 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 C++
C++

Update 12 Sep 2024: Added solution in Javascript
We launched the Google Ads Transparency Center a few months ago, and our customers are happy using it. However, there is one imperfection in the API that we would like to address in this blog post.
We have a comprehensive tutorial on using SerpApi in NodeJS. Feel free to check it out if that interests you.
The issue is that the link isn't showing the actual content. Instead, it is a link to a Javascript file that loads the actual content in subsequent requests. It always starts with:
https://displayads-formats.googleusercontent.com/...The Javascript file, when executed, will add an iFrame (embedded HTML) to the webpage. We generally don't support making additional requests and since an iFrame can have any kind of content, it is difficult for us to decide on an optimal solution. This mostly happens when a video format is used, as the content is usually a YouTube video or other 3rd party ads network.
We have developed a script to retrieve the direct link to the content that elaborates on the rest of the blog post. While we may integrate it into our API once it matures, currently, providing direct access to the script benefits our customers as they can customize it to suit their needs.
Solution in Ruby
It currently supports retrieving an image URL, YouTube URL, Seedtag video URL, and falls back to raw HTML if none of the mentioned formats are supported. Feel free to customize the code to suit your needs.
require 'net/http'
require 'uri'
require 'json'
UNESCAPE_CHARS = Hash.new do |hash,char|
if char[0,1] == '\\'
char[1,1]
else
char
end
end
UNESCAPE_CHARS['\0'] = "\0"
UNESCAPE_CHARS['\a'] = "\a"
UNESCAPE_CHARS['\b'] = "\b"
UNESCAPE_CHARS['\t'] = "\t"
UNESCAPE_CHARS['\n'] = "\n"
UNESCAPE_CHARS['\v'] = "\v"
UNESCAPE_CHARS['\f'] = "\f"
UNESCAPE_CHARS['\r'] = "\r"
UNESCAPE_CHARS['\u'] = '\u'
UNESCAPE_CHARS['\x'] = '\x'
JS_UNESCAPES = Hash.new
JS_UNESCAPES['\u005c'] = "\\"
JS_UNESCAPES['\u0027'] = "'"
JS_UNESCAPES['\u0022'] = "\""
JS_UNESCAPES['\u003e'] = ">"
JS_UNESCAPES['\u003c'] = "<"
JS_UNESCAPES['\u0026'] = "&"
JS_UNESCAPES['\u003d'] = "="
JS_UNESCAPES['\u002d'] = "-"
JS_UNESCAPES['\u003b'] = ";"
JS_UNESCAPES['\u0060'] = "`"
ESCAPED_CONTROL_CHARS = ['\u0003', '\u000b', '\u0019', '\u001d', '\u001c']
CONTROL_CHARS = ESCAPED_CONTROL_CHARS.map { |m| JSON.load(%Q("#{m}")) }
def unescape_js(string)
string.gsub!(/\\([0-7]{3})/) { [$1.to_i(8)].pack('U*') }
string.gsub!(/\\x([0-9a-fA-F]{1,2})/) { |m| [$1.to_i(16)].pack('U*') }
if s = string.gsub(/(?<!\\)(\\u[0-9a-fA-F]{4})+/) { |m| JSON.load(%Q("#{m}")) rescue m } and s.valid_encoding?
string = s
else
string = string.gsub(/(\\u[0-9a-fA-F]{4})+/) { |m| JSON.load(%Q("#{m}")) rescue m }
end
string.gsub!(/(?<!\\)(\\(?:#{Regexp.union(JS_UNESCAPES.keys).source}))/i) { |m| JS_UNESCAPES[m[1..-1].downcase] }
string.gsub!(/(?<!\\)(\\(?:#{Regexp.union(ESCAPED_CONTROL_CHARS).source}))/i, "")
string.gsub!(/(#{Regexp.union(CONTROL_CHARS).source})/, "")
string.gsub!(/\\./) { |m| UNESCAPE_CHARS[m] }
string
end
def priortize_video_url(url)
uri = URI(url)
params = URI.decode_www_form(uri.query).to_h
params.delete("uiFeatures")
uri.query = URI.encode_www_form(params)
uri
end
def extract_media(url)
new_url = priortize_video_url(url)
response = Net::HTTP.get_response(new_url)
puts "Response - #{response.code}"
content = response.body.force_encoding('UTF-8')
if (matching_image = content[/previewservice.insertPreviewImageContent\('fletch.+', 'fletch.+', '(.+?)'/, 1])
return {type: "url", value: matching_image}
elsif (matching_html = content[/previewservice.insertPreviewHtmlContent\('fletch.+', 'fletch.+', '(.+?)'/, 1])
html = unescape_js matching_html
if html.include? "lima-exp-data"
video_id = html[/yt_video_id': '(.+?)'/, 1]
return {type: "url", value: "https://youtube.com/watch?v=#{video_id}"}
elsif html.include?("youtube") && html.include?("var adData")
video_id = html[/(?:video_id|video_videoId)': '(.+?)'/, 1]
return {type: "url", value: "https://youtube.com/watch?v=#{video_id}"}
elsif html.include?("googlevideo.com")
video_url = html[/CDATA\[(https?:\/\/(?:[\w-]+\.)?googlevideo\.com[^\s]*?)\]/, 1]
return {type: "url", value: video_url}
elsif html.include?("seedtag.com")
seedtag_ad_url = html.match(/CDATA\[(https:\/\/s\.seedtag\.com.+?)\]/)&.[](1)
seedtag_ad_response = Net::HTTP.get_response(URI(seedtag_ad_url))
seedtag_video_xml_url = seedtag_ad_response.body.match(/https\S+\.xml/)&.[](0)
seedtag_video_xml_response = Net::HTTP.get_response(URI(seedtag_video_xml_url))
video_url = seedtag_video_xml_response.body.scan(/\[CDATA\[(.+?)\]\]>/)&.last&.first
return {type: "url", value: video_url}
else
return {type: "html", value: html}
end
end
endCall the method with the link return from the Google Ads Transparency Center API.
extract_media("https://displayads-formats.googleusercontent.com/...")
# => {type: "url/html", "https://youtube.com..."}Example - HTML
Recently, embedded HTML can be seen even for the text format. Typically an image is used for text format ad creative, however, Google change this behavior for some of the results. This also happens to the image format:
https://displayads-formats.googleusercontent.com/ads/preview/content.js?client=ads-integrity-transparency&obfuscatedCustomerId=4767191304&creativeId=652893007655&uiFeatures=12,54&adGroupId=147178180266&itemIds=74274158300,74274158309&assets=%3DH4sIAAAAAAAAAOPS5OLg2NLU_ohVgBHI2gVmMQNZe6EsTo4fsxv75zEJMEqxcxw_umDRBRDj_vT_s2-BGP8XbFy7nwnIWLHrFpABAJJ0OedPAAAA&allowedVariations=36&sig=ACiVB_z14YeyZbl8Eczde5AMdalOrF3Ceg&htmlParentId=fletch-render-985385630188451790&responseCallback=fletchCallback985385630188451790Result:
{
"type": "html",
"value": "<!doctype html><html lang=\"en\" dir=\"ltr\"><head>..."
}
text format embedded HTMLExample - Youtube
Link that embed Youtube video:
https://displayads-formats.googleusercontent.com/ads/preview/content.js?client=ads-integrity-transparency&obfuscatedCustomerId=8912267936&creativeId=703600220351&uiFeatures=12&adGroupId=163161076785&allowedVariations=45&overlay=%3DH4sIAAAAAAAAAPNS4OJPrShJLcpLzAnLTEnN90wR4uXiDk4xLSn2Nkn1zXQFAGglAfMiAAAA&sig=ACiVB_zneUgDUg9Q20Sc7YDlW6A1jUEcwg&htmlParentId=fletch-render-921193701835509478&responseCallback=fletchCallback921193701835509478&nonce=yMfrPBp6TbOm5f6IKsd_rQResult:
{
"type": "url",
"value": "https://www.youtube.com/watch?v=Sd5tsK4eMiE"
}Example - Image
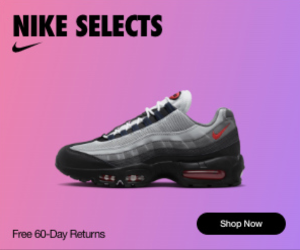
https://displayads-formats.googleusercontent.com/ads/preview/content.js?client=ads-integrity-transparency&obfuscatedCustomerId=8170128814&creativeId=679425072857&uiFeatures=12,54&sig=ACiVB_yqlUIG0AsLP_PmFJynMYanMQrsYQ&htmlParentId=fletch-render-16302302669006177687&responseCallback=fletchCallback16302302669006177687Result:
{
"type": "url",
"value": "https://s0.2mdn.net/simgad/16630466128080556319"
}
Example - Video from Seedtag
This link loads the video from Seedtag:
https://displayads-formats.googleusercontent.com/ads/preview/content.js?client=ads-integrity-transparency&creativeId=687501658736&obfuscatedCustomerId=1658279153&uiFeatures=12,54&sig=ACiVB_yVpezilBhNo5uGTBMbKCjo02LM0A&htmlParentId=fletch-render-12307508614539571586&responseCallback=fletchCallback12307508614539571586Result:
{
"type": "url",
"value": "https://video.seedtag.com/6582a9a137ba7e001d8c9aac/960x540-webm-800.webm"
}Solution in Javascript
const UNESCAPE_CHARS = new Proxy({}, {
get: (target, char) => {
if (char[0] === '\\') {
return char[1];
} else {
return char;
}
}
});
UNESCAPE_CHARS['\\0'] = '\0';
UNESCAPE_CHARS['\\a'] = '\u0007';
UNESCAPE_CHARS['\\b'] = '\b';
UNESCAPE_CHARS['\\t'] = '\t';
UNESCAPE_CHARS['\\n'] = '\n';
UNESCAPE_CHARS['\\v'] = '\v';
UNESCAPE_CHARS['\\f'] = '\f';
UNESCAPE_CHARS['\\r'] = '\r';
UNESCAPE_CHARS['\\u'] = '\\u';
UNESCAPE_CHARS['\\x'] = '\\x';
const JS_UNESCAPES = {
'\\u005c': '\\',
'\\u0027': "'",
'\\u0022': '"',
'\\u003e': '>',
'\\u003c': '<',
'\\u0026': '&',
'\\u003d': '=',
'\\u002d': '-',
'\\u003b': ';',
'\\u0060': '`'
};
const ESCAPED_CONTROL_CHARS = ['\\u0003', '\\u000b', '\\u0019', '\\u001d', '\\u001c'];
const CONTROL_CHARS = ESCAPED_CONTROL_CHARS.map(m => JSON.parse(`"${m}"`));
function unescapeJs(string) {
string = string.replace(/\\([0-7]{3})/g, (_, p1) => String.fromCharCode(parseInt(p1, 8)));
string = string.replace(/\\x([0-9a-fA-F]{1,2})/g, (_, p1) => String.fromCharCode(parseInt(p1, 16)));
let s = string.replace(/(?<!\\)(\\u[0-9a-fA-F]{4})+/g, m => {
try {
return JSON.parse(`"${m}"`);
} catch {
return m;
}
});
if (Buffer.from(s).toString() === s) {
string = s;
} else {
string = string.replace(/(\\u[0-9a-fA-F]{4})+/g, m => {
try {
return JSON.parse(`"${m}"`);
} catch {
return m;
}
});
}
string = string.replace(/(?<!\\)(\\(?:${Object.keys(JS_UNESCAPES).join('|')}))/gi, (_, p1) => JS_UNESCAPES[p1.toLowerCase()]);
string = string.replace(new RegExp(`(?<!\\\\)(\\\\(?:${ESCAPED_CONTROL_CHARS.join('|')}))`, 'gi'), '');
string = string.replace(new RegExp(`(${CONTROL_CHARS.join('|')})`, 'g'), '');
string = string.replace(/\\./g, m => UNESCAPE_CHARS[m]);
return string;
}
function prioritizeVideoUrl(url) {
const parsed = new URL(url);
parsed.searchParams.delete("uiFeatures");
return parsed.toString();
}
async function extractMedia(url) {
try {
const newUrl = prioritizeVideoUrl(url)
const response = await fetch(newUrl);
console.log(`Response - ${response.status}`);
const content = await response.text();
const matchingImage = content.match(/previewservice\.insertPreviewImageContent\('fletch.+', 'fletch.+', '(.+?)'/);
if (matchingImage) {
return { type: "url", value: matchingImage[1] };
}
const matchingHtml = content.match(/previewservice\.insertPreviewHtmlContent\('fletch.+', 'fletch.+', '(.+?)'/);
if (matchingHtml) {
const html = unescapeJs(matchingHtml[1]);
if (html.includes("lima-exp-data")) {
const videoId = html.match(/yt_video_id': '(.+?)'/)?.[1];
return { type: "url", value: `https://youtube.com/watch?v=${videoId}` };
} else if (html.includes("youtube") && html.includes("var adData")) {
const videoId = html?.match(/(?:video_id|video_videoId)': '(.+?)'/)?.[1];
return { type: "url", value: `https://youtube.com/watch?v=${videoId}` };
} else if (html.includes("googlevideo.com")) {
const videoUrl = html?.match(/CDATA\[(https?:\/\/(?:[\w-]+\.)?googlevideo\.com[^\s]*?)\]/)?.[1];
return { type: "url", value: videoUrl };
} else if (html.includes("seedtag.com")) {
const seedtagAdUrl = html.match(/CDATA\[(https:\/\/s\.seedtag\.com.+?)\]/)?.[1];
const seedtagAdResponse = await fetch(seedtagAdUrl);
const seedtagAdContent = await seedtagAdResponse.text();
const seedtagVideoXmlUrl = seedtagAdContent.match(/https\S+\.xml/)?.[0];
const seedtagVideoXmlResponse = await fetch(seedtagVideoXmlUrl);
const seedtagVideoXmlContent = await seedtagVideoXmlResponse.text();
const videoUrl = seedtagVideoXmlContent.match(/\[CDATA\[(.+?)\]\]>/)?.[1];
return { type: "url", value: videoUrl };
} else {
return { type: "html", value: html };
}
}
} catch (error) {
console.error('Error extracting media:', error);
return null;
}
}Conclusion
The script allows you to retrieve the actual content link by providing the displayads-format link. There may be content that the script doesn’t currently support. Therefore, we believe that by providing the script, you can easily make updates. If you would like to have the script in other programming language, feel free to contact me (terry@serpapi.com).
Add a Feature Request💫 or a Bug🐞