 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

After insufficient success rates mentioned in last week's blog post (around 60%), we decided to give a shot to n-gram linear model rather than a character level RNN.
In this model, we will be using n different words in sequences to create unique tensors for problematic values of keys inside SerpApi's Google Local Results Scraper API.
Spoiler alert, it works. Here's an example output of the model:
Chipotle Mexican Grill is title
3.9 is rating
181 is reviews
Coffee shop is type
+1 949-581-XXXX is phone
323X N Rock R is address
Takeout: 8AM–2PM is hours
$$ is price
Desserts & savory bites offered in a Victorian home with romantic patio doubling as a hookah garden. is description
Custom Data Loading
One of the challenges I met when trying to construct a meaningful model was the loading of data. There were many examples of n-gram modeling without using Torchtext around to take example. Naturally they were on python, and they were hard to utilize in Rails.
Luckily, the data loader codes of traditional datasets like AG_NEWS were open and I took an example of them to create a custom data loader to feed the data in batches to the model.
module Datasets
module TextClassification
class << self
def local_pack(*args, **kwargs)
setup_datasets("LOCAL_PACK", *args, **kwargs)
end
private
def setup_datasets(dataset_name, ngrams: 1, vocab: nil, include_unk: false)
train_csv_path = "ml/google/local_pack/data/local_pack_en-us_train.csv"
test_csv_path = "ml/google/local_pack/data/local_pack_en-us_test.csv"
if vocab.nil?
vocab = TorchText::Vocab.build_vocab_from_iterator(_csv_iterator(train_csv_path, ngrams))
else
unless vocab.is_a?(TorchText::Vocab)
raise ArgumentError, "Passed vocabulary is not of type Vocab"
end
end
train_data, train_labels = _create_data_from_iterator(vocab, _csv_iterator(train_csv_path, ngrams, yield_cls: true), include_unk: false)
test_data, test_labels = _create_data_from_iterator(vocab, _csv_iterator(test_csv_path, ngrams, yield_cls: true), include_unk: false)
if (train_labels ^ test_labels).length > 0
raise ArgumentError, "Training and test labels don't match"
end
[
TorchText::Datasets::TextClassificationDataset.new(vocab, train_data, train_labels),
TorchText::Datasets::TextClassificationDataset.new(vocab, test_data, test_labels),
]
end
def _csv_iterator(data_path, ngrams, yield_cls: false)
return enum_for(:_csv_iterator, data_path, ngrams, yield_cls: yield_cls) unless block_given?
numerization_of_labels = {
"title" => 0,
"rating" => 1,
"reviews" => 2,
"type" => 3,
"phone" => 4,
"address" => 5,
"hours" => 6,
"price" => 7,
"description" => 8
}
tokenizer = TorchText::Data.tokenizer("basic_english")
CSV.foreach(data_path) do |row|
tokens = row[1..-1].join(" ")
tokens = tokenizer.call(tokens)
if yield_cls
yield numerization_of_labels[row[0]].to_i, TorchText::Data::Utils.ngrams_iterator(tokens, ngrams)
else
yield TorchText::Data::Utils.ngrams_iterator(tokens, ngrams)
end
end
end
def _create_data_from_iterator(vocab, iterator, include_unk)
data = []
labels = []
iterator.each do |cls, tokens|
if include_unk
tokens = Torch.tensor(tokens.map { |token| vocab[token] })
else
token_ids = tokens.map { |token| vocab[token] }.select { |x| x != TorchText::Vocab::UNK }
tokens = Torch.tensor(token_ids)
end
data << [cls, tokens]
labels << cls
end
[data, Set.new(labels)]
end
end
DATASETS = {
"LOCAL_PACK" => method(:local_pack)
}
LABELS = {
"LOCAL_PACK" => {
0 => "title",
1 => "rating",
2 => "reviews",
3 => "type",
4 => "phone",
5 => "address",
6 => "hours",
7 => "price",
8 => "description"
}
}
end
class LOCAL_PACK
def self.load(*args, **kwargs)
TextClassification.local_pack(*args, **kwargs)
end
end
endlocal_pack_en-us_test.csv is the test dataset we use:
| q | page_range |
|---|---|
| title | Starbucks |
| rating | 4.9 |
| reviews | 811 |
| hours | Takeout: 8AM–2PM |
| type | Coffee Shop |
This dataset is all the gathered and processed data we collected using SerpApi's Google Local Results Scraper API. You can find the relevant information on blog post #2.
We will be using a subset of test database called train database to train our model. It is named local_pack_en-us_test.csv. This way we can construct some intuition about the model's real world application, by providing it data that it isn't trained with to score the outcome.
Model
Here's an image describing the model for better understanding.
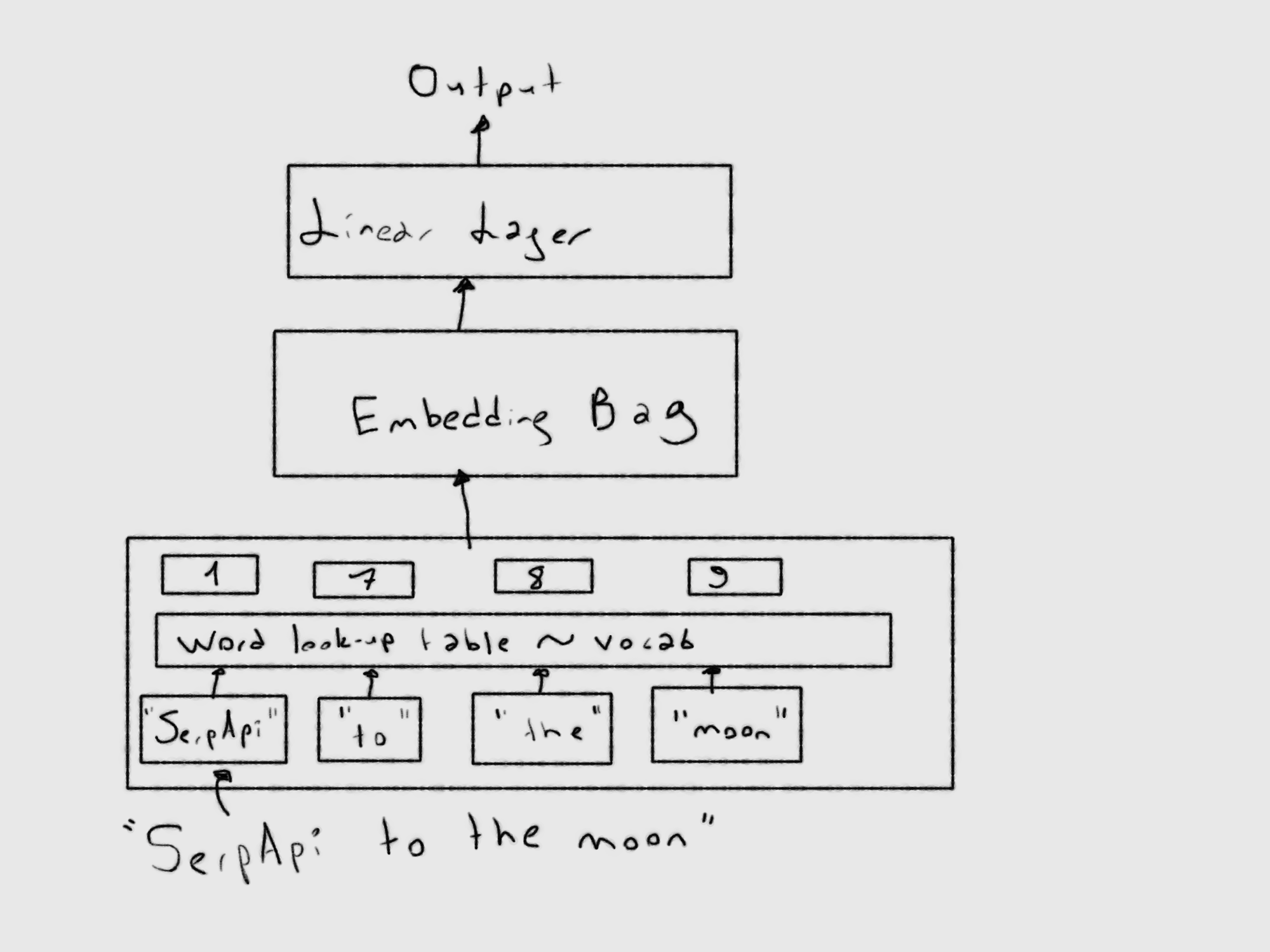
One thing to consider here is that we are using word to index probabilistic distribution. This means, even though our set would yield good results, the dataset may still need expansion for different words.
module PredictValue::Model
class GLocalNet < Torch::NN::Module
def initialize(vocab_size, embed_dim, num_class)
super()
@embedding = Torch::NN::EmbeddingBag.new(vocab_size, embed_dim, sparse: true)
@fc = Torch::NN::Linear.new(embed_dim, num_class)
init_weights
end
def init_weights
initrange = 0.5
@embedding.weight.data.uniform!(-initrange, initrange)
@fc.weight.data.uniform!(-initrange, initrange)
@fc.bias.data.zero!
end
def forward(text, offsets)
embedded = @embedding.call(text, offsets: offsets)
@fc.call(embedded)
end
end
GLocalNet
endAs seen in the above code, we will be passing embeddings to a linear layer. Weights will be redistributed at each epoch to give us better results. In fact, this is linear regression with tensors in its nature.
Training
ngrams = 2
@learning_rate = 5
batch_size = 128
embed_dim = 128
n_epochs = 20
train_dataset, test_dataset = Datasets::LOCAL_PACK.load(ngrams: ngrams)
vocab_size = train_dataset.vocab.length
nun_class = train_dataset.labels.length
device = "cpu"
@all_losses = []
min_valid_loss = Float::INFINITYngrams will define the neighbouring sequence we must take into consideration when creating tensors out of words.
@learning_rate will be the optimized learning rate of our model. You might consider 5 too high, but the fact is we train in batches this time.
batch_size will be the number of items in a batch to train at each epoch.
embed_dim dimension of the state space used for constructing the embedding's connections with the linear layer
n_epochs will be the number of epochs we will train the model in. Unlike learning rate, this value goes down when we increase the batch size and embedding dimension since much more is achieved in one epoch.
train_dataset is the dataset we will use to iterate batches of examples to train
test_dataset is the dataset we will use to iterate batches of examples including train_dataset examples and other examples. This will give us the difference in ratio to real world implementation.
vocab_size is the size of all the indexed tensors of words within train_dataset
nun_class is the size of all the labels in train_dataset
device which device to use. cuda is applicable too. But I had a local problem running it on Ubuntu.
@all_losses all training losses we will collect to rationalize the optimization process by observing graphs.
min_valid_loss a measure to keep the loss from being unrecognazible by the code.
I have swayed the idea of using one of the Adam functions for optimizer as I mentioned in blog post 3 in favor of using sparse embeddings. SparseAdam function wasn't yet implemented in ruby library. (Maybe a future project for a blog post). Let's declare the model and everything else related to model:
model = GLocalNet.new(vocab_size, embed_dim, nun_class).to(device)
criterion = Torch::NN::CrossEntropyLoss.new.to(device)
optimizer = Torch::Optim::SGD.new(model.parameters, lr: @learning_rate)
local_pack_label = {
0 => "title",
1 => "rating",
2 => "reviews",
3 => "type",
4 => "phone",
5 => "address",
6 => "hours",
7 => "price",
8 => "description"
}
vocab = train_dataset.vocabLet's declare the custom lr adjuster we have covered in the previous blog post. You might notice that I haven't included @plot_every in here. It is because it will be adjusted at each epoch, so the adjustment step size will be 1.
def self.ideal_loss_derivative x
Float(-1000000000.0/((x-100.0)*(x-100.0)))
end
def self.adjust_lr epoch
if @all_losses.size > 1
low_training = (@all_losses[-1] - @all_losses[-2] > 0) || (@all_losses[-1] - @all_losses[-2] > ideal_loss_derivative(epoch-1))
high_training = @all_losses[-1] - @all_losses[-2] < ideal_loss_derivative(epoch-1)
if low_training
@learning_rate = @learning_rate * 2
elsif high_training
@learning_rate= @learning_rate * 0.5
end
end
endLet's define the function to predict using the model in the end:
def self.predict(text, model, vocab, ngrams)
tokenizer = TorchText::Data::Utils.tokenizer("basic_english")
Torch.no_grad do
text = Torch.tensor(TorchText::Data::Utils.ngrams_iterator(tokenizer.call(text), ngrams).map { |token| vocab[token] })
output = model.call(text, Torch.tensor([0]))
output.argmax(1).item + 1
end
endAlso the function to save the model:
def self.save_model
Torch.save(@model.state_dict, "ml/google/local_pack/predict_value/trained_models/rnn_value_predictor.pth")
endNow that we have everything set in place, it is time to declare functions that are related to n-gram models. This is how we generate batches:
generate_batch = lambda do |batch|
label = Torch.tensor(batch.map { |entry| entry[0] })
text = batch.map { |entry| entry[1] }
offsets = [0] + text.map { |entry| entry.size }
offsets = Torch.tensor(offsets[0..-2]).cumsum(0, dtype: :int)
text = Torch.cat(text)
[text, offsets, label]
endThis is how we train each epoch:
train_func = lambda do |sub_train_, epoch|
train_loss = 0
train_acc = 0
data = Torch::Utils::Data::DataLoader.new(sub_train_, batch_size: batch_size, shuffle: true, collate_fn: generate_batch)
data.each_with_index do |(text, offsets, cls), i|
optimizer.zero_grad
text, offsets, cls = text.to(device), offsets.to(device), cls.to(device)
output = model.call(text, offsets)
loss = criterion.call(output, cls)
train_loss += loss.item
loss.backward
optimizer.step
train_acc += output.argmax(1).eq(cls).sum.item
end
if epoch > 0
adjust_lr epoch
end
[train_loss / sub_train_.length, train_acc / sub_train_.length.to_f]
endThis is how we test each epoch:
test = lambda do |data_|
loss = 0
acc = 0
data = Torch::Utils::Data::DataLoader.new(data_, batch_size: batch_size, collate_fn: generate_batch)
data.each do |text, offsets, cls|
text, offsets, cls = text.to(device), offsets.to(device), cls.to(device)
Torch.no_grad do
output = model.call(text, offsets)
loss = criterion.call(output, cls)
loss += loss.item
acc += output.argmax(1).eq(cls).sum.item
end
end
[loss / data_.length, acc / data_.length.to_f]
endI took 90% of train dataset to create a validation split with the remaining:
train_len = (train_dataset.length * 0.9).to_i
sub_train_, sub_valid_ = Torch::Utils::Data.random_split(train_dataset, [train_len, train_dataset.length - train_len])Here's the actual iteration process using all of it:
n_epochs.times do |epoch|
start_time = Time.now
train_loss, train_acc = train_func.call(sub_train_, epoch)
valid_loss, valid_acc = test.call(sub_valid_)
@all_losses.append(train_loss)
secs = Time.now - start_time
mins = secs / 60
secs = secs % 60
puts "Epoch: %d | time in %d minutes, %d seconds" % [epoch + 1, mins, secs]
puts "\tLoss: %.4f (train)\t|\tAcc: %.1f%% (train)" % [train_loss, train_acc * 100]
puts "\tLoss: %.4f (valid)\t|\tAcc: %.1f%% (valid)" % [valid_loss, valid_acc * 100]
end
puts "Checking the results of test dataset..."
test_loss, test_acc = test.call(test_dataset)
puts "\tLoss: %.4f (test)\t|\tAcc: %.1f%% (test)" % [test_loss, test_acc * 100]Let's put some tricky values from test dataset to check if they are working:
model = model.to("cpu")
ex_text_str = "Chipotle Mexican Grill"
puts "#{ex_text_str} is #{local_pack_label[predict(ex_text_str, model, vocab, 2)-1]}"
ex_text_str = "3.9"
puts "#{ex_text_str} is #{local_pack_label[predict(ex_text_str, model, vocab, 2)-1]}"
ex_text_str = "181"
puts "#{ex_text_str} is #{local_pack_label[predict(ex_text_str, model, vocab, 2)-1]}"
ex_text_str = "Coffee shop"
puts "#{ex_text_str} is #{local_pack_label[predict(ex_text_str, model, vocab, 2)-1]}"
ex_text_str = "+1 949-581-XXXX" #Commented for privacy
puts "#{ex_text_str} is #{local_pack_label[predict(ex_text_str, model, vocab, 2)-1]}"
ex_text_str = "323X N Rock R" #Commented for privacy
puts "#{ex_text_str} is #{local_pack_label[predict(ex_text_str, model, vocab, 2)-1]}"
ex_text_str = "Takeout: 8AM–2PM"
puts "#{ex_text_str} is #{local_pack_label[predict(ex_text_str, model, vocab, 2)-1]}"
ex_text_str = "$$"
puts "#{ex_text_str} is #{local_pack_label[predict(ex_text_str, model, vocab, 2)-1]}"
ex_text_str = "Desserts & savory bites offered in a Victorian home with romantic patio doubling as a hookah garden."
puts "#{ex_text_str} is #{local_pack_label[predict(ex_text_str, model, vocab, 2)-1]}"Finally, let's plot the loss and save the model:
#Plotting Loss
plot_line_loss = Gruff::Line.new
plot_line_loss.title = "Loss"
plot_line_loss.data :Loss, @all_losses
plot_line_loss.write("ml/google/local_pack/predict_value/trained_models/value_predictor_loss.png")
@model = model
save_modelResults
Here's the output of the training:
Epoch: 20 | time in 0 minutes, 0 seconds
Loss: 0.0000 (train) | Acc: 99.9% (train)
Loss: 0.0003 (valid) | Acc: 96.4% (valid)
Checking the results of test dataset...
Loss: 0.0001 (test) | Acc: 99.5% (test)Although in testing dataset, it has a 99.5% success rate (Accuracy), and in training_dataset, 99.5%, I think it'd be wise to call the ratio of validation 96.4% to be the actual success rate to be in the safe zone.
Here are the tricky values to be classified (not all of them):
Chipotle Mexican Grill is title
3.9 is rating
181 is reviews
Coffee shop is type
+1 949-581-XXXX is phone
323X N Rock R is address
Takeout: 8AM–2PM is hours
$$ is price
Desserts & savory bites offered in a Victorian home with romantic patio doubling as a hookah garden. is descriptionAs you can see, I have provided an address with numbers in it, a general type of place that might've been mistaken for a title, hours with a definition in front, etc. But the model is successful in classifying these words and much more.
Here's the loss graphic of the training:
Conclusion
In the making of this blog post, we have used 10625 unique testing items and 9892 training items. This model will be further enhanced with bigger and more diverse datasets. But the results here are indicative of a proof of concept for Classifying use cases of Machine Learning in Web scraping.
Next week, we'll talk about how to improve the dataset, how to implement it in our current stack, and further usecases for Machine Learning. I would like to thank the brilliant people of SerpApi for all their support and the reader for their attention.
Acknowledgements:
- Gems Used:
torch.rb
torchtext-ruby
gruff - C++ Libraries Used:
LibTorch 1.10.2, Linux, CUDA 10.2, cxx11 ABI - Materials Repurposed From:
Documentation
Repository Example