 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 C++
C++

Here are several ways to get all URLs from a domain. Depending on your use case, you can use a code or no-code solution.

1. Website Sitemap (No Code Solution)
It's very common for a website to provide a sitemap containing information about its available pages.
What is a sitemap?
A sitemap is a file where we provide information about the pages, videos, and other files on our site, and the relationships between them. Search engines like Google read this file to crawl your site more intelligently. Sitemaps can be in the form of XML files, which are more common and used by search engines, or HTML files, which are typically intended for human visitors.
Here is an example of our Blog's sitemap:
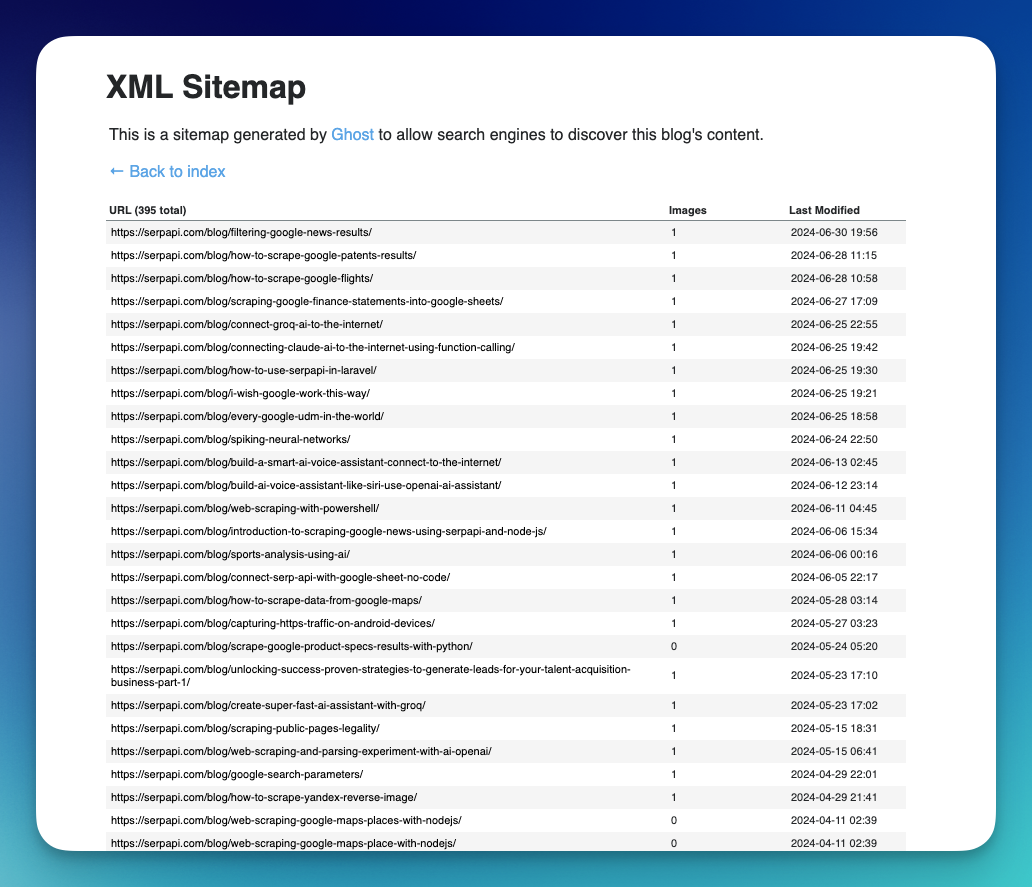
Usually, you can find the URL to the website's sitemap on the feature (But that's not always the case!). You can also try accessing anydomain.com/sitemap.xml , sitemap.xml is most likely where people put their Sitemap files.
How to create a sitemap for your site?
Many online tools can help you with this. Try Googling "sitemap online generator."
2. Screaming Frog (No Code Solution)
Screaming Frog is a website crawler tool used primarily for SEO (Search Engine Optimization). It enables users to crawl websites' URLs and analyze various elements and data points.
Crawling all the pages is just one of the features that Screaming Frog offers. You can download Screaming Frog and try to find all available pages on a website for free.
Note: The free version has a 500 URL limitation. You can purchase the paid version for more features.
3. Search at Google
To find all available pages on a specific domain using Google, enter "site.com" into the Google search bar. This search query will return a list of indexed pages from that domain, helping you quickly identify the available content.
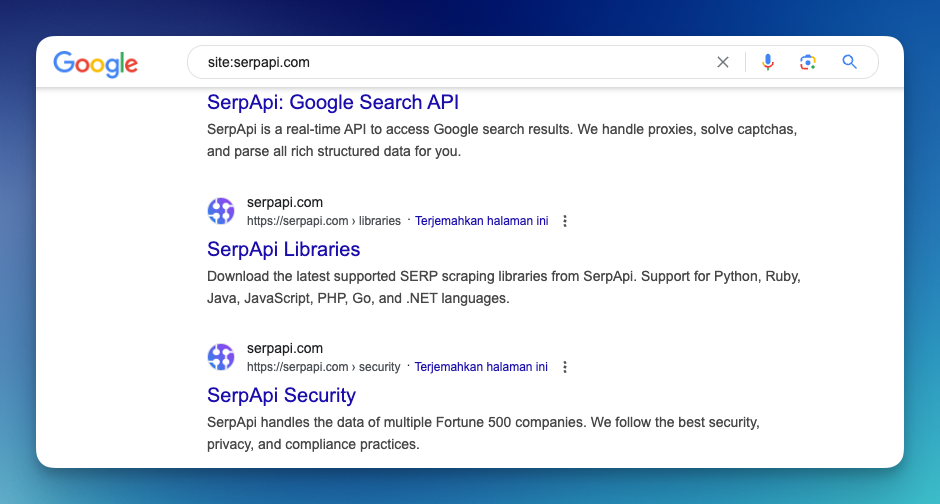
Caveat: Like a Sitemap, the website author can decide whether to provide all the pages on the list by blocking a specific page with a robots.txt file.
Okay, we can Google for all the available pages, but how to collect this data?
Collect the results programmatically with SerpApi
Here at SerpApi, we focus on scraping search engines like Google, so you can grab the data programmatically without implementing a web scraping solution on your own.
Take a look at our Google Search Result API. Here is an example on our playground to grab a list of pages via Google Search: Response example.
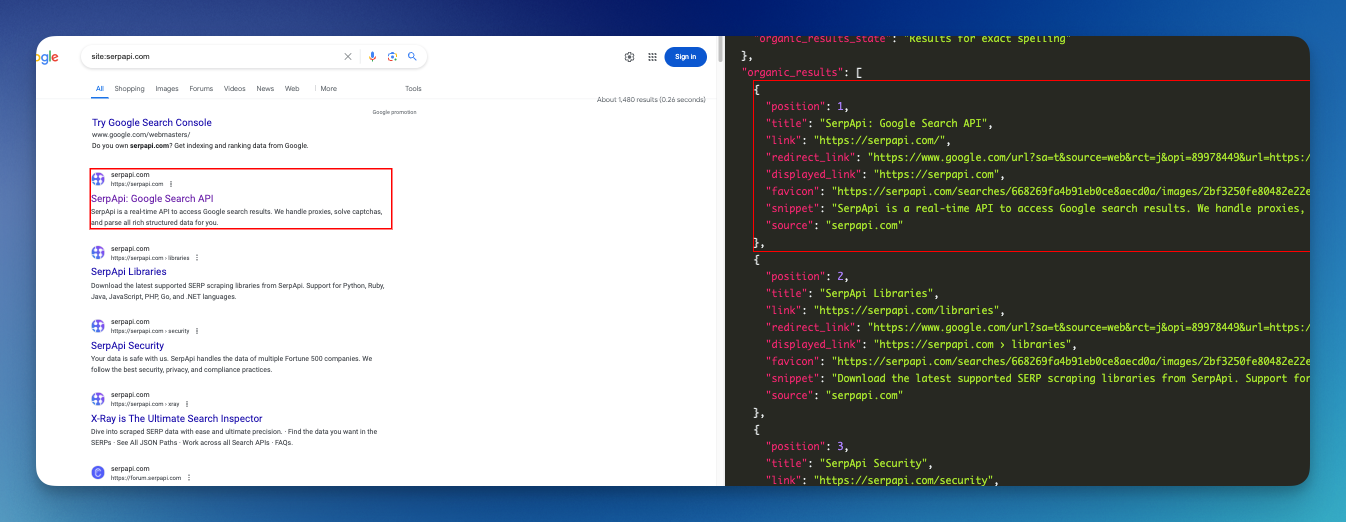
The key organic_results includes all the information you need. You can then store these results on a CSV file or in an Excel format programmatically.
4. Implement your own scraping solution (NodeJS)
We can also write our own code for this. You can use any language you're comfortable with, but I'll use NodeJS.
Logic/Flow
Here is the step-by-step how to implement the logic to crawl all the pages on a website:
- Send a request to the main page
- Parse if there is any anchor tag (A tag in HTML) or any links
- Check if the link belongs to this domain (it can be a relative or absolute path)
- Scrape the new URL we got
- Repeat the second step
- Make sure to ignore if the URL already exists
The code sample in GitHub
The source code is available on GitHub
 hilmanski
hilmanskiStep-by-step Nodejs implementation
If you're curious about how it's made, feel free to follow this tutorial.
Initiate a new project
Run npm init -y to start a new project
Install packages
We're using Axios to send the request and Cheerio to parse the page
npm i axios cheerioCode
Here is the code implementation. Create a new file called index.js and paste this code in:
const axios = require('axios');
const cheerio = require('cheerio');
const url = require('url');
// Feel free to update with your own website URL
const websiteUrl = 'https://example.com';
async function scrapeWebsite(websiteUrl) {
const visitedUrls = new Set();
const urlsToVisit = [websiteUrl];
const allLinks = new Set();
while (urlsToVisit.length > 0) {
const currentUrl = urlsToVisit.pop();
if (visitedUrls.has(currentUrl)) continue;
try {
console.log(`Scraping: ${currentUrl}`);
const response = await axios.get(currentUrl, { timeout: 10000 });
visitedUrls.add(currentUrl);
const $ = cheerio.load(response.data);
$('a').each((i, link) => {
const href = $(link).attr('href');
if (href) {
const absoluteUrl = url.resolve(websiteUrl, href);
const parsedUrl = new URL(absoluteUrl);
// Only process URLs from the same website
if (parsedUrl.hostname === new URL(websiteUrl).hostname) {
allLinks.add(absoluteUrl);
if (!visitedUrls.has(absoluteUrl) && !urlsToVisit.includes(absoluteUrl)) {
urlsToVisit.push(absoluteUrl);
}
}
}
});
// Wait for a second before making the next request (Optional)
await new Promise(resolve => setTimeout(resolve, 1000));
} catch (error) {
console.error(`Error scraping ${currentUrl}:`, error.message);
}
}
return Array.from(allLinks);
}
scrapeWebsite(websiteUrl)
.then(urls => {
console.log('Scraped URLs:');
urls.forEach(url => console.log(url));
console.log(`Total unique URLs found: ${urls.length}`);
})
.catch(error => {
console.error('Error:', error);
});I hope it's helpful. Feel free to try!