 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

Besides Google Images, Google offers a very powerful feature, search by image - Google Reverse Images. Google will analyze the visual content to provide related images, visually similar content.
There are plenty of reasons to scrape Google Reverse Image results. Scraping Google Reverse Image results can help Intellectual Property Protection. You can monitor your copyrighted or proprietary images on the internet. You can also monitor brand images and keep track of your public branding. For Journalists, researchers, or content creators, scraping reverse images can verify the authenticity of images. Many startups use AI to empower their products and they can scrape similar images to feed on their AI content and identify trends.
Scraping Google results is always challenging, and it is easy to get blocked by Google. With SerpApi, you don't need to worry about it. We have provided the SerpApi Google Reverse Image API at a high-quality with a reasonable price.

Scrape your first Google Reverse Image results with SerpApi
Head to the Google Reverse Image Results documentation on SerpApi for details.
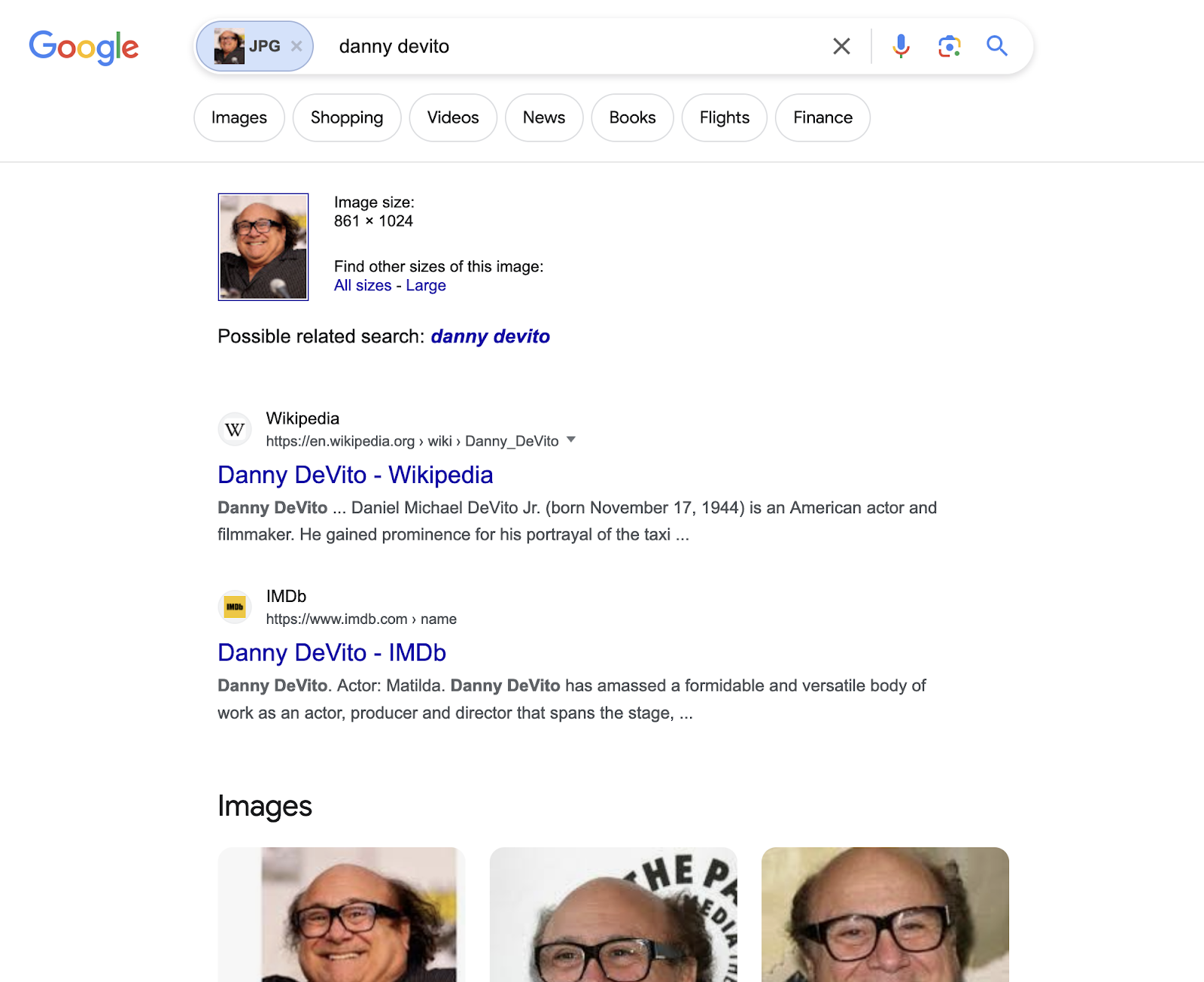
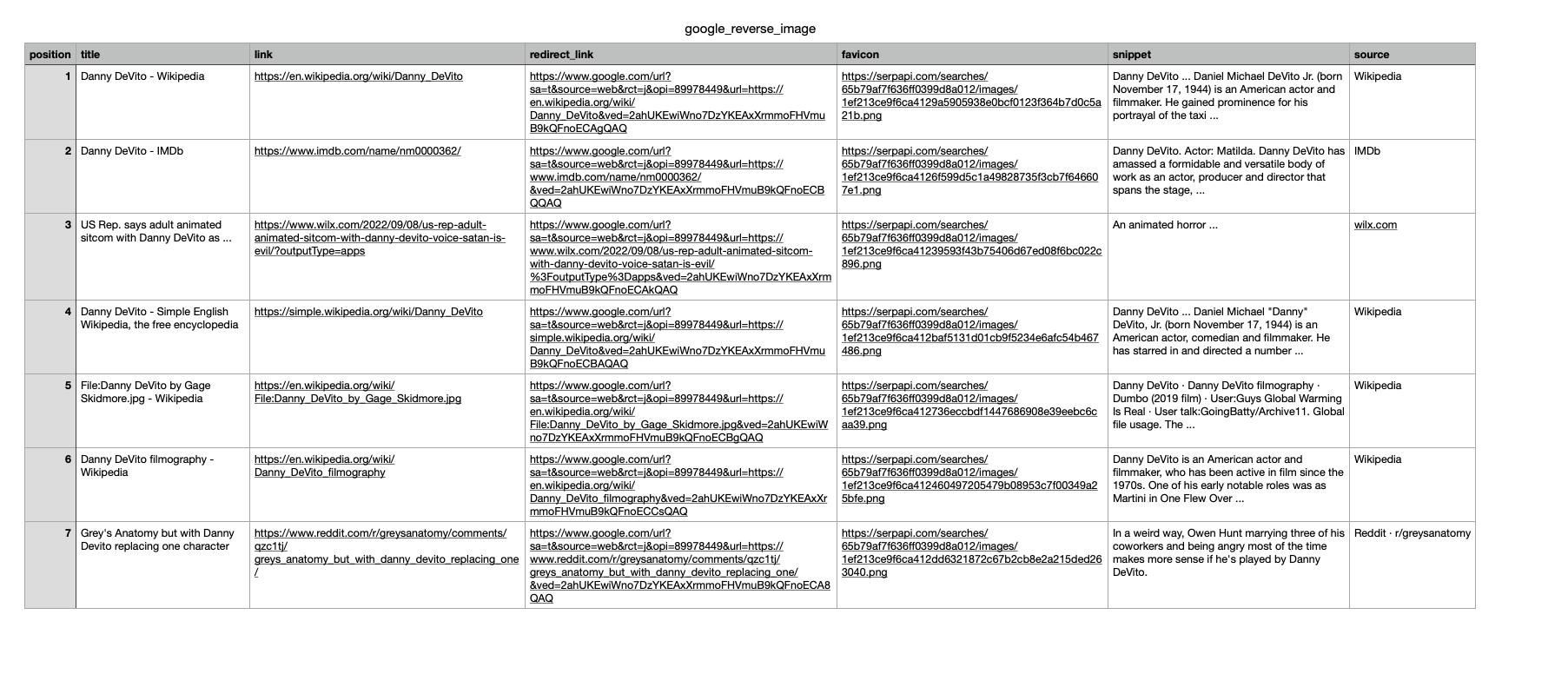
In this tutorial, we will scrape and extract all sources of the "Danny DeVito" image. The data contains: "position", "title", "link", "redirect_link", "favicon", "snippet", "source" and more. You can also scrape more information with SerpApi.
First, you need to install the SerpApi client library.
pip install google-search-resultsSet up the SerpApi credentials and search.
import serpapi, os, json
params = {
'api_key': 'YOUR_API_KEY', # your serpapi api
'engine': 'google_reverse_image', # SerpApi search engine
'image_url': 'https://i.imgur.com/HBrB8p0.png'
}
To retrieve Google Reverse Image Results for a given image url, you can use the following code:
client = serpapi.Client()
results = client.search(params)['image_results']You can store Google Reverse Image Results JSON data in databases or export them to a CSV file.
import csv
header = ['position', 'title', 'link', 'redirect_link', 'favicon', 'snippet', 'source']
with open('google_reverse_image.csv', 'w', encoding='UTF8', newline='') as f:
writer = csv.writer(f)
writer.writerow(header)
for item in results:
print(item)
writer.writerow([item.get('position'), item.get('title'), item.get('link'), item.get('redirect_link'), item.get('favicon'), item.get('snippet'), item.get('source')])
This example is using Python, but you can use your favorite programming languages like Ruby, NodeJS, Java, PHP, etc.
If you have any questions, please feel free to contact me.
