 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

Google processes approximately 99,000 search queries per second, which is about 8.5 billion searches in a day. With that amount of search volume, Google must provide rich and diverse data to serve its users well. Scraping Google search results is one of the best ways to gather intelligence for various use cases including SEO, Local SEO, AI model training, news monitoring, automation, background check, etc.
However, there are some difficulties in scraping Google search results accurately and at scale. In this tutorial, we will talk about those difficulties and how to solve them. We will also share the most convenient way to scrape Google search results.
What is SERP (Search Engine Result Page)?
A search engine result page or SERP, is the page you see after entering a query into Google, Bing, Yahoo, or any other search engine. The primitive search engine results page usually includes paid search results and organic results - the legendary 10 blue links. Today, the content is a lot richer and it is for a better user experience. A typical search on Google consists of organic results, knowledge graph, related questions, related searches, etc, the general term to describe them is SERP features. Our playground is a convenient place for you to inspect the results page and its data, feel free to check it out.
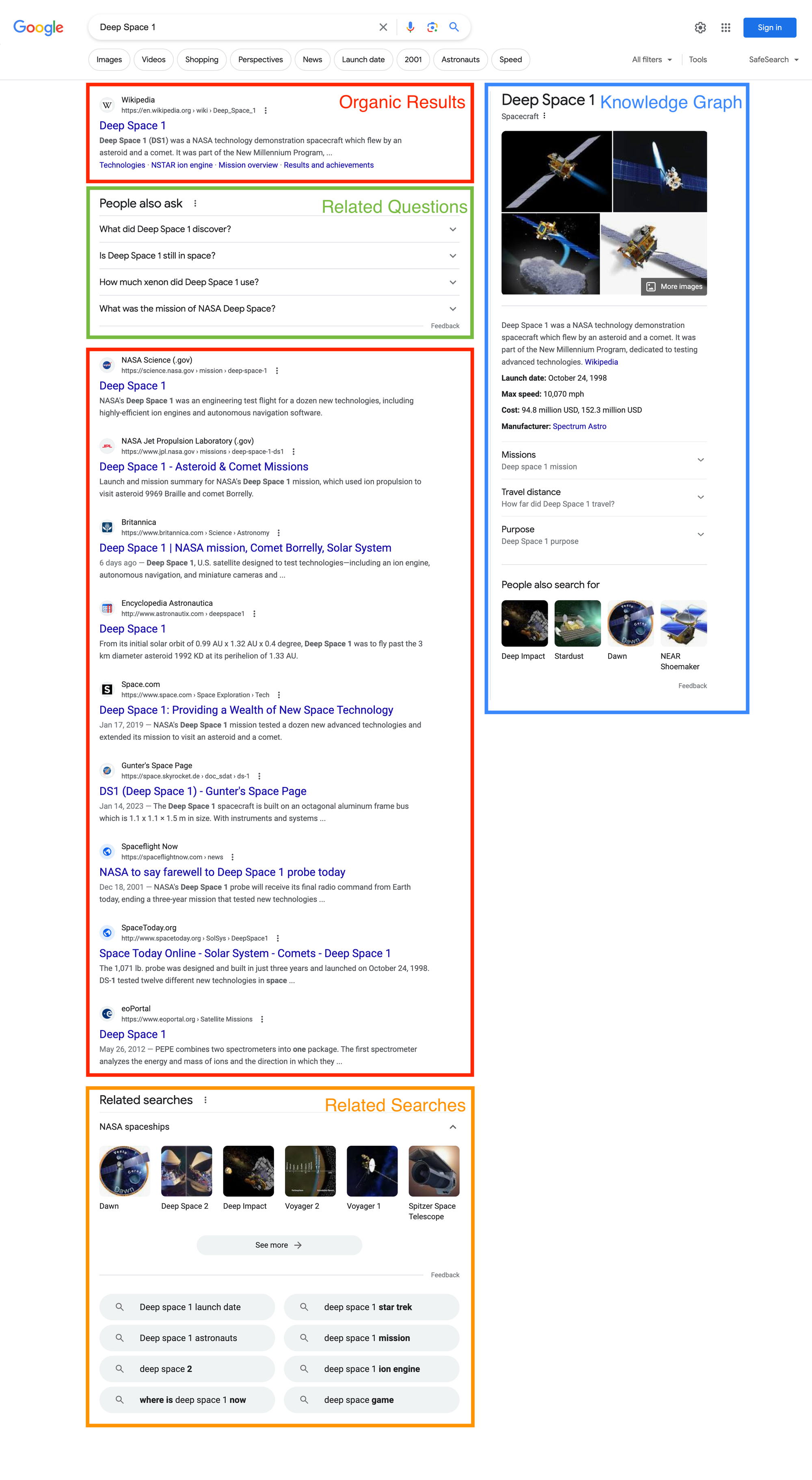
Another example of a cooking-related search includes SERP features like videos, recipes, and other familiar results. Feel free to check out the playground.
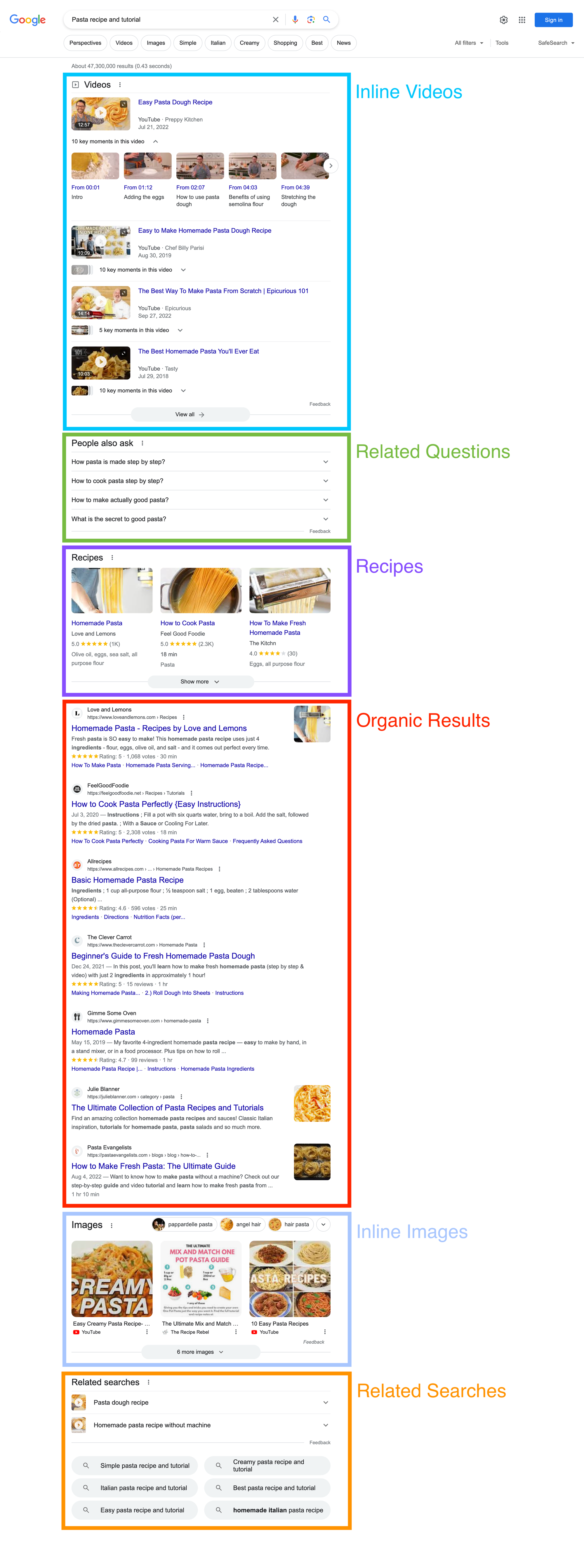
There are a lot more SERP features provided by Google, a Google search shows a list of SERP features. You can also check out our documentation where we document everything we can parse from Google.
Is it legal to scrape Google?
Some websites allow scraping and some others prohibit it. However, scraping publicly accessible data is legal in general, and this includes data from Google.
In SerpApi, we provide "US Legal Shield":
SerpApi will assume liability of scraping and parsing search engine results for both domestic and foreign companies (— “Legal US Shield” —) unless your usage is otherwise illegal.
You can read more about our Terms of Service and what is in included in the Legal US Shield here. Bonus: learn more about how we safeguard web scraping at SerpApi.
Methods to scrape Google
One of the ways to scrape Google results is by building your solution with libraries like Jsoup in Java. This code below scrapes the title of Organic Results. It first downloads the HTML by calling Jsoup.connect and the return document allows us to query the DOM as the Javascript in the Browser.
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
class Main {
public static void main(String[] args) {
String url = "https://google.com/search?q=coffee";
try {
Document document = Jsoup.connect(url).get();
// Extract nodes
Elements nodes = document.select(".g:has(.byrV5b)");
for (Element node : nodes) {
Element h3Element = node.selectFirst("h3");
if (h3Element != null) {
System.out.println(h3Element.text());
// Output:
// Coffee
// What is Coffee?
// Peet's Coffee: The Original Craft Coffee
// Starbucks Coffee Company
// Coffee | Origin, Types, Uses, History, & Facts
// Counter Culture Coffee
// The Coffee Bean & Tea Leaf | CBTL
// Coffee bean
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}Scrape organic results' title
However, when you scale this solution, you might face difficulties like IP bans and CAPTCHA issues. In addition, you have to maintain the complexities and frequent HTML structural changes from Google.
Solutions for preventing getting blocked by Google (ref: https://serpapi.com/blog/how-to-scrape-google-search-results-with-python/)
Use Proxies: Rotate multiple IP addresses to prevent your main IP from being blocked. This makes it harder for Google to pinpoint scraping activity from a single source.
Set Delays: Don't send requests too rapidly. Wait for a few seconds or more between requests to mimic human behavior and avoid triggering rate limits.
Change User Agents: Rotate user agents for every request. This makes it seem like the requests come from different devices and browsers.
Use CAPTCHA Solving Services: Sometimes, if Google detects unusual activity, it will prompt with a CAPTCHA. Services exist that can automatically solve these for you.
A more effective business decision you can make is to utilize APIs from scraping service providers such as SerpApi. Simply by calling an API, you can get all the Google SERP features, which are accurately labeled. Visit the playground to get a sense of the data we will provide for you.
Why use an API?
The benefits of using an API is straightforward
- There is no need to create a parser from scratch and maintain it, considering the complexities and frequent changes by Google.
- Bypass blocks from Google: solve CAPTCHAs or solve IP blocks.
- No need to pay for proxies, and CAPTCHA solvers.
- Don't need to use browser automation.
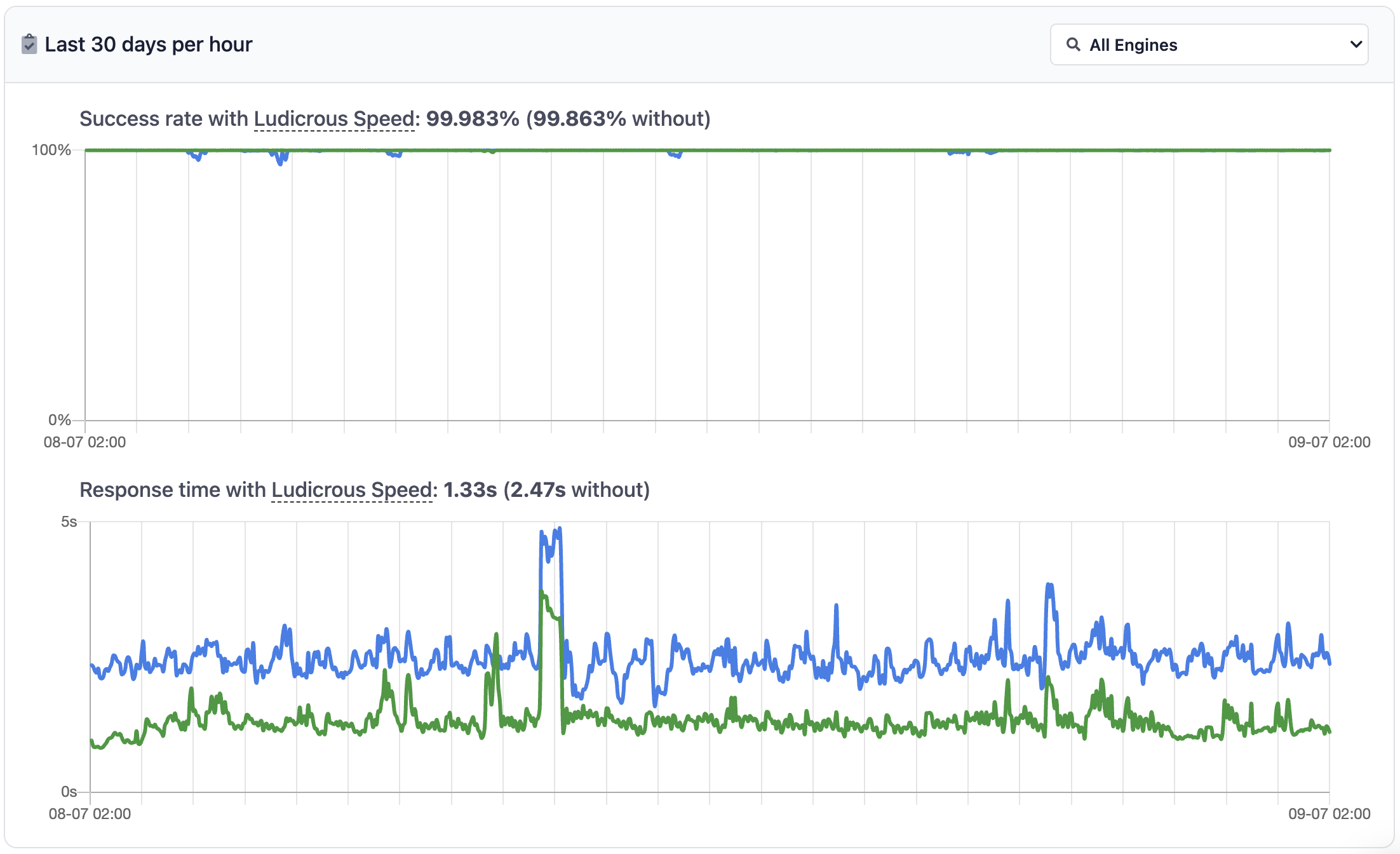
SerpApi takes care of everything mentioned above with fast response times under ~2.47 seconds (~1.33 seconds with Ludicrous speed) per request. The result is well-structured data in JSON with only a single API call.
Response times and success rates are shown under the SerpApi Status page.
Scraping Google using an API in Java
Let's start and scrape data from Google SERP.
Prerequisite
Install library:
Edit your build.gradle file
repositories {
maven { url "https://jitpack.io" }
}
dependencies {
implementation 'com.github.serpapi:google-search-results-java:2.0.3'
}You also need an API key, you can get free 100 searches upon signing up.
The Code
import com.google.gson.Gson;
import com.google.gson.JsonArray;
import com.google.gson.JsonObject;
import serpapi.SerpApiSearchException;
import serpapi.GoogleSearch;
import java.util.Map;
import java.util.HashMap;
class Main {
public static void main(String[] args) {
Map<String, String> parameter = new HashMap<>();
parameter.put("q", "Coffee");
parameter.put("location", "Austin, Texas, United States");
parameter.put("hl", "en");
parameter.put("gl", "us");
parameter.put("api_key", System.getenv("API_KEY"));
try {
GoogleSearch search = new GoogleSearch(parameter);
JsonObject data = search.getJson();
JsonArray results = data.get("organic_results").getAsJsonArray();
JsonObject first_result = results.get(0).getAsJsonObject();
System.out.println(first_result.get("title").getAsString() + "\n" + first_result.get("snippet").getAsString());
} catch (SerpApiSearchException ex) {
System.out.println("oops something went wrong when search " + parameter.get("q") + " on google");
ex.printStackTrace();
}
}
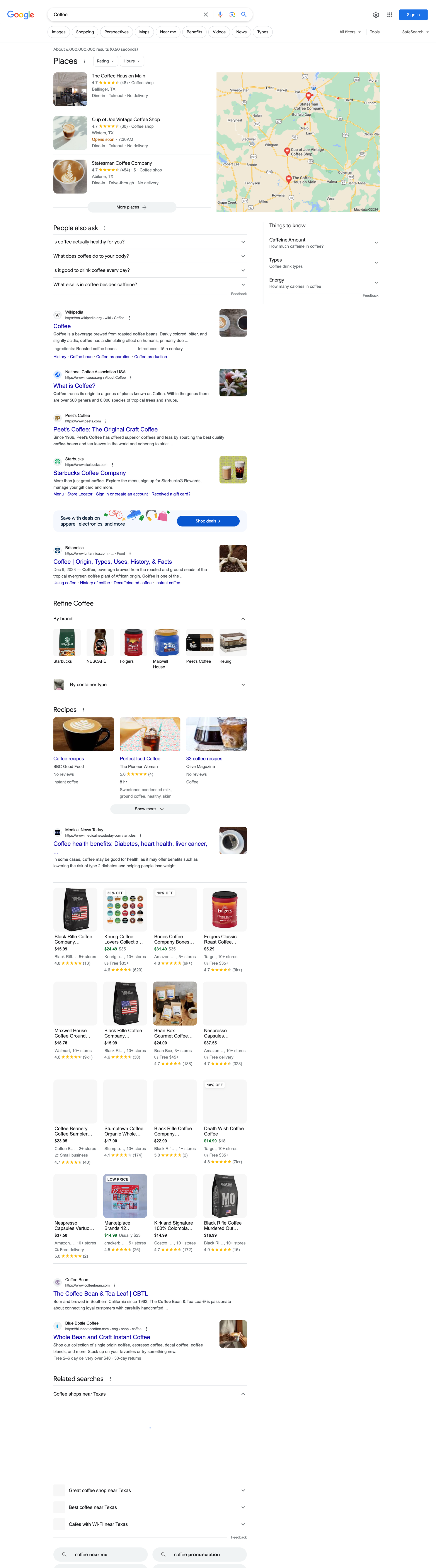
}With only a few lines of code, you can get the structured results for the page below. We are searching Coffee on Google, you can replace the q parameter with anything that you would normally do in Google. location parameter is optional but could be important to your query, especially if you want accurate Local Results (Places). Check out the full parameters in our documentation.
The same code can work for other search engines like Google Maps, Bing, Yahoo, Yandex or platforms like the Apple App Store, Youtube, and more.
{
"search_metadata": {
...
"status": "Success",
"total_time_taken": 1.08
},
"search_parameters": {
"engine": "google",
"q": "Coffee",
"location_requested": "Austin, Texas",
"location_used": "Austin,TX,Texas,United States",
"google_domain": "google.com",
"hl": "en",
"gl": "us",
"device": "desktop"
},
"search_information": {
"query_displayed": "Coffee",
"total_results": 6000000000,
"time_taken_displayed": 0.5,
"menu_items": [
{
"position": 1,
"title": "Images",
"link": "<URL>",
"serpapi_link": "<URL>"
},
{
"position": 2,
"title": "Shopping",
"link": "<URL>",
"serpapi_link": "<URL>"
},
{
"position": 3,
"title": "Perspectives",
"link": "<URL>",
"serpapi_link": "<URL>"
},
...
],
"organic_results_state": "Results for exact spelling"
},
"recipes_results": [
{
"title": "Coffee recipes",
"link": "https://www.bbcgoodfood.com/recipes/collection/coffee-recipes",
"source": "BBC Good Food",
"ingredients": [
"Instant coffee"
],
"thumbnail": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSstZjPWNJe6Cl16FCp4xURsTjFeH_G5U_KAG01zCdDH3ebjuqNySel0eVq6w&s"
},
{
"title": "Perfect Iced Coffee",
"link": "https://www.thepioneerwoman.com/food-cooking/recipes/a11061/perfect-iced-coffee/",
"source": "The Pioneer Woman",
"rating": 5.0,
"reviews": 4,
"total_time": "8 hr",
"ingredients": [
"Sweetened condensed milk",
"ground coffee",
"healthy",
"skim milk"
],
"thumbnail": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQBjI6POpVwcx5v-0wXh8uYQ3At-768YF6hRTHLBhteTA&s"
},
{
"title": "33 coffee recipes",
"link": "https://www.olivemagazine.com/recipes/collection/best-ever-coffee-recipes/",
"source": "Olive Magazine",
"ingredients": [
"Coffee"
],
"thumbnail": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTtyp7IdAVL4DqSkDPoXenOxF55OAU-zLAiIOYas50OmoaisZH0jOusR6vv4Q&s"
}
],
"local_map": {
"link": "<URL>",
"image": "<URL>",
"gps_coordinates": {
"latitude": 32.062857,
"longitude": -99.863541,
"altitude": 37383
}
},
"local_results": {
"places": [
{
"position": 1,
"rating": 4.7,
"reviews_original": "(48)",
"reviews": 48,
"place_id": "7920778704432590090",
"place_id_search": "<URL>",
"lsig": "AB86z5UZD5xj713sXU0khIy4IiH8",
"thumbnail": "<URL>",
"service_options": {
"dine_in": true,
"takeout": true,
"no_delivery": true
},
"title": "The Coffee Haus on Main",
"type": "Coffee shop",
"address": "Ballinger, TX"
},
{
"position": 2,
"rating": 4.7,
"reviews_original": "(30)",
"reviews": 30,
"place_id": "6645020494937232090",
"place_id_search": "<URL>",
"thumbnail": "<URL>",
"service_options": {
"dine_in": true,
"takeout": true,
"no_delivery": true
},
"title": "Cup of Joe Vintage Coffee Shop",
"type": "Coffee shop",
"address": "Winters, TX",
"hours": "Opens soon ⋅ 7:30 AM"
},
{
"position": 3,
"rating": 4.7,
"reviews_original": "(454)",
"reviews": 454,
"price": "$",
"place_id": "25858402215473201",
"place_id_search": "<URL>",
"thumbnail": "<URL>",
"service_options": {
"dine_in": true,
"drive_through": true,
"no_delivery": true
},
"title": "Statesman Coffee Company",
"type": "Coffee shop",
"address": "Abilene, TX"
}
],
"more_locations_link": "<URL>"
},
"immersive_products": [
{
"thumbnail": "<URL>",
"source": "Black Rifle Coffee Company, 5+ stores",
"title": "Black Rifle Coffee Company Freedom Fuel",
"rating": 4.8,
"reviews": 13,
"price": "$15.99",
"extracted_price": 15.99,
"immersive_product_page_token": "...",
"serpapi_link": "<URL>"
},
{
"thumbnail": "<URL>",
"source": "Keurig.com, 10+ stores",
"title": "Keurig Coffee Lovers Collection Variety Pack Single Serve Coffee K Cup Pods Sampler",
"snippets": [
{
"text": "Tastes good (53 user reviews)"
}
],
"rating": 4.6,
"reviews": 620,
"price": "$24.49",
"extracted_price": 24.49,
"original_price": "$35",
"extracted_original_price": 35,
"extensions": [
"30% OFF"
],
"immersive_product_page_token": "...",
"serpapi_link": "<URL>"
},
...
],
"related_questions": [
{
"question": "Is coffee actually healthy for you?",
"snippet": "Caffeine is the first thing that comes to mind when you think about coffee. But coffee also contains antioxidants and other active substances that may reduce internal inflammation and protect against disease, say nutrition experts from Johns Hopkins University School of Medicine.",
"title": "9 Reasons Why (the Right Amount of) Coffee Is Good for You",
"link": "<URL>",
"displayed_link": "https://www.hopkinsmedicine.org › health › 9-reasons-w...",
"source_logo": "<URL>",
"next_page_token": "...",
"serpapi_link": "<URL>"
},
{
"question": "What does coffee do to your body?",
"snippet": "What does caffeine do to your body? Caffeine is well absorbed by the body, and the short-term effects are usually experienced between 5 and 30 minutes after having it. These effects can include increased breathing and heart rate, and increased mental alertness and physical energy.",
"title": "Caffeine - Better Health Channel",
"link": "<URL>",
"displayed_link": "https://www.betterhealth.vic.gov.au › healthyliving › caf...",
"source_logo": "<URL>",
"next_page_token": "...",
"serpapi_link": "<URL>"
},
{
"question": "Is it good to drink coffee every day?",
"snippet": "Hu said that moderate coffee intake—about 2–5 cups a day—is linked to a lower likelihood of type 2 diabetes, heart disease, liver and endometrial cancers, Parkinson's disease, and depression. It's even possible that people who drink coffee can reduce their risk of early death.",
"title": "Is coffee good or bad for your health? | News",
"link": "<URL>",
"displayed_link": "https://www.hsph.harvard.edu › news › hsph-in-the-news",
"source_logo": "<URL>",
"next_page_token": "...",
"serpapi_link": "<URL>"
},
...
],
"organic_results": [
{
"position": 1,
"title": "Coffee",
"link": "https://en.wikipedia.org/wiki/Coffee",
"redirect_link": "<URL>",
"displayed_link": "https://en.wikipedia.org › wiki › Coffee",
"thumbnail": "<URL>",
"favicon": "<URL>",
"snippet": "Coffee is a beverage brewed from roasted coffee beans. Darkly colored, bitter, and slightly acidic, coffee has a stimulating effect on humans, primarily due ...",
"snippet_highlighted_words": [
"Coffee",
"coffee",
"coffee"
],
"sitelinks": {
"inline": [
{
"title": "History",
"link": "https://en.wikipedia.org/wiki/History_of_coffee"
},
{
"title": "Coffee bean",
"link": "https://en.wikipedia.org/wiki/Coffee_bean"
},
{
"title": "Coffee preparation",
"link": "https://en.wikipedia.org/wiki/Coffee_preparation"
},
{
"title": "Coffee production",
"link": "https://en.wikipedia.org/wiki/Coffee_production"
}
]
},
"rich_snippet": {
"bottom": {
"extensions": [
"Ingredients: Roasted coffee beans",
"Introduced: 15th century"
],
"detected_extensions": {
"introduced_th_century": 15
}
}
},
"source": "Wikipedia"
},
{
"position": 2,
"title": "What is Coffee?",
"link": "https://www.ncausa.org/About-Coffee/What-is-Coffee",
"redirect_link": "<URL>",
"displayed_link": "https://www.ncausa.org › About Coffee",
"thumbnail": "<URL>",
"snippet": "Coffee traces its origin to a genus of plants known as Coffea. Within the genus there are over 500 genera and 6,000 species of tropical trees and shrubs.",
"snippet_highlighted_words": [
"Coffee"
],
"source": "National Coffee Association USA"
},
{
"position": 3,
"title": "Peet's Coffee: The Original Craft Coffee",
"link": "https://www.peets.com/",
"redirect_link": "<URL>",
"displayed_link": "https://www.peets.com",
"favicon": "<URL>",
"snippet": "Since 1966, Peet's Coffee has offered superior coffees and teas by sourcing the best quality coffee beans and tea leaves in the world and adhering to strict ...",
"snippet_highlighted_words": [
"Coffee",
"coffees",
"coffee"
],
"source": "Peet's Coffee"
},
...
],
"related_searches": [
{
"block_position": 1,
"query": "Coffee shops near Texas",
"image": "<URL>"
},
{
"block_position": 1,
"query": "Great coffee shop near Texas",
"image": "<URL>"
},
{
"block_position": 1,
"query": "Best coffee near Texas",
"image": "<URL>"
},
...
],
"refine_this_search": [
{
"query": "Starbucks",
"link": "<URL>",
"serpapi_link": "<URL>",
"thumbnail": "<URL>"
},
{
"query": "NESCAFÉ",
"link": "<URL>",
"serpapi_link": "<URL>",
"thumbnail": "<URL>"
},
{
"query": "Folgers",
"link": "<URL>",
"serpapi_link": "<URL>",
"thumbnail": "<URL>"
},
],
"pagination": {
"current": 1,
"next": "https://www.google.com/search?q=Coffee&oq=Coffee&hl=en&gl=us&start=10&sourceid=chrome&ie=UTF-8",
"other_pages": {
"2": "https://www.google.com/search?q=Coffee&oq=Coffee&hl=en&gl=us&start=10&sourceid=chrome&ie=UTF-8",
...
}
},
"serpapi_pagination": {
"current": 1,
"next_link": "https://serpapi.com/search.json?device=desktop&engine=google&gl=us&google_domain=google.com&hl=en&location=Austin%2C+Texas&q=Coffee&start=10",
"next": "https://serpapi.com/search.json?device=desktop&engine=google&gl=us&google_domain=google.com&hl=en&location=Austin%2C+Texas&q=Coffee&start=10",
"other_pages": {
"2": "https://serpapi.com/search.json?device=desktop&engine=google&gl=us&google_domain=google.com&hl=en&location=Austin%2C+Texas&q=Coffee&start=10",
...
}
}
}You can check out our other blog post for a more in-depth breakdown of using our API with pagination.
Documentation
Conclusion
We hope this article is helpful to you and provides you with adequate information about scraping Google search results. At SerpApi, we always strive to keep our APIs up to date with Google results and other platforms and make our service fast.
If you are interested, please feel free to reach out to me.
Add a Feature Request💫 or a Bug🐞
