 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++
Let’s go ahead and break down the search, results, and the different parameters that can be found on the demonstration playground.
As always when introducing a new API I find the Playground area to be the most visually informative tool, next to the documentation that can be found here: https://serpapi.com/naver-search-api
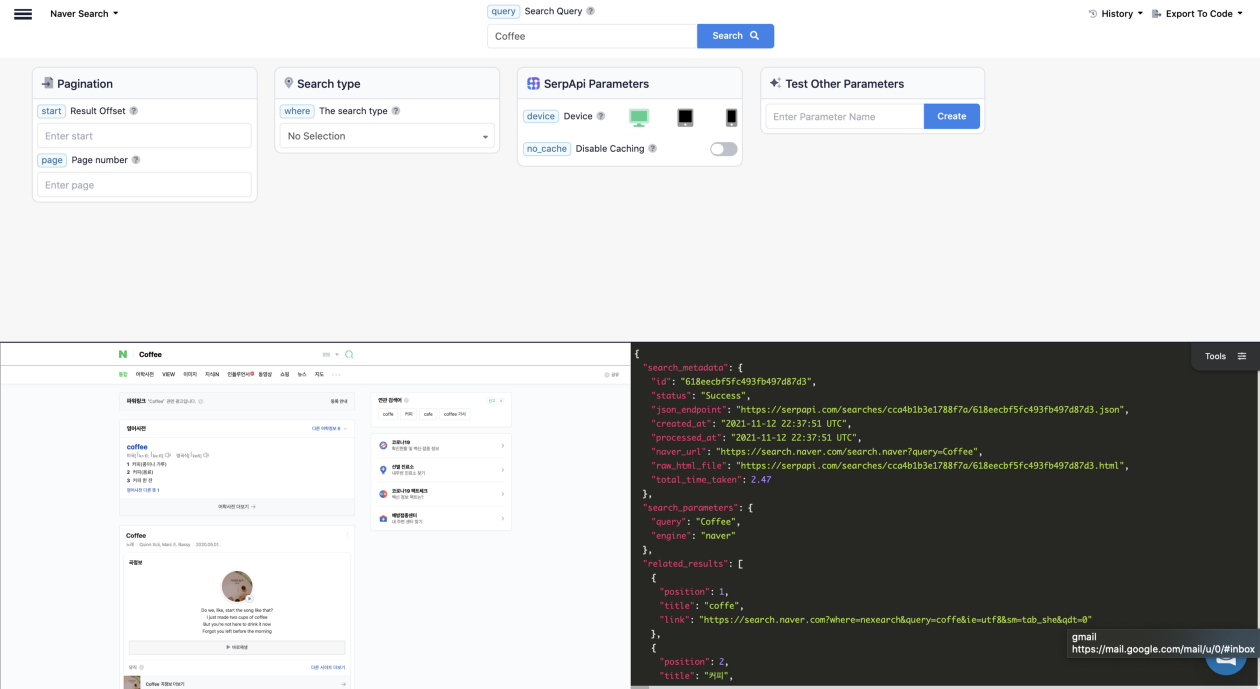
https://serpapi.com/playground?engine=naver&query=Coffee&highlight=organic_results
Instead of Google’s organic_results key value pair, Naver’s is set to web_results.
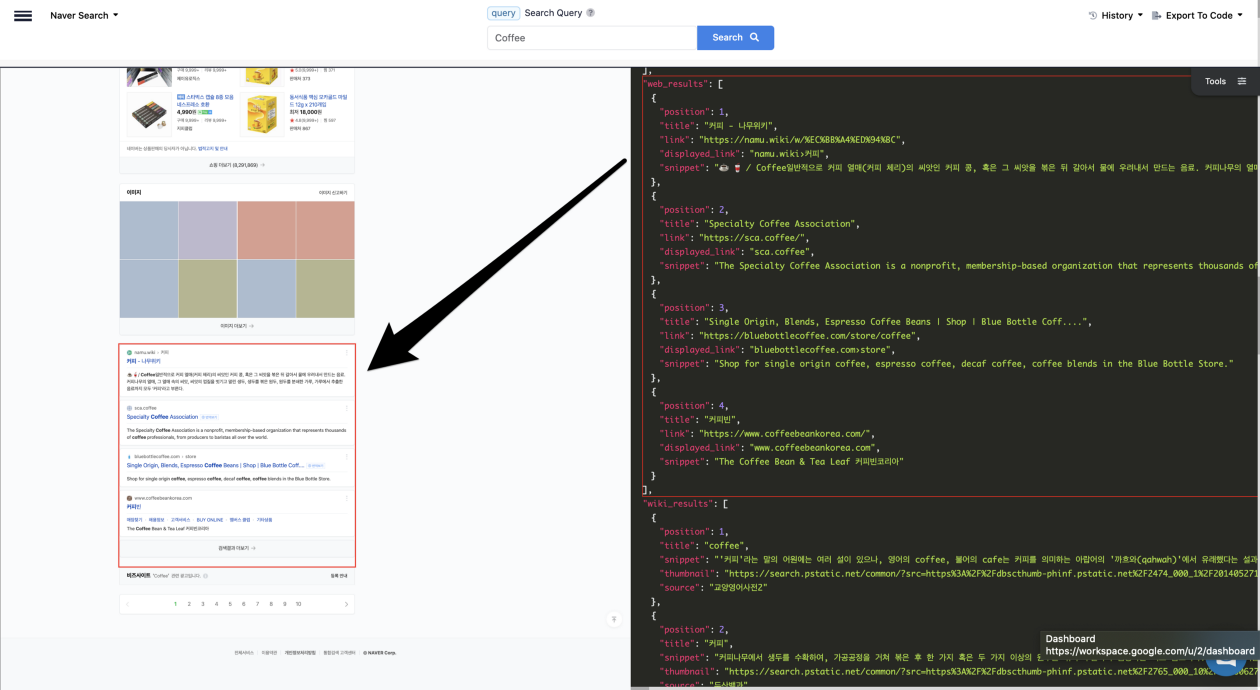
The best way to see what kind of data sets are there would be to check the raw JSON of the search. You can go about getting this data by taking the specific id from the search and putting it into the url like this:
www.serpapi.com/searches/<INSERT_ID_HERE>.json
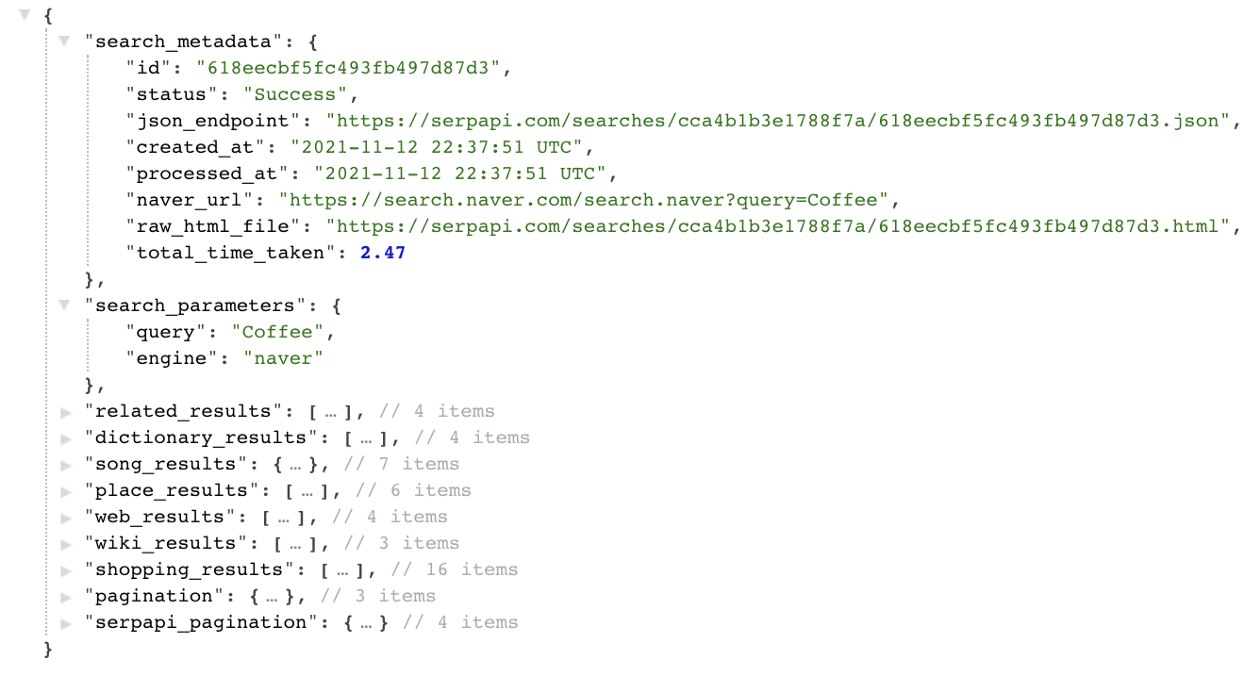
Or if you have a regular library implementation it may be a bit easier to see and navigate.
The HTML element make up on Naver is a bit different than Google, Baidu, Bing and other’s but it’s basically the same search engine feel.
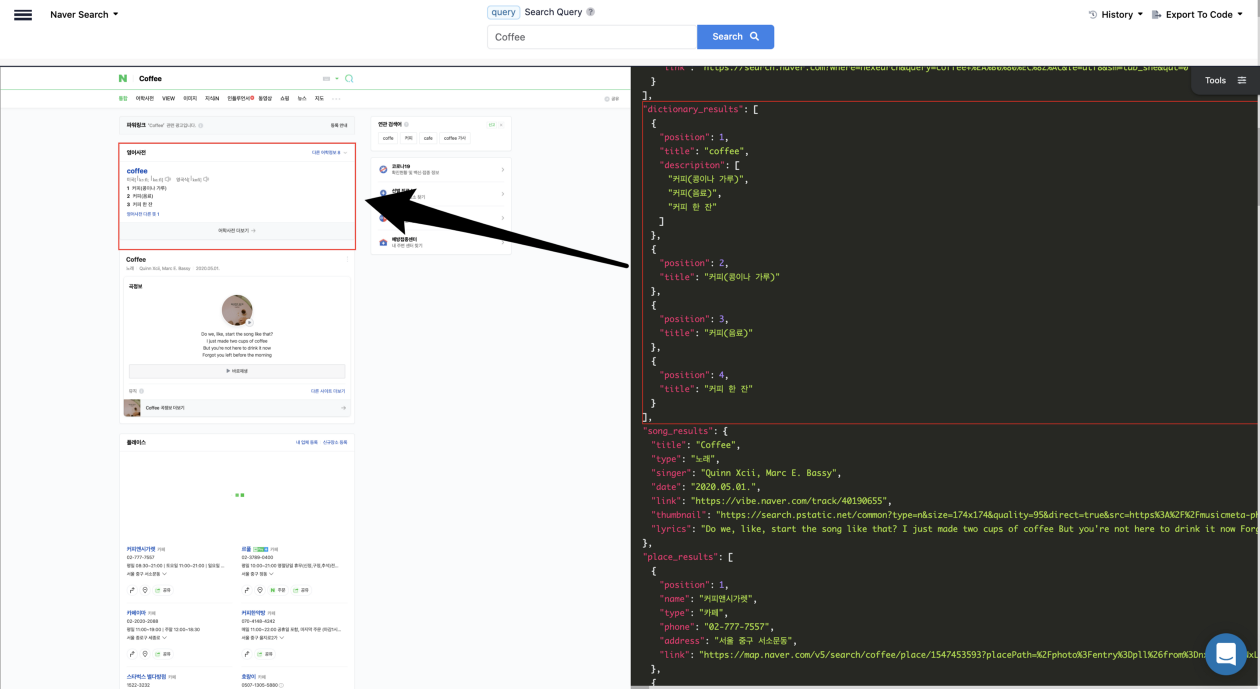
It is important to mention, if you are navigating from any of the Google Search engines be sure to check the data fields, besides the search_metadatasearch_parameterspagination and serpapi_pagination, the data can be quite different.
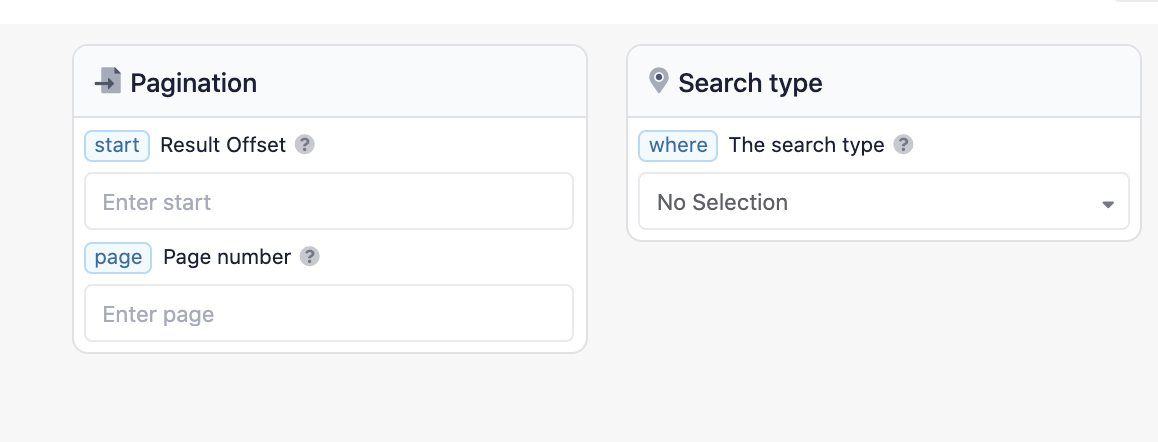
Since Naver is a new API for SerpApi to scrape, there are not too many extra parameters that have been added to this engine. Our goal is to scrape as many engines and package all the data that can be found on the HTML’s of these pages.
If you happen to find any parameter that work with Naver please reach out to justin@serpapi.com or contact@serpapi.com so we can add more specific searches!
You can sign-up for SerpApi here: https://serpapi.com/
You can find the API documentation here: https://serpapi.com/search-api/