 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

Intro
With our new Google Patents API, you can scrape patents and scholar results with all the details Google provides on its Patent page.
Google shows patents from over 100 most prominent patent offices worldwide, and now you can get them in organized JSON format with SerpApi. On top of regular patent searches, you can use all parameters to utilize the advanced search options from Google Patents.
In this quick guide, I'll show you how to scrape Google Patents results using Python.
What we'll scrape
We'll focus on scraping organic_results from the JSON response and extracting key elements for each result present in SERP.
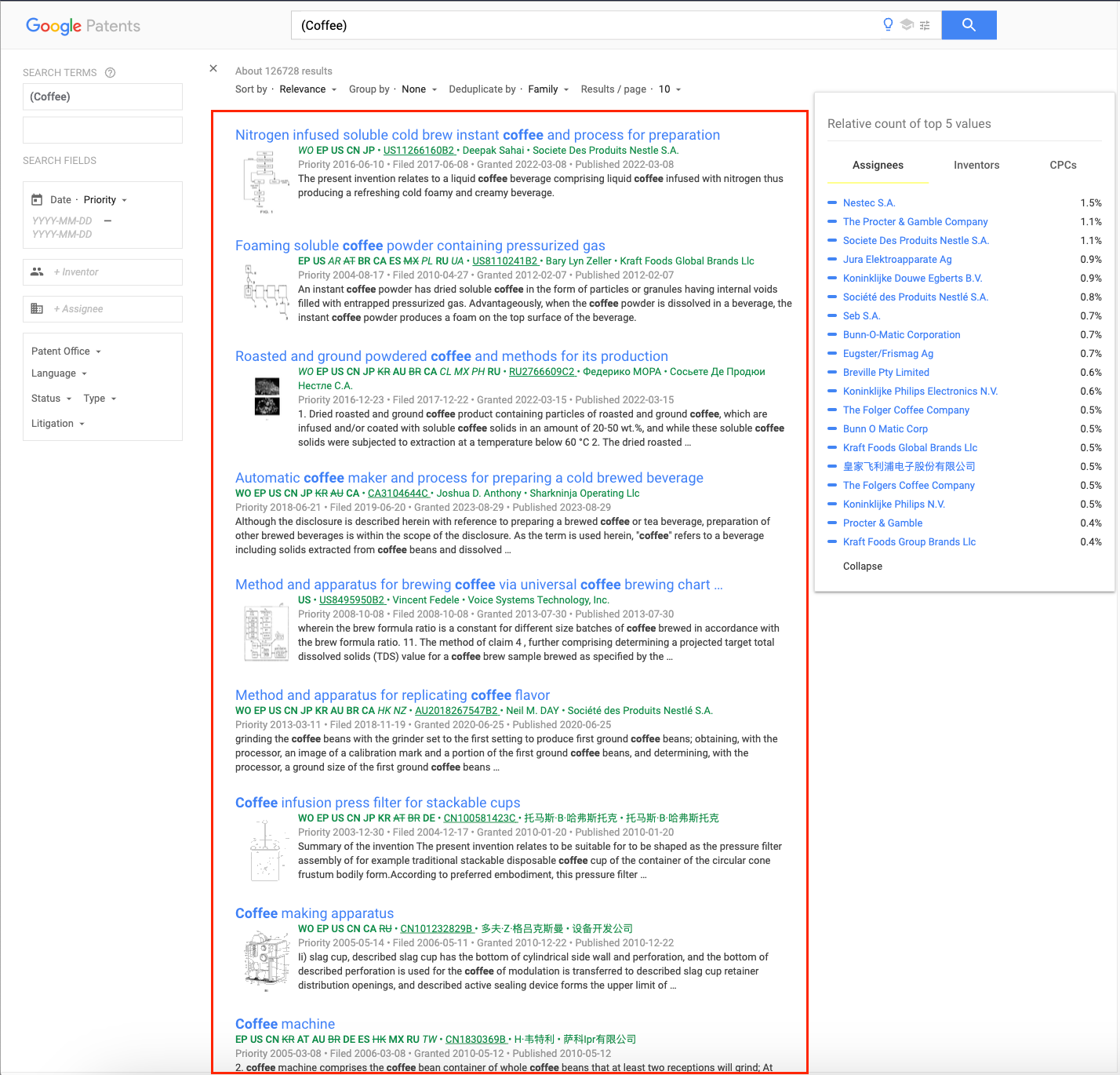
Google Patents API parameters
There are a lot of different parameters you can use to manipulate your results in the Google Patents API. You can check them all on our documentation page, but we'll also go through some of them here:
q- required parameter defining keyword or keywords that you'd like to search for with Google Patents APIpage- parameter used to paginate through results. The first page's value is1by default, and you can increment it by one to get the next page with each subsequent API call.num- parameter defines the number of results in a single API call. The value can be increased up to 100.
These parameters are essential for obtaining all the results Google provides. Unfortunately, Google doesn't allow getting all results in a single API call, but using page and num parameter within your implementation ensures that all results will be scraped.
You can manipulate your queries using different API-specific parameters, among which are:
- Advanced Google Patents Parameters - including
sort,clustered,dups,patentsandscholarparameters. - Date Range - including
beforeandafterparameters. - Participants - including
investorandassigneeparameters. - Advanced Filters - including
country,language,status,typeandlitigationparameters.
To learn more about what each parameter does to your search results, I encourage you once again to visit our documentation page, where you'll find descriptions for each one of them.
Using Python with Google Patents API
We'll be using a simple code to iterate through all the results for a given keyword.
# Import required libraries
import serpapi
from dotenv import load_dotenv
import pandas as pd
import os
# Load environment variables from the .env file
load_dotenv()
# Your API Key can be found at https://serpapi.com/manage-api-key
client = serpapi.Client(api_key=os.getenv("SERPAPI_KEY"))
all_extracted_data = [] # Master data list used to create .csv file later on
page_number = 1 # Assign initial page_number value as 1
while True:
results = client.search({
"engine": "google_patents", # Define engine
"q": "(Coffee)", # Your search query
"page": page_number # Page number, defined before
})
organic_results = results["organic_results"]
# Extract data from each result
extracted_data = []
for result in organic_results:
data = {
"title": result.get("title"),
"snippet": result.get("snippet"),
"filing_date": result.get("filing_date"),
"grant_date": result.get("grant_date"),
"inventor": result.get("inventor"),
"assignee": result.get("assignee"),
"patent_id": result.get("patent_id")
}
extracted_data.append(data)
# Add the extracted data to the master data list
all_extracted_data.extend(extracted_data)
# Increment page number value by 1 or end the loop
if "next" in results["serpapi_pagination"]:
page_number +=1
else:
break
csv_file = "extracted_data.csv" # Assign .csv file name to a variable
csv_columns = [ # Define list of columns for your .csv file
"title",
"snippet",
"filing_date",
"grant_date",
"inventor",
"assignee",
"patent_id"
]
# Save all extracted data to a CSV file
pd.DataFrame(data=all_extracted_data).to_csv(
csv_file,
columns=csv_columns,
encoding="utf-8",
index=False
)Getting started
First, we need to install all the libraries required for our code. We'll be using built-in os library, as well as serpapi, pandas and dotenv. To install them, use the following pip command in your terminal:
pip install serpapi pandas python-dotenvThe next step would be to create the .env file in your environment, and add your API Key there. Using the line below and replacing "YOUR_API_KEY" with your actual API Key will be enough:
SERPAPI_KEY=YOUR_API_KEYCode breakdown
After importing the necessary libraries, we need to assign our API Key to our client. These two lines will do the trick:
load_dotenv()
client = serpapi.Client(api_key=os.getenv("SERPAPI_KEY")) We can now go ahead and assign the variables that we'll be using for data extraction and pagination.
all_extracted_data = []
page_number = 1 The all_extracted_data list will be used to store the information we gather from API calls and the page_number is the initial page we're starting with, and we'll increase the value by one whenever there is more data to be extracted.
Now, within the while loop, we need to define our parameters for API calls.
results = client.search({
"engine": "google_patents",
"q": "(Coffee)",
"page": page_number
})
organic_results = results["organic_results]I went with the default "q": "(Coffee)", in addition to "engine": "google_patents" and "page": page_number, which uses the variable we defined before. Additionally, I've assigned the organic_results variable, which will be our primary source of information.
extracted_data = []
for result in organic_results:
data = {
"title": result.get("title"),
"snippet": result.get("snippet"),
"filing_date": result.get("filing_date"),
"grant_date": result.get("grant_date"),
"inventor": result.get("inventor"),
"assignee": result.get("assignee"),
"patent_id": result.get("patent_id")
}
extracted_data.append(data)
all_extracted_data.extend(extracted_data) The extracted_data list will serve as a temporary container for the data we gather from each organic_result, as presented in the snippet above, within the for loop.
I've decided to go with the title, snippet, filing_date, grant_date, inventor, assignee, and patent_id as my data, but it's totally up to you to decide which information is relevant to you. You just need to adjust the data dictionary accordingly.
After the loop finishes and all the data from the current page is extracted, we extend the all_extracted_data list with the information gathered in the extracted_data.
if "next" in results["serpapi_pagination"]:
page_number +=1
else:
break After the extraction, we look for the next parameter in the serpapi_pagination block. If it's present in the results, it means that there is another page we can extract the data from, so we increase the page_number value by one and continue with another iteration of the while loop. If there is no next page available, we break the loop.
csv_file = "extracted_data.csv"
csv_columns = [
"title",
"snippet",
"filing_date",
"grant_date",
"inventor",
"assignee",
"patent_id"
] The only thing left for us is to save the results in the .csv file. To do that, we can define the file's name and column names, similar to how it's shown in the snippet above.
With these variables and pd.Dataframe, we save the file using .to_csv function from the pandas library we installed before. The data parameter is the information we want to save in the .csv file, which is all_extracted_data in our case. On top of file name and columns, we can also add encoding, and index=False, which will ensure that no row indexing will be present in our file
pd.DataFrame(data=all_extracted_data).to_csv(
csv_file,
columns=csv_columns,
encoding="utf-8",
index=False
)Results
After the code execution, we are left with the .csv file that contains all the data we've gathered from Google Patents API for our keyword:
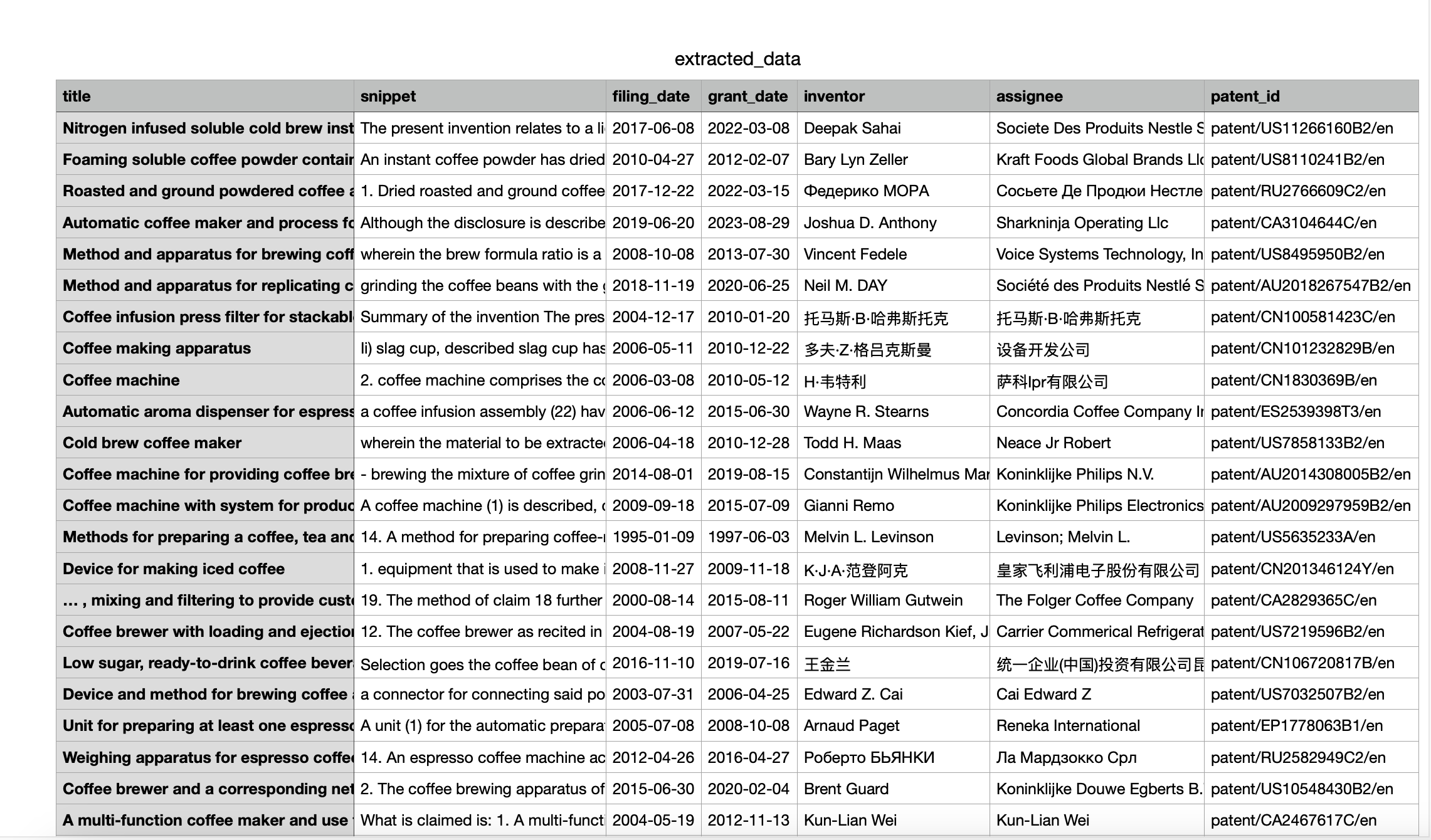
This is the example data for the Coffee keyword, but as I mentioned before, you can freely adjust the search query as well as all the parameters to gather the most relevant information.
Conclusion
The data from Google Patents can be used in many ways, from Intellectual Property Research, Competitive Analysis to Academic Research or Market Analysis and Investment Decisions. All this is now easily achievable with our Google Patents API.
If you have any questions or would like to discuss any issues or matters, feel free to contact our team at contact@serpapi.com. We'll be more than happy to assist you and answer all of your questions!
Use the Playground to test our APIs
Join us on Twitter | YouTube