_transfers = overview_element.select_one("#totaltxns")
if token_transfers is not None:
overview_dictionary["token_transfers"] = int(token_transfers.text.replace(',', '')) if token_transfers.text != '-' else 0
token_socials = overview_element.select_one(
"#ContentPlaceHolder1_trDecimals+ div .col-md-8"
)
if token_socials is not None:
overview_dictionary["token_socials"] = token_socials.text
if overview_dictionary["token_holders"] != 0:
parsed_body = BeautifulSoup(
get_token_page(body["holders_url"]), "html.parser"
)
holders_dictionary = {}
holder_addresses = parsed_body.select(
"#ContentPlaceHolder1_resultrows a"
)
holder_quantities = parsed_body.select("td:nth-child(3)")
holder_percentages = parsed_body.select("td:nth-child(4)")
for rank in range(len(holder_addresses)):
holders_dictionary[rank] = {}
holders_dictionary[rank]["address"] = holder_addresses[rank].text
holders_dictionary[rank]["quantity"] = float(
holder_quantities[rank].text.replace(",", "")
)
holders_dictionary[rank]["percentage"] = float(
holder_percentages[rank].text[:-1].replace(",", "")
)
page_dictionary["holders_dictionary"] = holders_dictionary
page_dictionary["overview_dictionary"] = overview_dictionary
return page_dictionary
body = get_bscscan()
results_array = parse_body(body)
for token_dictionary in results_array:
page_dictionary = parse_token_page(token_dictionary)
token_dictionary["page_dictionary"] = page_dictionary
print(token_dictionary)
with open("results.json", "w+") as f:
json.dump(results_array, f, indent=2)
Example Output
[
{
"position": 0,
"name": "BadCatInu",
"compiler": "Solidity",
"compiler_version": "0.8.9",
"license": "None",
"balance": "0 BNB",
"transactions": 5,
"address": "0xC738d57C55A1D833C67B65307A00e1D7225bF7C2",
"contract_url": "https://bscscan.com/address/0xC738d57C55A1D833C67B65307A00e1D7225bF7C2",
"token_url": "https://bscscan.com/token/0xC738d57C55A1D833C67B65307A00e1D7225bF7C2#balances",
"holders_url": "https://bscscan.com/token/tokenholderchart/0xC738d57C55A1D833C67B65307A00e1D7225bF7C2?range=500",
"page_dictionary": {
"name": "BadCatInu",
"holders_dictionary": {
"0": {
"address": "PancakeSwap V2: BadCatInu",
"quantity": 984838859.4521563,
"percentage": 98.4839
},
"1": {
"address": "0x9878fd1fc944a83ca168a6293c51b34f8eb0edad",
"quantity": 4246399.318395532,
"percentage": 0.4246
},
"2": {
"address": "0xa6364afb914792fe81e0810d5f471be172079f7b",
"quantity": 4206903.853294837,
"percentage": 0.4207
},
...
},
"overview_dictionary": {
"token_standart": "BEP-20",
"token_price": 0.0,
"token_marketcap": 0.0,
"token_supply": 1000000000.0,
"token_holders": 5,
"token_transfers": 0
}
}
},
...
]