 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

This is a part of the series of blog posts related to Artificial Intelligence Implementation. If you are interested in the background of the story or how it goes:
This week, we will explore the combined capabilities of SerpApi's powerful Google Images Results Scraper API on top of FastAPI's fast to build web framework. We will start by creating a simple image database creator with sync method, and build up from there.
What is meant by Scalable Classifier?
The term refers to scalability in expanding image database to be used in Machine Learning training process, and expansion or retraining of the model in scale with minimal effort. In simple terms, if you have a model that differentiates between a cat and a dog, you should be able to expand it easily by automatically collecting monkey images, and retraining, or expanding the existing classifier.
Minimal FastAPI Folder Structure with Explanations
datasets: This folder will be where we will store the images we will download, store the old download history, and split the test database into train database.datasets -> test: This folder will contain different folders within itself with names of the queries. Each folder with the name of a query will contain the images we will use.datasets -> train: Not in scope of this week. But it will be a replica of the test folder in terms of structure. However it will have less number of images in each folder than test folder for training purposes.datasets -> previous_images.json: This file will contain previous links that has already been downloaded to avoid redownloading the same image.add.py: This file will be responsible for collecting unique links from SerpApi's Google Images Results Scraper API, and then downloading the images into their corresponding places.main.py: Main file for running server and defining routes.requirements.txt: Libraries we use in running Serpapi. You need to download them via pip.
Requirements
Here are the required libraries we need to add into requirements.txt file.
App Configuration
FastApi, as the name suggests, allows for a rapid development process with minimal effort. We will add two routes in main.py for now, one which greets the user, another one that accepts the Query object from an endpoint:
Query class will contain the pydantic base model object which contains the parameters to use for getting different results from SerpApi's Google Images Scraper API. Download class will oversee the entire process.
As for the background process of add endpoint, let's import necessary libraries in add.py:
from multiprocessing.dummy import Array : It's an automatically added library for multiprocessing purposes
from serpapi import GoogleSearch : It's SerpApi's library for using various engines SerpApi supports. You may find more information on its Github Repo. Simply install it via pip install google-search-results command.
from pydantic import BaseModel : Pydantic allows us to create object models with ease.
import mimetypes : Mimetypes is useful for guessing the extension of the downloaded element before you write it into an image. It allows us to guess .jpg, .png etc. extensions of files.
import requests : Python's HTTP requests library with the coolest logo ever made for a library.
import json : For reading and writing JSON files. It will be useful for storing old links of images we have already downloaded.
import os : For writing images in local storage of the server, or creating folders for different queries.
Let's see how to contain queries we make to the add endpoint:
In this Pydantic model, q, and api_key parameters must be given. However as I stated in the comment, you can hardcode your api_key with the given method, so that you won't have to enter it at each attempt. The api_key in question refers to the SerpApi API key. You can register to a free or paid account via our register link here. Your unique API key can be found in the Manage API Key page.
SerpApi serves cached results for free. It means if the search for Apple is cached, you will get it for free. But if you queried Monkey, and it is not in our cache, or the cache you have created, it will consume one credit from your account.
google_domain : Which domain of Google Images will be scraped.
num : Number of results for the given query. It is defaulted to 100 which is the maximum value.
ijn : Refers to the page number. Defaults to 0 The results will start from ijn x num and end in (ijn x num) + num (These formulas are for ideal scenarios. Google might not serve that much of data for some queries.) Starting result index will be 0 by default since default ijn is 0.
q : Refers to the query you want to make to expand the image database.
api_key: Refers to SerpApi API Key.
Downloading Images
Let's declare the class we will download images:
self.query : Where we store the query made in a Class Object
self.results : Where we store all image links found in a Google Image Search.
self.previous_results : Previous downloaded, or skipped (will explain below) image links to avoid redownloading.
self.unique_results : Unique links we gathered from the query we must download to expand the image database.
self.new_results: Combination of previous results and unique results to be written in a JSON file.
Let's define the function responsible for making queries to SerpApi:
As you can see, some parameters such as engine, and tbm are predefined. These parameters are responsible for scraping SerpApi's Google Images Scraper API. When you make the following query to SerpApi, it will return a JSON containing different parts of the SERP result:
https://serpapi.com/search?engine=google&google_domain=google.com&ijn=0&num=100&q=Apple
This is essentially what the SerpApi Python Library does. The result will be like the following:
Here's the raw HTML file SerpApi can make sense and serve it as JSON:
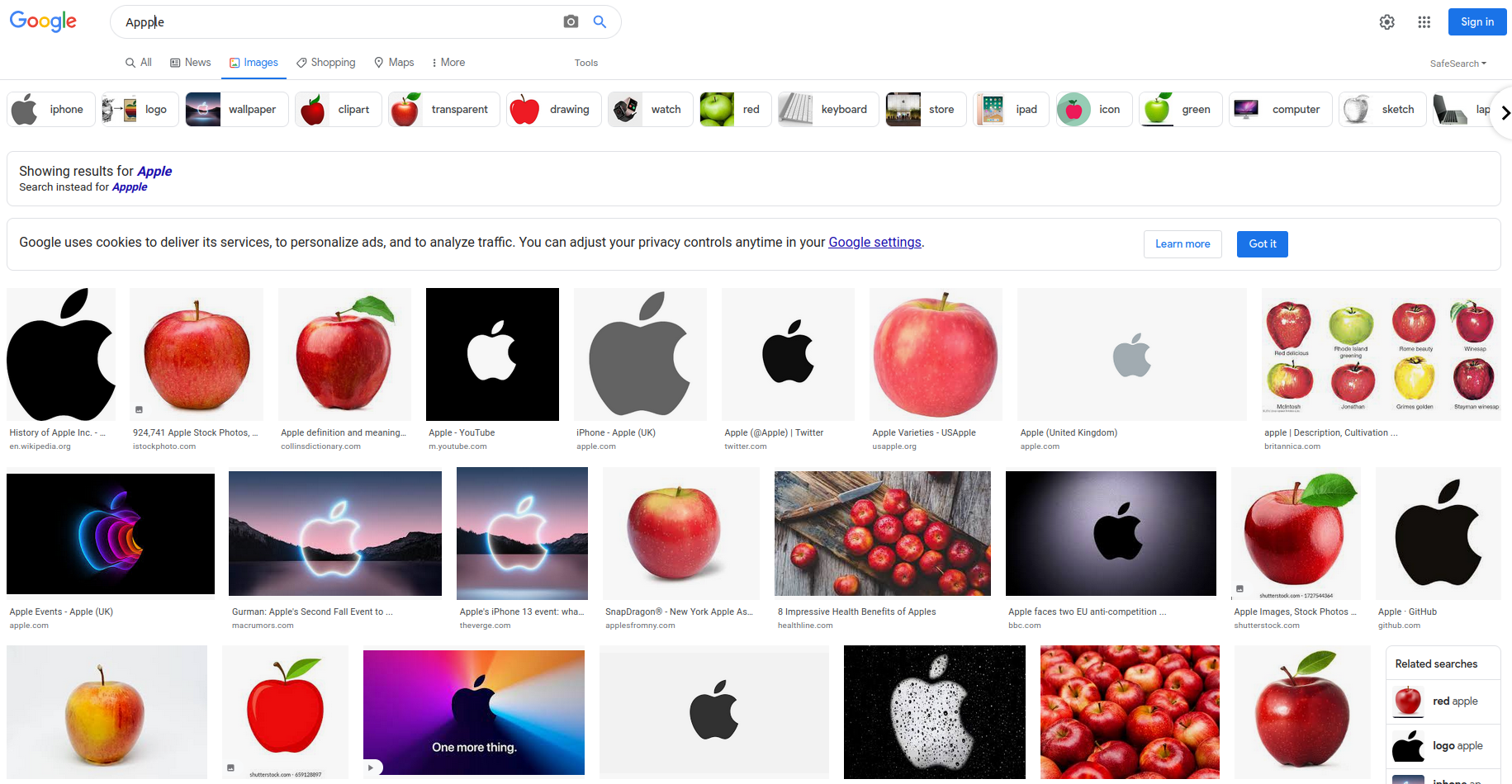
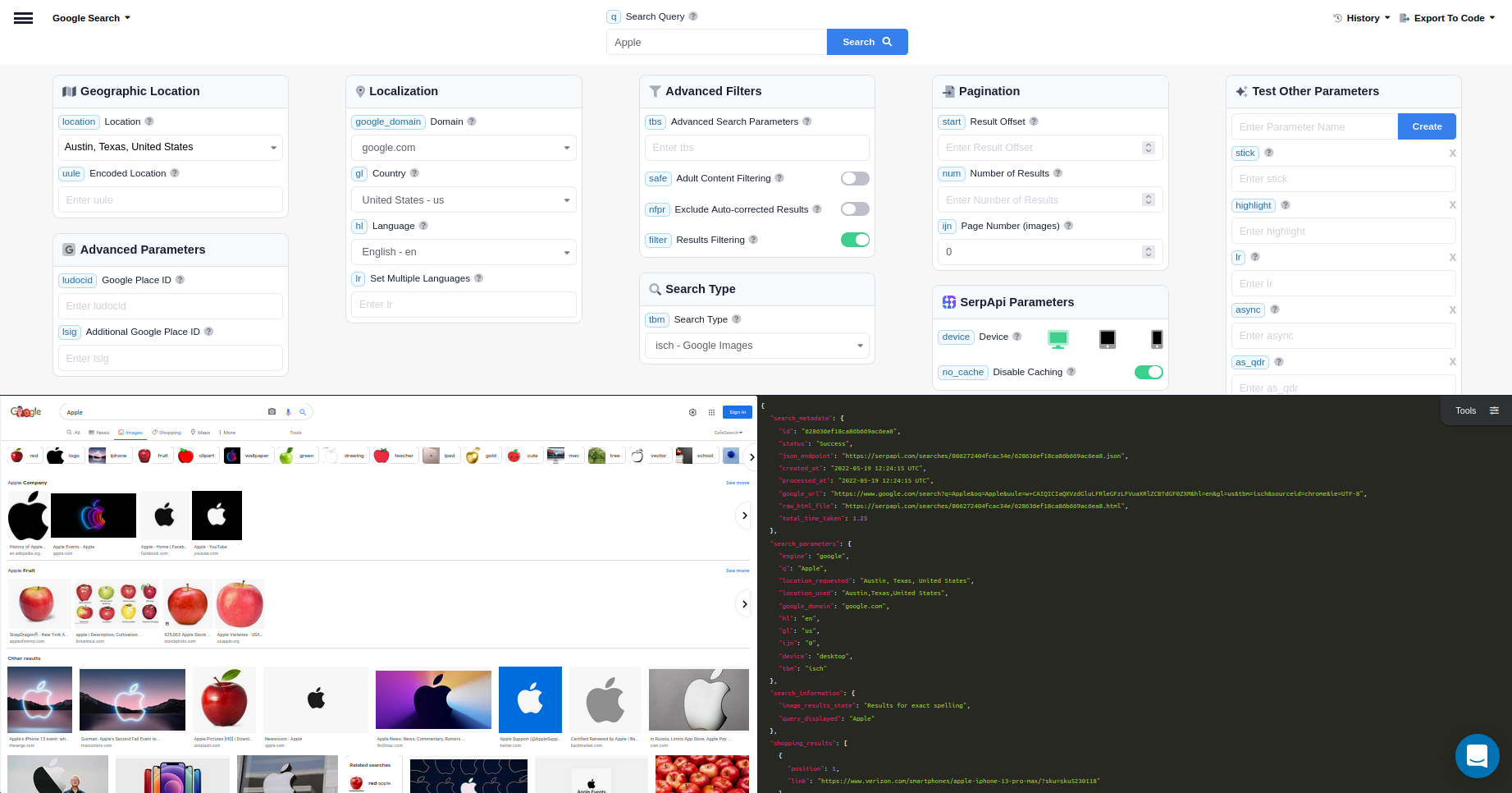
You can also head to the SerpApi Playground for more visual experience, and ability to tweak. Simply change the search? in the link to playground?:
https://serpapi.com/search?engine=google&google_domain=google.com&ijn=0&num=100&q=Apple
We are interested in original keys of the images_results, since they are a direct link to download original sized images. For further information on the Engine, you may head to the Documentation for SerpApi's Google Images Scraper API, and explore further options.
Let's explore how to check for older downloaded links, and separate unique results:
We read the previous_images.json file and look for previous key within it. Then, the last line determines the unique results.
Let's break down this function in several steps. First, we want to define a path to download:
But we also need to check if such a path exists. For example if our query is Apple, we need a folder like datasets/test/apple to exist. If it doesn't exist, we create one.
Let's look at name selection for the downloaded image:
We will give numbers to images to keep the names unique. If there isn't any file downloaded yet, the name will be 0. If there is, then the name will be maximum number incremented by 1.
Let's take a look at guessing extension, and downloading the image to its proper path:
We use the link to get the image as bytes, then guess the image extension. Mimetype guesses `.webp` images as `html`. So we make a safeguard for this situation, and write the image using the path and extension we have generated before.
Now let's take a look at how to update the JSON file we store for making unique downloads in the future:
Since every function is ready, let's look at the function that encompasses overall process we call from the add endpoint.
We put a little try and except block there to make sure there are no unexpected errors in the requesting process.
Running the App with Uvicorn
FastApi can be deployed on your local machine using the command from the path of your app:
uvicorn main:app --host 0.0.0.0 --port 8000
You'll see the following prompt:
INFO: Started server process [14880]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
This means that your server is running without a problem. If you head to localhost:8000 on your local machine, you will be greeted with such a structure:
{"Hello":"World"}
This is the main page of the app. This will be shaped in upcoming blog posts.
Let's head to localhost:8000/docs:
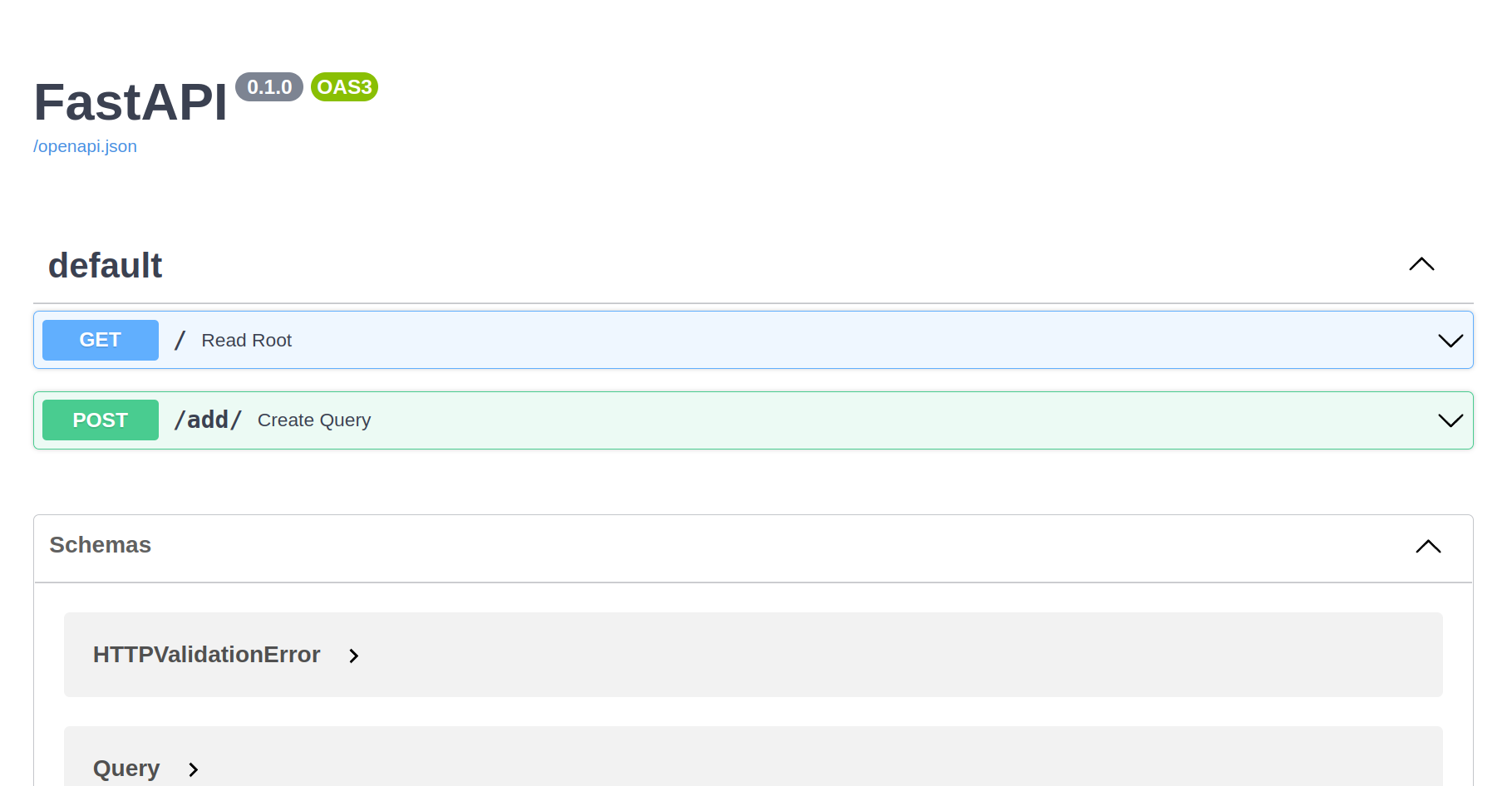
FastApi allows for automatic documentation and playground for the app. This is useful for us to test our endpoints manually. This is useful for us to manually create a post request to the add endpoint. Simply click on the button with Create Query:
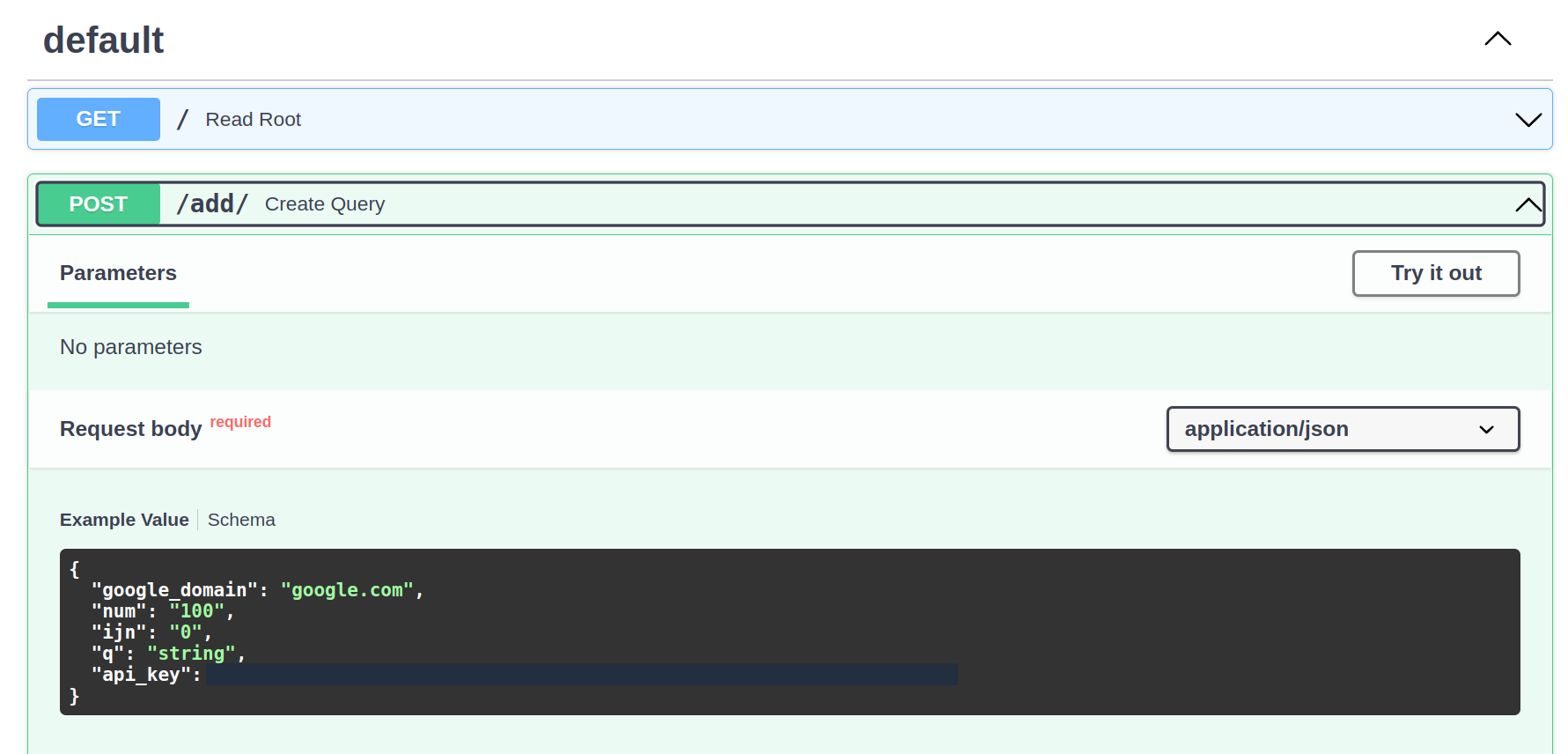
Next, click on Try it out button:
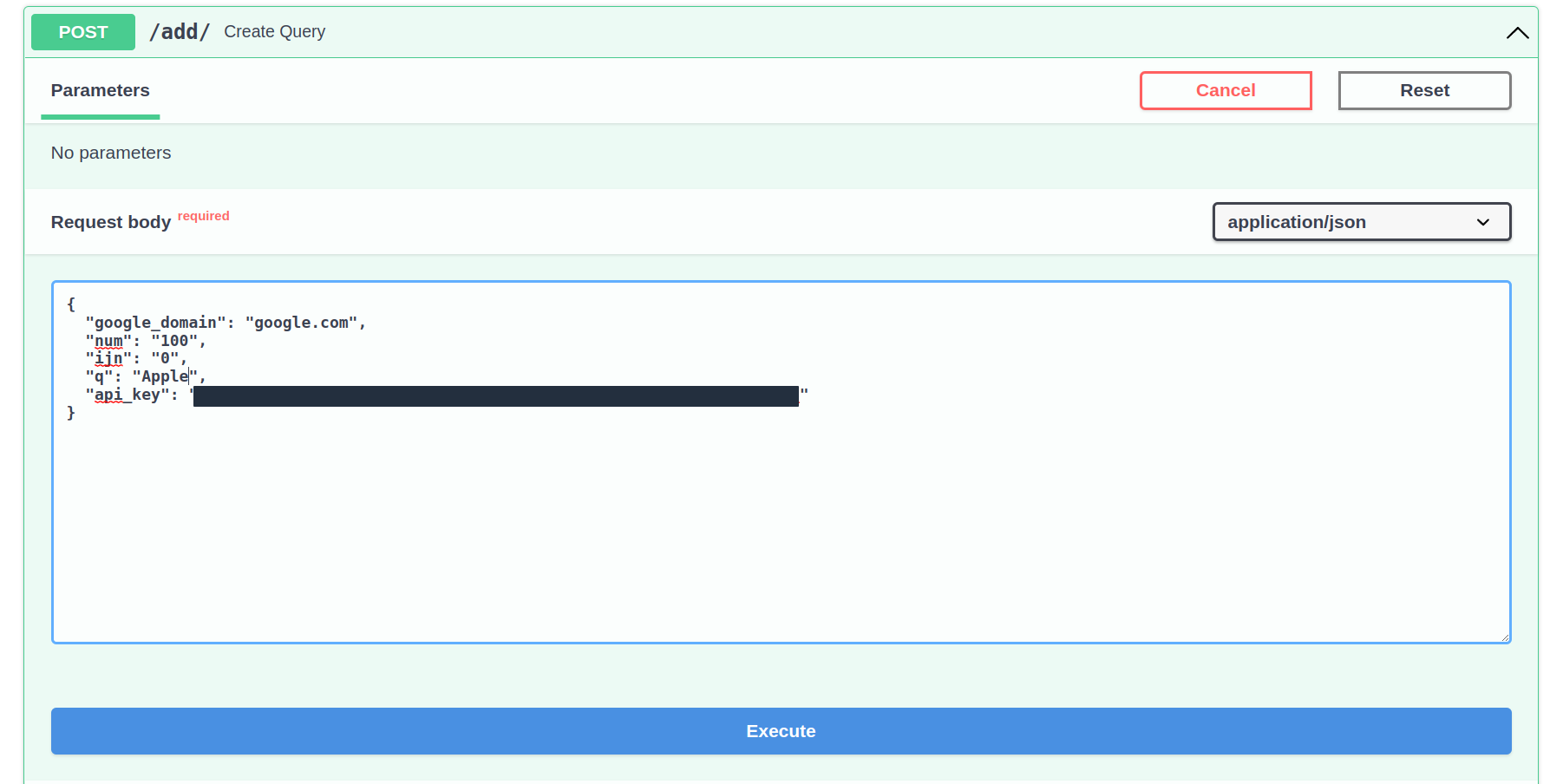
Change the api_key parameter to your API key, and change the q to the query you desire to expand the database with.
Before we press execute, let's take a look at the folder structure:
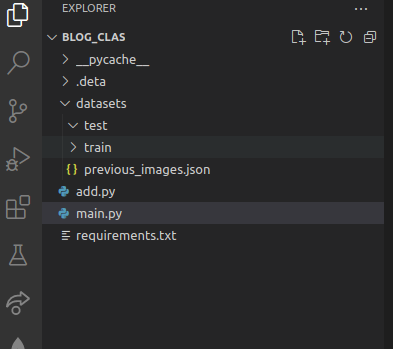
As you can see the datasets -> test folder is empty, and upon execution it will be filled with images.
Let's press the Execute button in our browser, and see the changes:
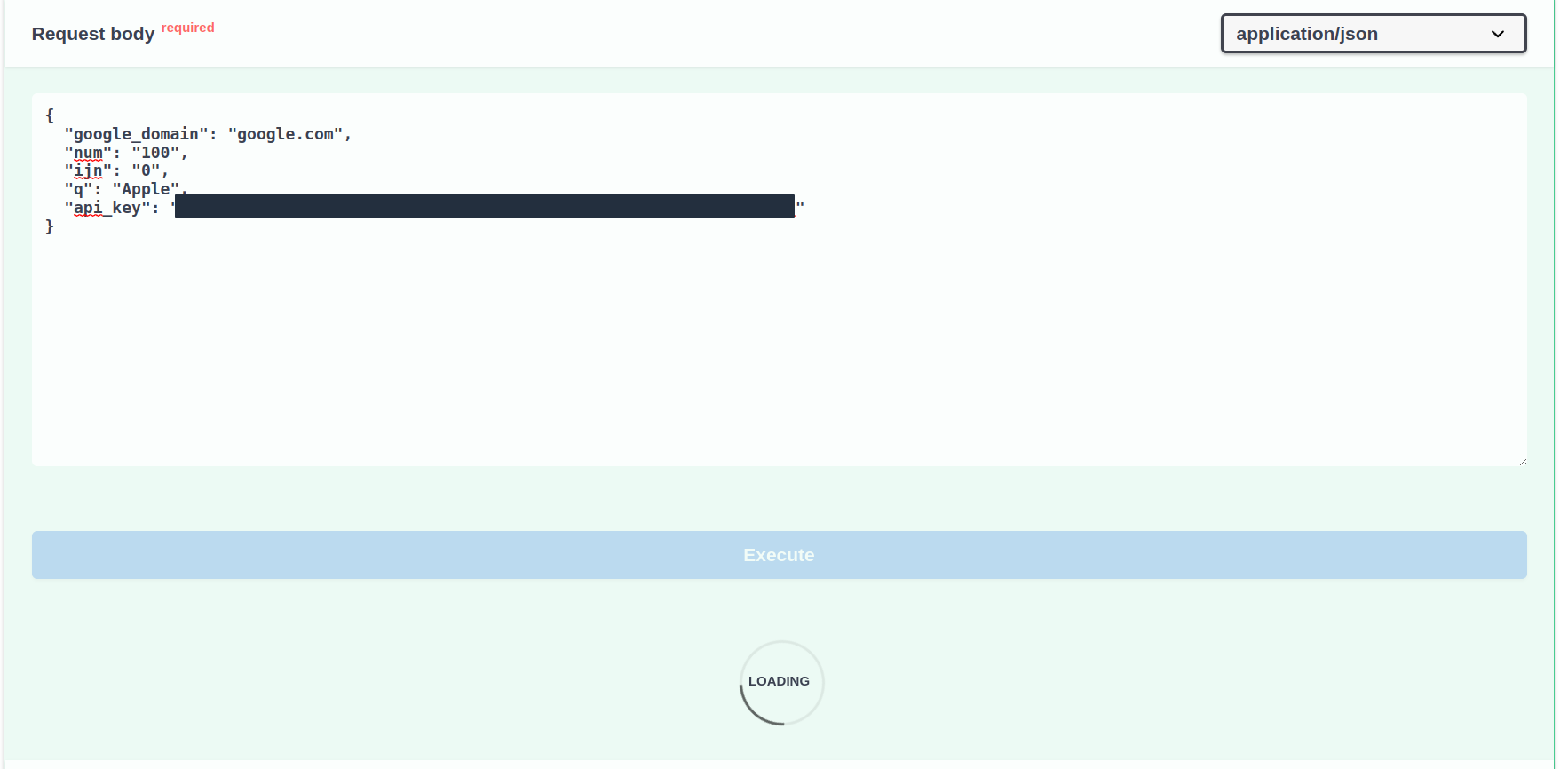
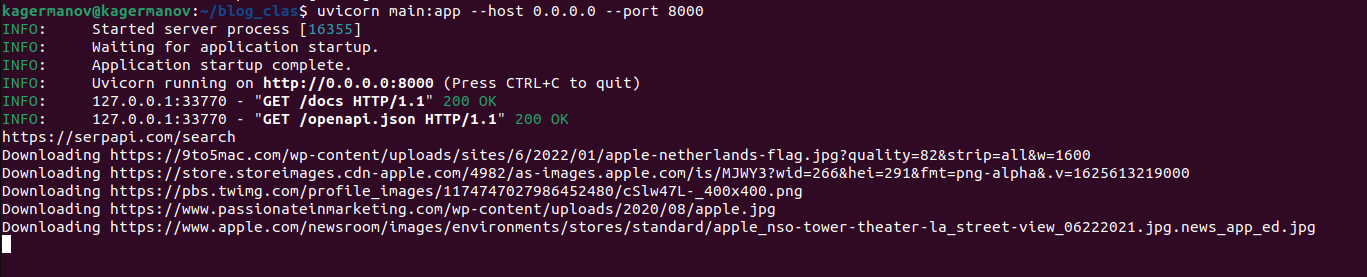
You will automatically see changes in the browser, and in the terminal.
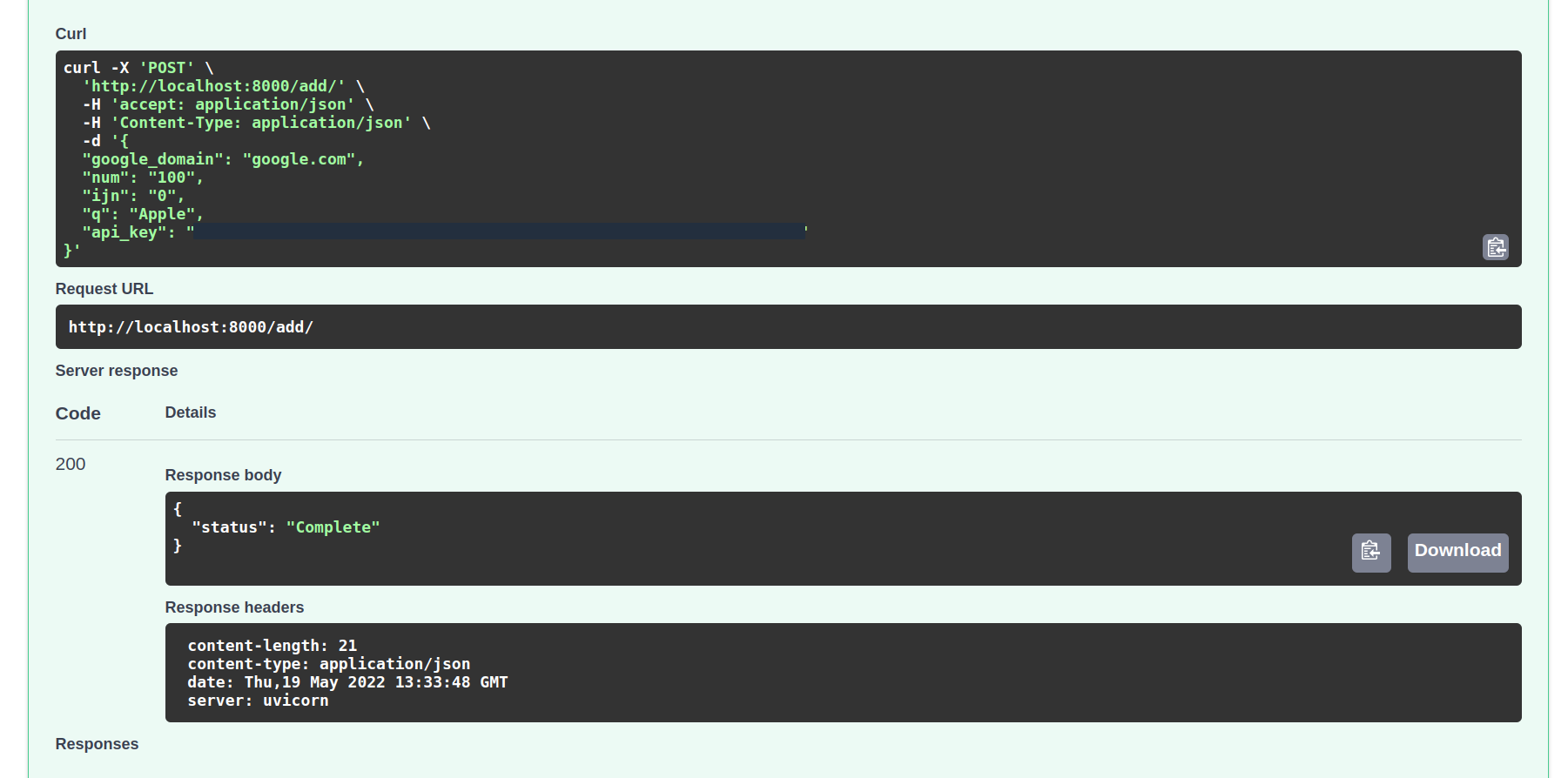
Upon completion, you can observe the response in your browser:
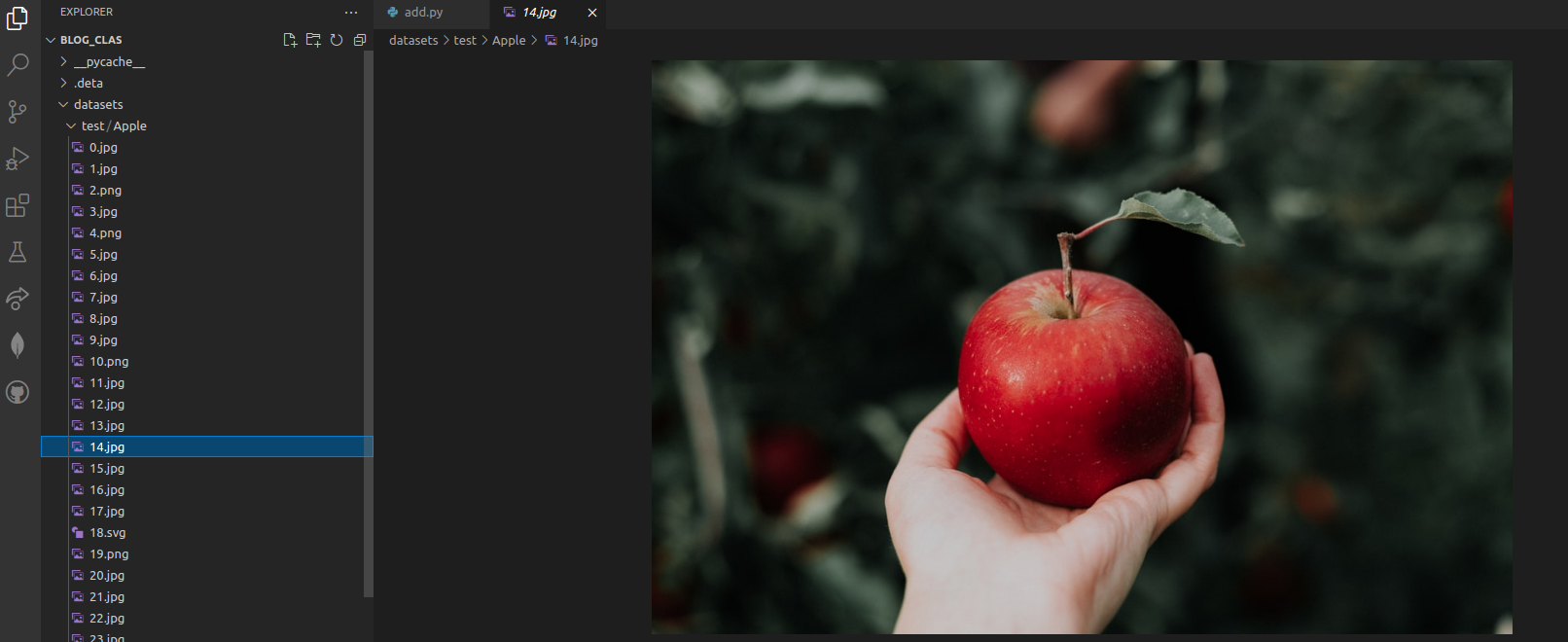
You can also head to your folder to see that the images have been updated:
Full Code
main.py
add.py
requirements.txt
datasets/previous_images.json
Conclusion
I apologize to the readers for being one day late in publishing, and thank them for their attention. This week we have covered how to create a scalable image database maker with SerpApi and FastApi, and run the app on Uvicorn. Two weeks later, we will explore how to add async processes, and implement Pytorch. I am grateful to the brilliant people of SerpApi for this chance.