 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

In my previous blog post, we already scraped a list of restaurants at a location. It's easy to do so when we scrape Google Maps results with SerpApi.
To generate the leads, we need to scrape the details of each restaurant, like phone numbers, emails, and social media links. This guide will demystify the process.
First we need to know how to scrape this information from a random website manually. We will use the Chrome DevTools to inspect the page and scrape emails from it.
Scraping emails from a random page manually
Let's scrape the emails from a restaurant in the last post: https://swillhouse.com/venues/restaurant-hubert/.
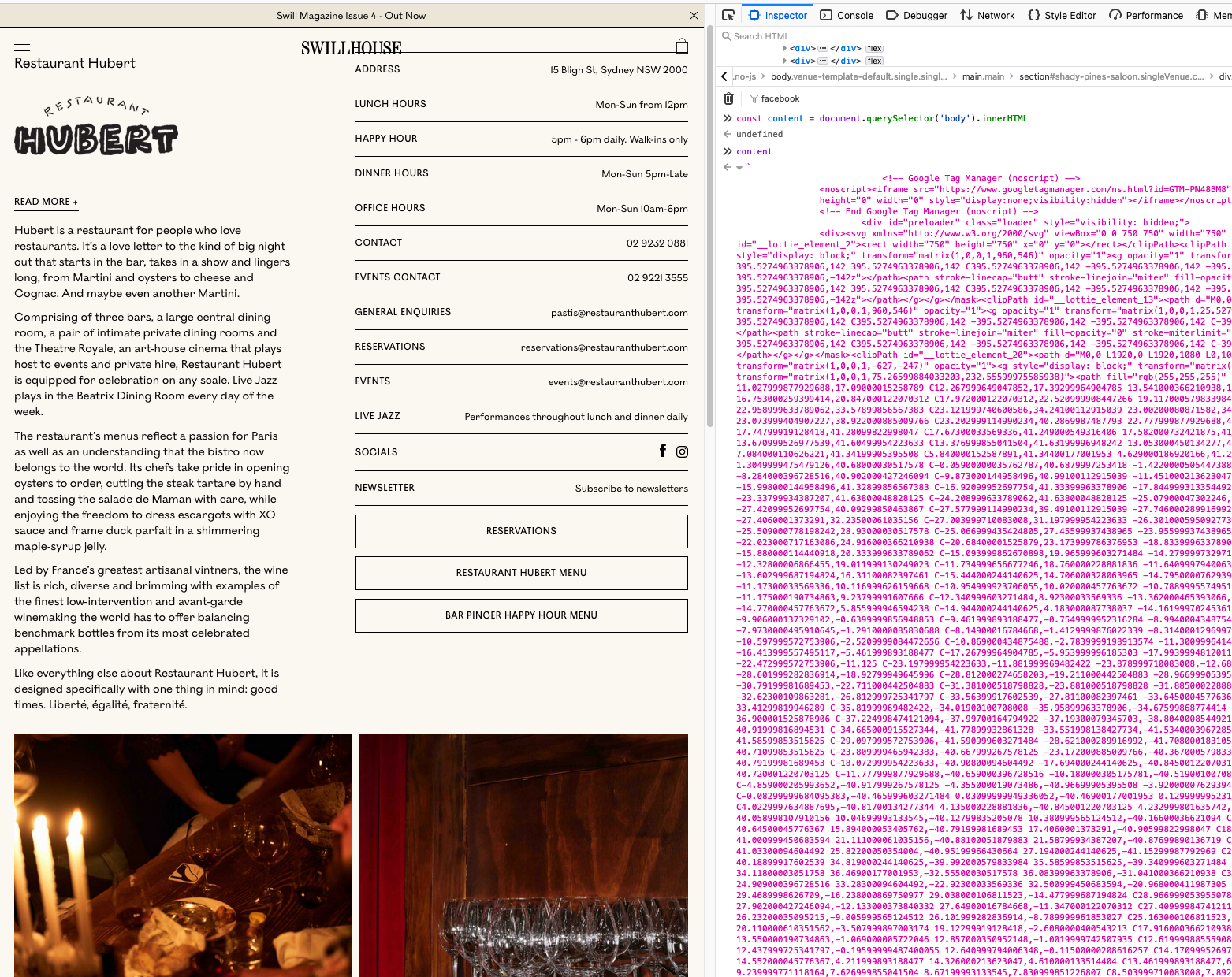
Open Chrome DevTools and go to the Console tab. We need to get all texts from the website using this Javascript code:
const content = document.querySelector('body').innerHTML;
Now we have all the texts from the page, we need to extract emails from it. We can use this regex to extract emails from the text:
const emails = content.match(/([a-zA-Z0-9._-]+@[a-zA-Z0-9._-]+\.[a-zA-Z0-9_-]+)/gi);
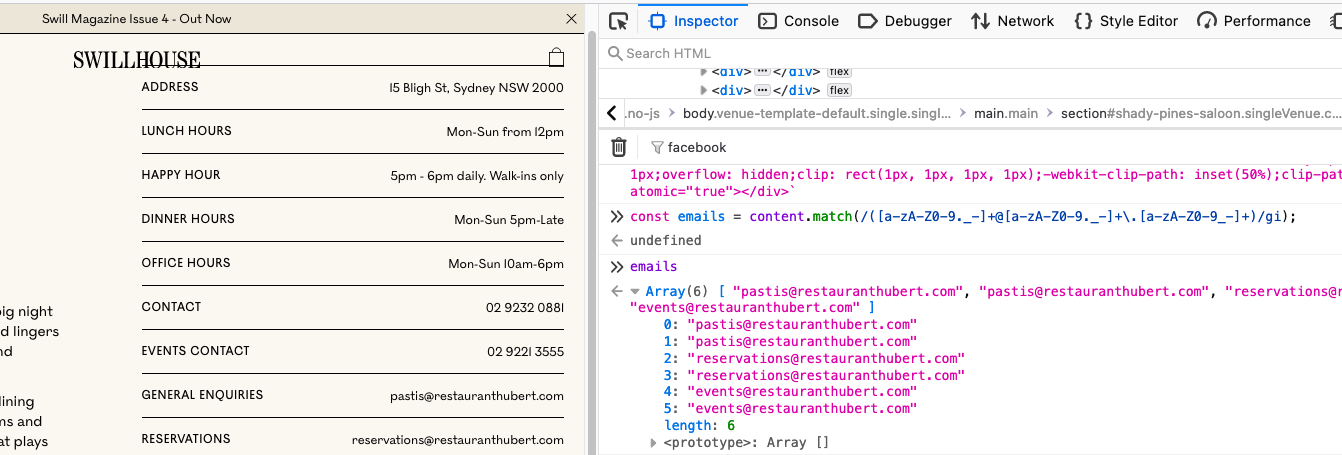
It's pretty easy to extract emails from a page. How can we scrape phone numbers, social media links, etc?
We need to use the same method to extract them from the page.
There are a lot of phone number formats. It's different from country to country. Different websites can use different formats.
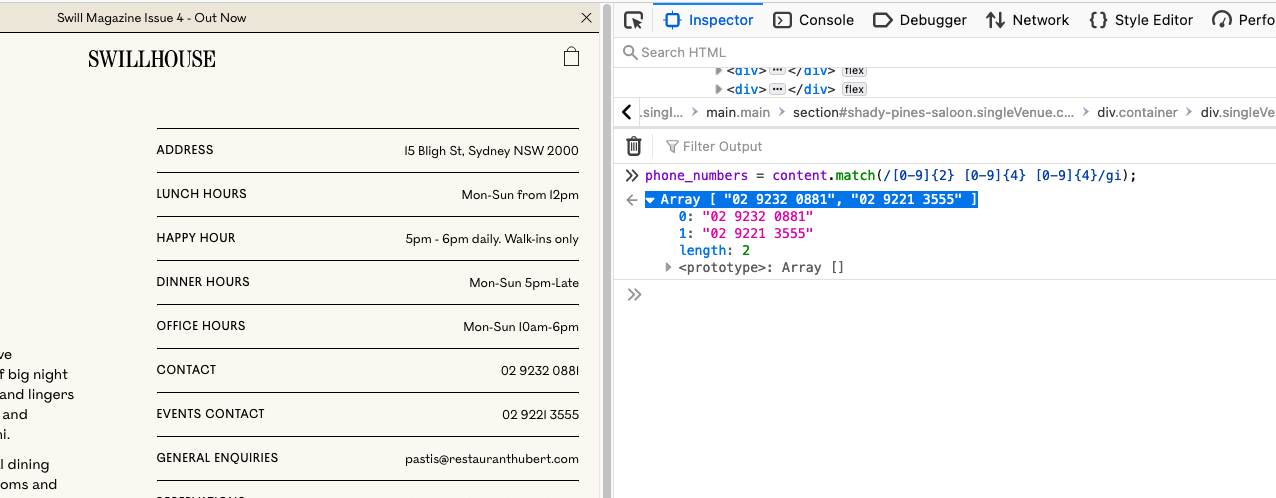
In this example, we will extract phone numbers in this format: 00 0000 0000. We can use this regex to extract phone numbers from the text.
const phoneNumbers = content.match(/[0-9]{2} [0-9]{4} [0-9]{4}/gi);
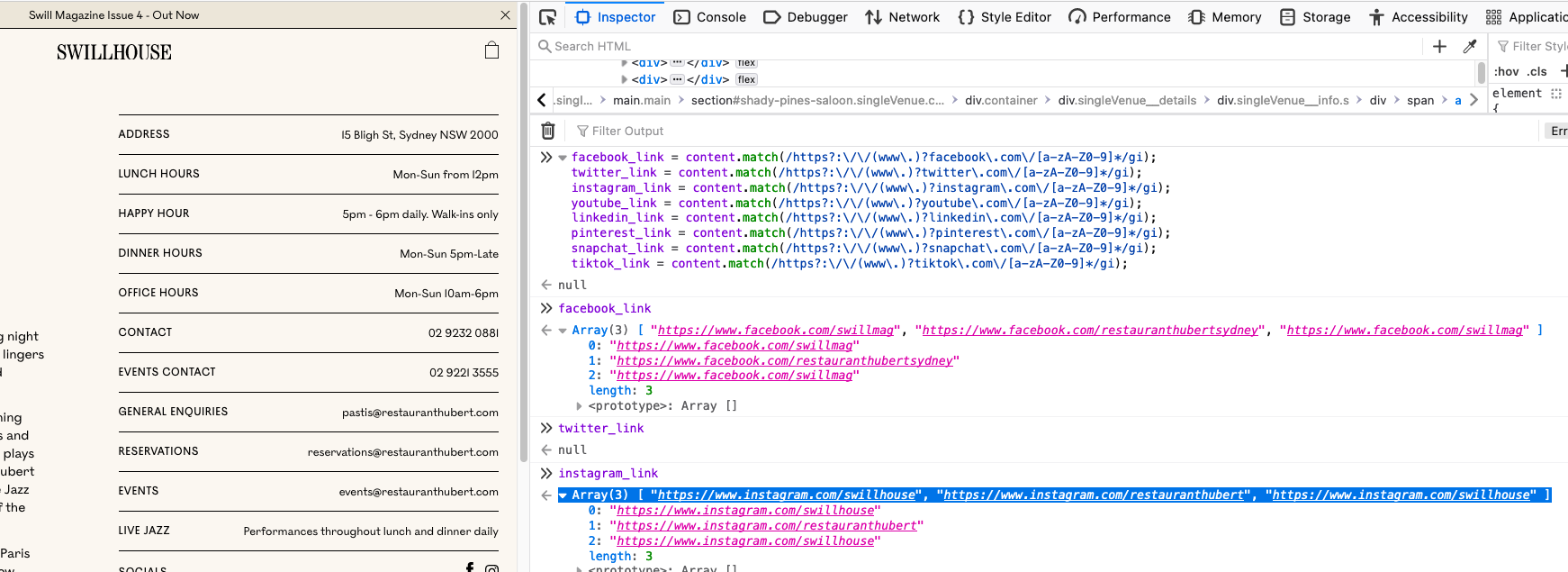
There are a lot of social media pages. We will extract Facebook, Twitter, Instagram, Youtube, Linkedin, Pinterest, Snapchat, TikTok, etc.
const facebook = content.match(/https?:\/\/(www\.)?facebook\.com\/[a-zA-Z0-9]*/gi);
const twitter = content.match(/https?:\/\/(www\.)?twitter\.com\/[a-zA-Z0-9]*/gi);
const instagram = content.match(/https?:\/\/(www\.)?instagram\.com\/[a-zA-Z0-9]*/gi);
const youtube = content.match(/https?:\/\/(www\.)?youtube\.com\/[a-zA-Z0-9]*/gi);
const linkedin = content.match(/https?:\/\/(www\.)?linkedin\.com\/[a-zA-Z0-9]*/gi);
const pinterest = content.match(/https?:\/\/(www\.)?pinterest\.com\/[a-zA-Z0-9]*/gi);
const snapchat = content.match(/https?:\/\/(www\.)?snapchat\.com\/[a-zA-Z0-9]*/gi);
const tiktok = content.match(/https?:\/\/(www\.)?tiktok\.com\/[a-zA-Z0-9]*/gi);
That's all, we can scrape all information from a page. We can use the same method to scrape all information from all pages.
Scraping emails from a random page
In my previous example, we used Python to scrape Google Maps results with SerpApi. In this example, we will automate scraping emails, phone numbers, and social media links from a random page with Python.
First we need to get all HTML from the page. We can use the requests library to get the HTML from the page.
import requests
try:
html = requests.get(url).text
except:
print ("Error occurred. Continue scraping...")
We don't want to stop our script if an error occurs. We will use try/except to continue scraping if an error occurs.
Then we extract emails, phone numbers, and social media links from the HTML. We can use the "re" library to extract them.
import requests
import re
lead_headers = ['website', 'email', 'phone', 'facebook', 'twitter', 'instagram', 'youtube', 'linkedin', 'pinterest', 'snapchat', 'tiktok']
with open('google_maps_leads.csv', 'w', encoding='UTF8', newline='') as f:
writer = csv.writer(f)
writer.writerow(lead_headers)
for item in results:
if item.get('website'):
url = item.get('website')
try:
html = requests.get(url).text
emails = re.findall(r'([a-zA-Z0-9._-]+@[a-zA-Z0-9._-]+\.[a-zA-Z0-9_-]+)', html)
phone_numbers = re.findall(r'[0-9]{2} [0-9]{4} [0-9]{4}', html)
facebook = re.findall(r'(https?:\/\/w?w?w?\.?facebook\.com\/[a-zA-Z0-9]*)', html)
twitter = re.findall(r'(https?:\/\/w?w?w?\.?twitter\.com\/[a-zA-Z0-9]*)', html)
instagram = re.findall(r'(https?:\/\/w?w?w?\.?instagram\.com\/[a-zA-Z0-9]*)', html)
youtube = re.findall(r'(https?:\/\/w?w?w?\.?youtube\.com\/[a-zA-Z0-9]*)', html)
linkedin = re.findall(r'(https?:\/\/w?w?w?\.?linkedin\.com\/[a-zA-Z0-9]*)', html)
pinterest = re.findall(r'(https?:\/\/w?w?w?\.?pinterest\.com\/[a-zA-Z0-9]*)', html)
snapchat = re.findall(r'(https?:\/\/w?w?w?\.?snapchat\.com\/[a-zA-Z0-9]*)', html)
tiktok = re.findall(r'(https?:\/\/w?w?w?\.?tiktok\.com\/[a-zA-Z0-9]*)', html)
writer.writerow([item['website'], emails, phone_numbers, facebook, twitter, instagram, youtube, linkedin, pinterest, snapchat, tiktok])
except:
print ("Error occurred. Continue scraping...")
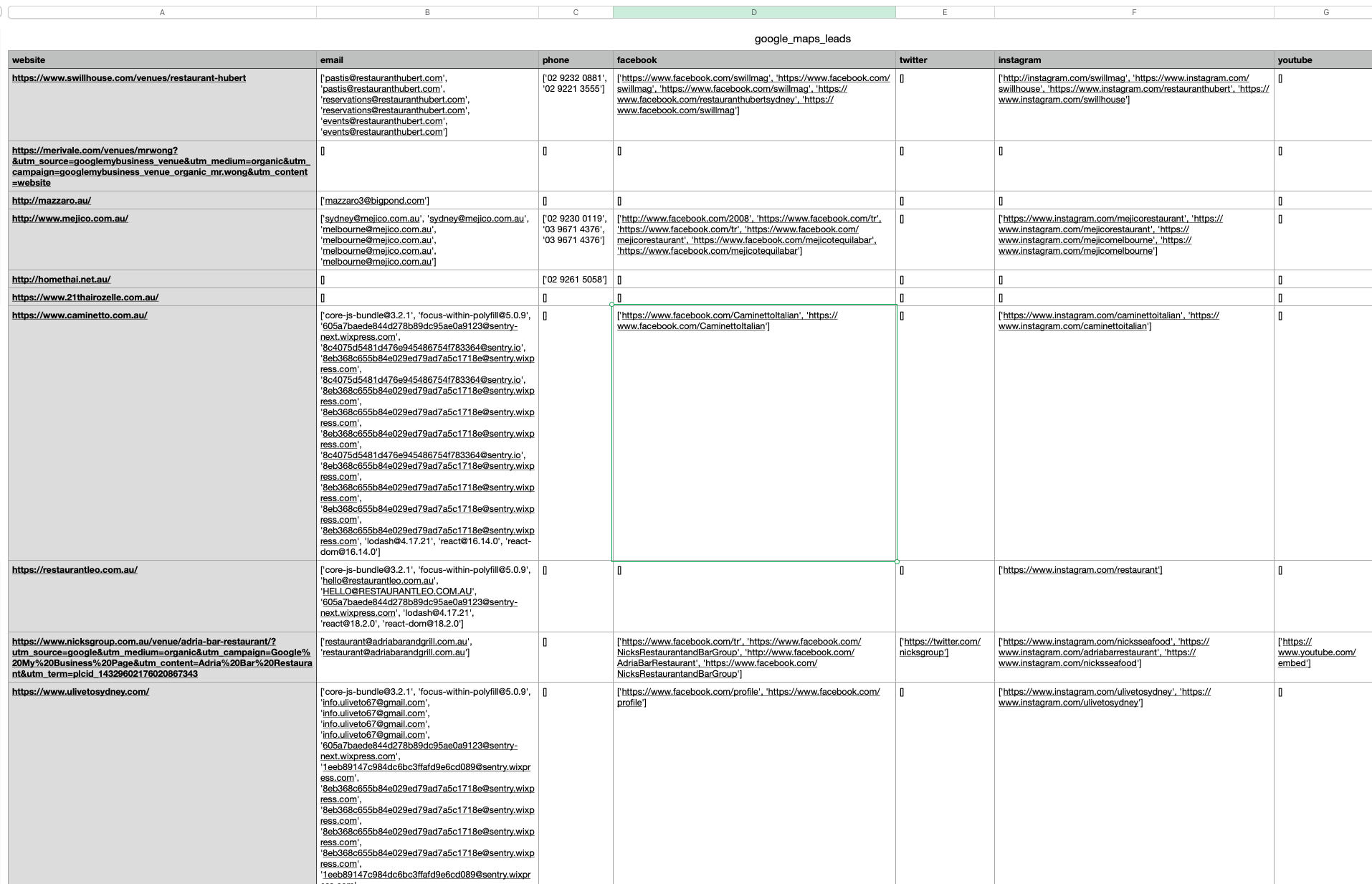
This code snippet is to prototype rough ideas on generating the leads. In reality, we need to manage the proxy to avoid getting blocked from websites, support multiple phone numbers format, filter duplicated results, and consolidate the social media's link formats.
If you have any questions, please feel free to contact me.
