 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

In this post, we will talk about how important the ad results are and how to extract the ad result, not for a single-engine, but for all engines at once, in one simple tool example.
Intro
There might be someone out there asking, it would be very useful to have one engine for each result, for example, one engine to extract all ad results of the other engines combined, well, you don't need an engine to do that! You can do it easily.
The ad results are so important for many companies, shopping companies, SEO companies, and advertisement companies.
Requirements
Python 3.x and the following libraries:
import requests
from serpapi import GoogleSearch
import json
import os
import urllib.parse as urlparse
from urllib.parse import urlencodeAll these libraries are optional if you want to use alternatives or your own, we are using these libraries to send requests, saving and formatting the JSON result, and of course the serpapi library.
On line '10' you must enter your API key,
You can grab your API key from here.
api_key = "YOUR API KEY"
query_search This is the search query you want to search for it.
The engines and the parameters: You can enter any engine you like with the search parameters.
engines = [
{"name": "google", "query": "q", "ad_param": "ads"},
# {"name": "baidu", "query": "q", "ad_param": ""},
{"name": "bing", "query": "q", "ad_param": "ads"},
{"name": "duckduckgo", "query": "q", "ad_param": "ads"},
{"name": "yahoo", "query": "p", "ad_param": "ads_results"},
# {"name": "yandex", "query": "text", "ad_param": ""},
# {"name": "ebay", "query": "_nkw", "ad_param": ""},
{"name": "youtube", "query": "search_query", "ad_param": "ads_results"},
{"name": "walmart", "query": "query", "ad_param": "ads_results"},
# {"name": "home_depot", "query": "q", "ad_param": ""},
]The rest is just easy to understand code, pagination, and calling the library.
Getting started
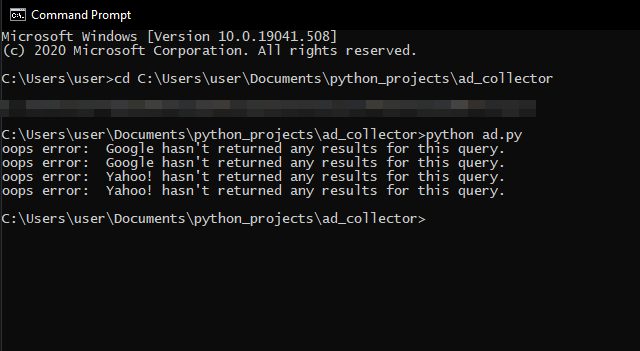
After downloading the tool that can be found on GitHub , all you need is to start the tool by using this command from CMD:
python ad.pyAfter that, we gonna wait for a couple of minutes, and we will get our results as a JSON file.
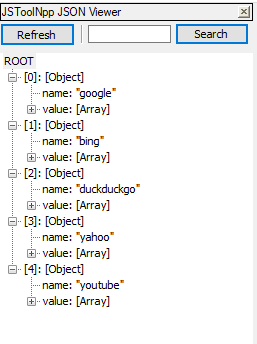
This will be the structure of the JSON result file:
Remember the tool takes a long time to extract the results because we're getting the results from all pages available in each engine and for each search result.
Full Code
import requests
from serpapi import GoogleSearch
import json
import os
import urllib.parse as urlparse
from urllib.parse import urlencode
path = os.path.dirname(os.path.abspath(__file__))
ad_results = []
api_key = "YOUR API KEY"
query_search = "Coffee"
output_file = path+'/results.json'
engines = [
{"name": "google", "query": "q", "ad_param": "ads"},
# {"name": "baidu", "query": "q", "ad_param": ""},
{"name": "bing", "query": "q", "ad_param": "ads"},
{"name": "duckduckgo", "query": "q", "ad_param": "ads"},
{"name": "yahoo", "query": "p", "ad_param": "ads_results"},
# {"name": "yandex", "query": "text", "ad_param": ""},
# {"name": "ebay", "query": "_nkw", "ad_param": ""},
{"name": "youtube", "query": "search_query", "ad_param": "ads_results"},
{"name": "walmart", "query": "query", "ad_param": "ads_results"},
# {"name": "home_depot", "query": "q", "ad_param": ""},
]
def get_next(engine, results):
out = []
current = []
if engine["ad_param"] in results:
ads = results[engine['ad_param']]
out = out + ads
current.append(results.get('serpapi_pagination').get('current'))
while 'next' in results.get('serpapi_pagination'):
url = results.get('serpapi_pagination').get('next')
url_parse = urlparse.urlparse(url)
query = url_parse.query
url_dict = dict(urlparse.parse_qsl(query))
url_dict.update(params)
url_new_query = urlparse.urlencode(url_dict)
url_parse = url_parse._replace(query=url_new_query)
new_url = urlparse.urlunparse(url_parse)
response = requests.get(new_url, timeout=60000)
results = dict(json.loads(response.text))
if "error" in results:
print("oops error: ", results["error"])
break
if results.get('serpapi_pagination').get('current') in current:
break
current.append(results.get('serpapi_pagination').get('current'))
if engine["ad_param"] in results:
ads = results[engine['ad_param']]
out = out + ads
for engine in engines:
params = {
"engine": engine["name"],
engine["query"]: query_search,
"api_key": api_key
}
search = GoogleSearch(params)
results = search.get_dict()
if "error" in results:
print("oops error: ", results["error"])
continue
next_results = get_next(engine, results)
if next_results:
ad_results.append({"name": engine["name"], "value": next_results})
with open(output_file, 'w') as fout:
json.dump(ad_results , fout)
Tips
- Don't forget your API key in the tool when you upload it on your GitHub, Your API key should be treated as a password.
- Try to change the pagination, limit them maybe to get the result faster.
Ending
You can find the documentation about how to use serpapi and you can follow us on Twitter at @serp_api, to get our latest news and articles.
