 Ruby
Ruby
 Golang
Golang
 .Net
.Net
 MCP
MCP
 C++
C++

Creating a custom database for a machine learning project can be messy, and most of the time, complicated. In the context of this example, this blog post will cover retrieving SerpApi's Google Images Scraper API.
There is a number of challenges one faces in creating an image database that can fulfill specific needs. Here are some main concerns about such an undertaking:
Finding images in bulk
a) The source has to have an abundance of images with a clear pathway to retrieve them.
Retrieving images
a) The script to retrieve images shouldn't take too much optimization.
b) Accepted image types should be expressed not to cause any incompatibility with other packages.
c) The method has to be fast, transparent about the time it takes.
d) The method has to be reliable, without interruption.
e) The method should allow custom queries to be retrieved, not just a specific set of them.
f) The method should not be reliant on any language for reproducibility.
Placing images in their right place.
a) Duplication of images must be omitted.
b) Each image has to be in its corresponding place.
c) Overall result should be adaptable to any machine learning library of any language.
For this undertaking, programming language that will be used is Julia as it is designed for machine learning and statistics tasks with a faster runtime performance. However, any other language can be used in order to achieve the same results.
You can find the github repo for all files mentioned below at custom-image-database-maker
Here are the libraries to use;
module DatabaseMaker
using HTTP
using JSON3
using CSV
using DataFrames
export makeTo give a clear breakdown of why we use these packages in the code;
HTTP : SerpApi can be used to retrieve data using HTTP requests.
JSON3 : SerpApi's response will be in an easy to understand JSON body.
CSV : This package is used to get list of queries, and to report the images we retrieved in a CSV table.
DataFrames : This package is used to interpret and modulate CSV tables in question.
export make is the overall function of interest to export from this module (DatabaseMaker) for other files to be used. Every other function feeds make function.
Let's start by giving the make() function:
function make()
global images_to_be_requested = []
ask_for_query_preference()
println("---------------------")
ask_for_cache_preference()
println("---------------------")
get_api_key()
println("---------------------")
construct_searches()
println("---------------------")
download_images()
endAll the other functions below will be used to feed this main function to properly do its task. For an overall view of the process, here's a scheme of operation:
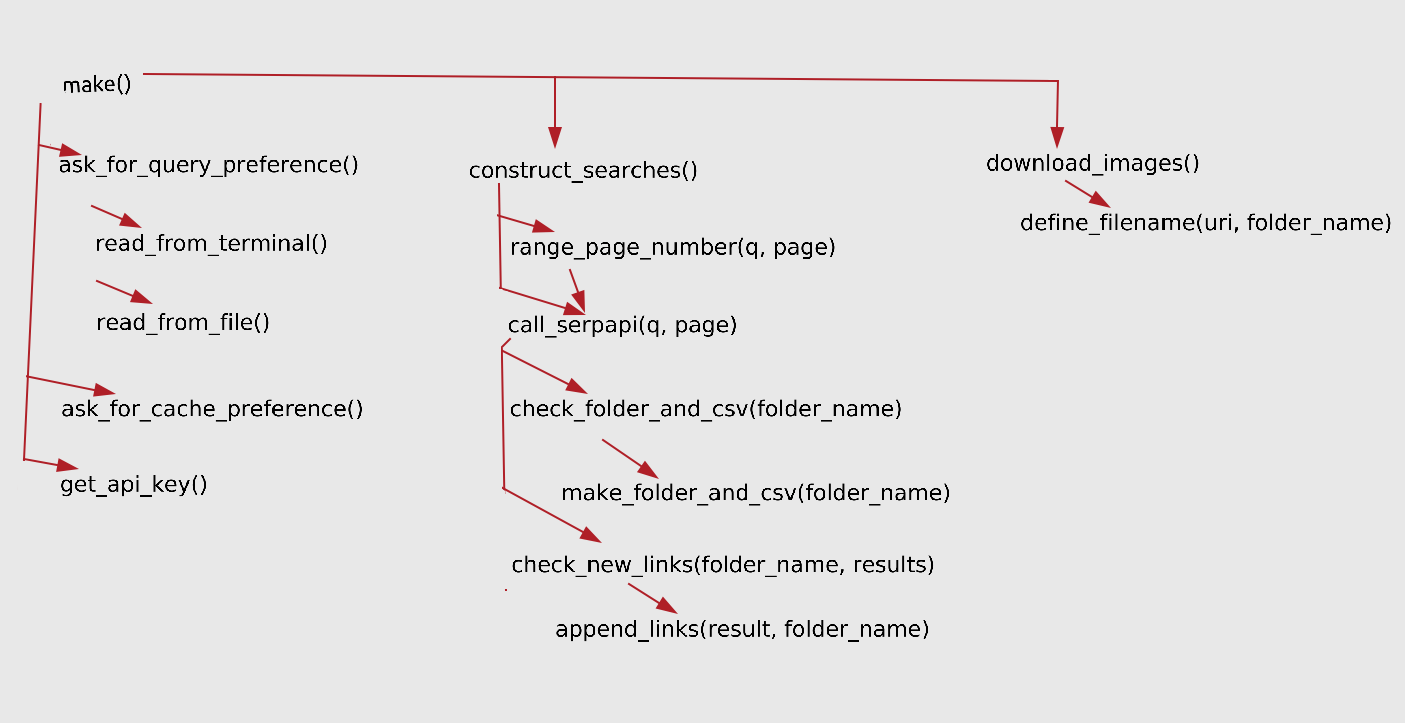
Let's define the first function to be used to feed make():
function ask_for_query_preference()
println("Would you like to add queries from terminal or from a local file?")
println("1) Terminal (first page per each query)")
println("2) Local File (can define page ranges)")
println("Enter a number: ")
answer = readline()
answer == "1" && read_from_terminal()
answer == "2" && read_from_file()
endThis function asks the user for the preference of entry of queries. Local file in context is a csv file a user can fill, whereas terminal entry is a collection of queries seperated by commas.If the answer is 1, the script will read from the terminal. If the answer is 2, the script will read from the file. The CSV file will be able to pick up range of pages(Ex. 0-11) whereas terminal entry will only retrieve the first page of the query. Here's the output:
Would you like to add queries from terminal or from local file?
1) Terminal (first page per each query)
2) Local File (can define page ranges)
Enter a number:
Let's define the function for reading from terminal:
function read_from_terminal()
println("Enter queries seperated by commas:")
queries = readline()
queries = split(queries, ",")
global queries = DataFrame( q = queries, page_range = fill(0, length(queries)) )
endread_from_terminal() function will ask for queries, and read the answer. It will then seperate the queries by commas. For example dog,cat,banana,apple will create a global array (that is defined for all functions) that consists of 4 elements: ["dog","cat","banana","apple"].
Next line is to make it into a dataframe to make it coherent with reading from a file.
global queries = DataFrame( q = queries, page_range = fill(0, length(queries)) )Here's the output:
Enter queries seperated by commas:
Next part is to define the function that reads from the terminal:
function read_from_file()
println("Reading from file...")
types = Dict(
:q => String,
:page_range => String,
)
queries = DataFrame(CSV.File("load_new_data.csv"; types))
global queries = coalesce.(queries, 0)
endread_from_file() function will read the CSV file called load_new_data.csv to fetch an array of queries with their desired page range. What is meant by page range here is SerpApi Google Images Scraper API's pagination.
Here's an example of a CSV structure:
| q | page_range |
|---|---|
| Apple | 0 |
| Banana | 1 |
| Cat | 0-11 |
| Dog |
To break it down to its components;
q stands for query.
page_range stands for specific page range, or a specific page.
First entry, Apple has a page range of 0. This means request to SerpApi will be made only for the first page. (ijn parameter starts from 0 which will be explained in the upcoming parts.)
For second entry, Banana, we ask only for the second page which its ijn value is 1
Cat has a range between 0-11 (0 and 11 included). This means that it is necessary to make 12 requests to SerpApi with the same q value but different ijn in order to get all pages.
Dog doesn't have any page range. By default, it will be considered 0 (first page).
types = Dict(
:q => String,
:page_range => String,
)
queries = DataFrame(CSV.File("load_new_data.csv"; types))global queries = coalesce.(queries, 0)The output is;
Reading from file...
The next function we will build is about a nice feature of SerpApi, cache preference.
function ask_for_cache_preference()
println("Would you like cached data? (Note that cached searches don't use calls from your account. But if the query is not cached, it'll resort to \"no_cache=true\")")
println("1) No Cached Searches (true)")
println("2) Cached Searches (false)")
println("Enter a number: ")
answer = readline()
answer == "1" && global cache_preference = true
answer == "2" && global cache_preference = false
println(cache_preference)
endIf a search, has been cached in SerpApi's database, one can call it without spending any credits. However, it might not be a real time data. Hence, it is wise to add a no_cache=true option in there. This function will set a global variable cache_preference.
Here's the output;
Would you like cached data? (Note that cached searches don't use calls from your account. But if the query is not cached, it'll resort to "no_cache=true")
1) No Cached Searches (true)
2) Cached Searches (false)
Enter a number:
We also need a function to get the API key we retrieved from:
https://serpapi.com/manage-api-key
function get_api_key()
global api_key = read(Base.getpass("Enter your API key:"), String)
endBase.getpass() is used not to show any string on the screen when reading the input from the user. A global variable called api_key is declared within the function.
Output;
Enter your API key:
Here comes function we construct the searches based on our entries:
function construct_searches()
for (index,q) ∈ enumerate(queries[:,:q])
page = queries[index,:page_range]
occursin("-", string(page)) ? range_page_number(q, page) : call_serpapi(q, page)
end
endNote that ∈ here stands for in in many programming languages. This function iterates through global dataframe variable we declared before, queries. For each query it declares a local page variable and checks if it includes - in its substring.
If it includes -, for example 0-11, the function calls another function called range_page_number(q, page).
If it is only one page, for example 0, the function calls call_serpapi(q, page) function.
Let's continue with how the function for the range of pages work:
function range_page_number(q, page)
page = split(page, "-")
from = parse(Int,page[1])
to = parse(Int,page[2])
for page ∈ from:to
call_serpapi(q, page)
end
endrange_page_number takes in two variables, namely, q and page.
page = split(page, "-")Let's assume that the q is Cat and page is 0-11. In this function 0-11 is split from - substring and becomes an array of two strings, ["0","11"]
from = parse(Int,page[1])
to = parse(Int,page[2])Then from local variable is declared from the first element of that array as an integer, 0. Likewise, to variable is declared.
for page ∈ from:to
call_serpapi(q, page)
endHaving from and to variables, iteration is possible, individual call for each page is made to SerpApi with call_serpapi(q, page).
Let's see how call_serpapi(q, page) works:
function call_serpapi(q, page)
params = [
"q" => q,
"tbm" => "isch",
"ijn" => page,
"api_key" => api_key,
"no_cache" => cache_preference,
]
uri = "https://serpapi.com/search.json?"
println("Querying \"q\":\"$(q)\", \"ijn\":\"$(page)\" with \"no_cache\":\"$(cache_preference)\"...")
results = HTTP.get(uri, query = params)
results = JSON3.read(results.body)
results = results[:images_results]
results = [resulting_image[:original] for resulting_image ∈ results]
println("Checking if folder and csv exists...")
folder_name = replace(q, " " => "_")
folder_name = replace(folder_name, "." => "_")
check_folder_and_csv(folder_name)
check_new_links(folder_name, results)
endThis function is used to call SerpApi to get an easy-to-understand JSON body. We will be using 5 parameters in our call to achieve this:
params = [
"q" => q,
"tbm" => "isch",
"ijn" => page,
"api_key" => api_key,
"no_cache" => cache_preference,
]Let's break it down:
q => q, declares the query string from the local variable q.
tmb => isch declares that the engine to use is Google Image Search Scraper API.
ijn => page declares the page number from the local variable page.
api_key => api_key declares the API key gathered from the user.
no_cache => cache_preference declares the cache preference.
Next step is to make a call to SerpApi with HTTP package:
uri = "https://serpapi.com/search.json?"
results = HTTP.get(uri, query = params)Here's an resulting example of a URI:
https://serpapi.com/search.json?q=cat&tmb=isch&ijn=0&api_key=YOURAPIKEY
Results will be in JSON format. Links of each individual image should be retrieved from this JSON body. In order to parse the JSON body these three lines of code are required;
results = JSON3.read(results.body)
results = results[:images_results]
results = [resulting_image[:original] for resulting_image ∈ results]But first, let's see what an actual result looks like to dig deeper into the concept. In order to demonstrate it, we will use another nice feature of SerpApi, the playground. Playground is where you can see the resulting HTML alongside the JSON response, and play around with parameters to come up with different results.
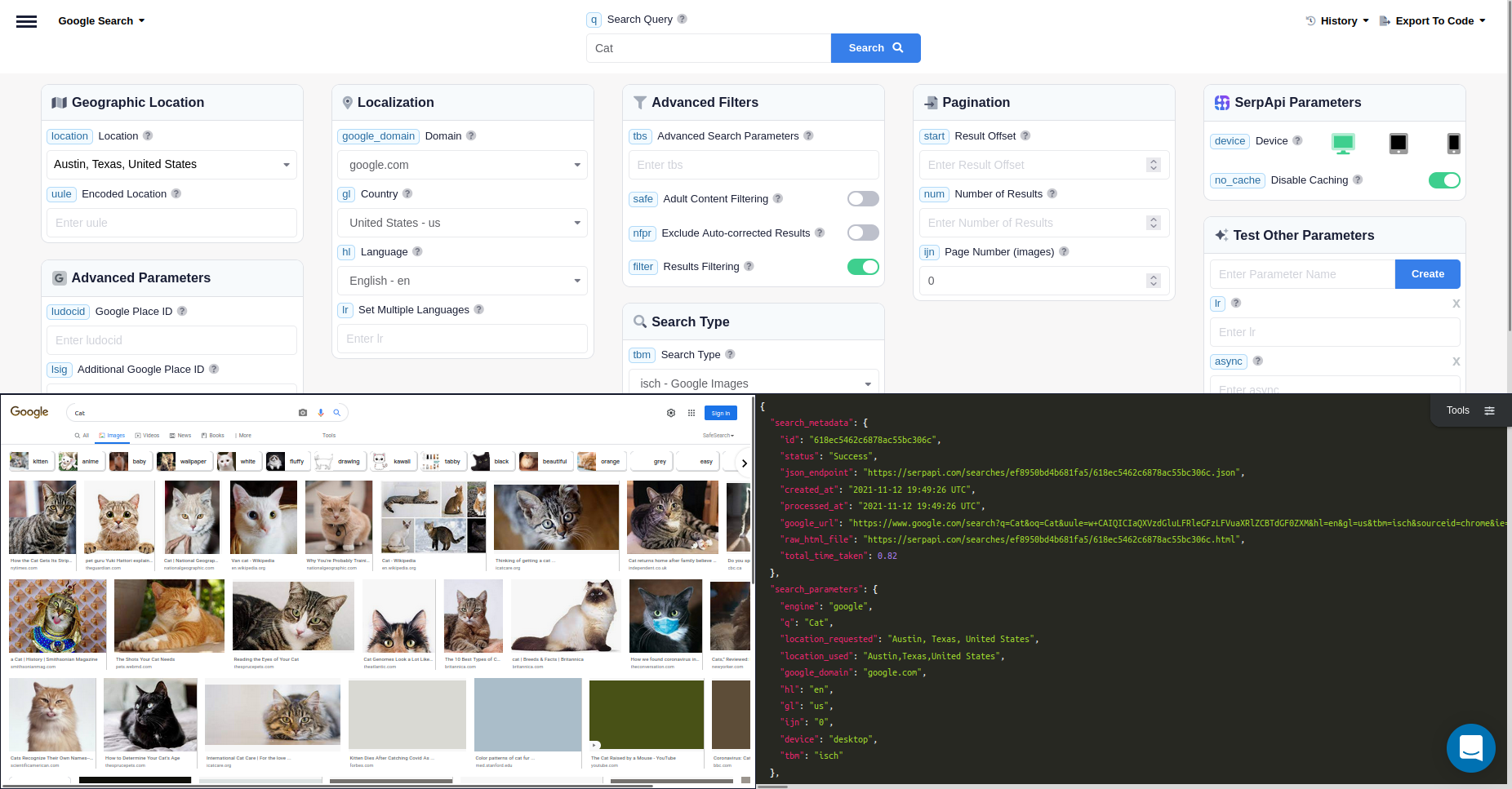
Let's take a look at what can be found at a JSON body:
"images_results": [
{
"position": 1,
"thumbnail": "https://serpapi.com/searches/618ec5462c6878ac55bc306c/images/f4e30dbda435a4130ee31007b1d0dba9f2e294d52c9203b54aaa018192636b86.jpeg",
"source": "nytimes.com",
"title": "How the Cat Gets Its Stripes: It's Genetics, Not a Folk Tale - The New York Times",
"link": "https://www.nytimes.com/2021/09/07/science/cat-stripes-genetics.html",
"original": "https://static01.nyt.com/images/2021/09/14/science/07CAT-STRIPES/07CAT-STRIPES-mediumSquareAt3X-v2.jpg",
"is_product": false
},
...images_results key contains an array of images. original key within an individual result gives the original link for the image. The idea is to make an array out of these individual links to be downloaded. Local results variable will be an array of strings containing links to images in the end. (Ex. ["https://google.com/cat-image.jpg",...])
Lines below will make a folder name out of the query:
folder_name = replace(q, " " => "_")
folder_name = replace(folder_name, "." => "_")
In the end, images retrieved from the cat query would end up in cat folder whereas images of cat food would be placed inside cat_food.
Each image has to be inside their own folder so that coherent body of images could be loaded into the model later. But first, the script has to check if there is a folder under that name and if it contains a CSV file.
check_folder_and_csv(folder_name)
Let's dig into how the folder name is checked:
function check_folder_and_csv(folder_name)
folder_name ∉ readdir("Datasets") && make_folder_and_csv(folder_name)
endIf the there is no folder with the name cat inside Datasets in our example, make_folder_and_csv(folder_name) gets into action.
function make_folder_and_csv(folder_name)
mkdir("Datasets/$(folder_name)")
initial_csv = DataFrame()
initial_csv.link = []
CSV.write("Datasets/$(folder_name)/links.csv", initial_csv)
endThis function creates a cat folder and also creates an empty links.csv file within it. This file will be used to avoid duplicate image links to be downloaded in the future.
Last line in call_serpapi() function is responsible for checking if the links are unique and hasn't been downloaded before.
check_new_links(folder_name, results)Here's the full function:
function check_new_links(folder_name, results)
println("Reading links of \"Datasets/$(folder_name)\"")
types = Dict(
:link => String,
)
global links = DataFrame(CSV.File("Datasets/$(folder_name)/links.csv"; types))
println("Comparing new links with links of \"Datasets/$(folder_name)\"")
for result ∈ results
accepted_filetypes = [".bmp", ".png", ".jpg", ".jpeg", ".png"]
length(links[:,:link]) ≠ 0 && result ∉ links[:,:link] && any(x->occursin(x,last(result,5)), accepted_filetypes) && append_links(result, folder_name)
length(links[:,:link]) == 0 && append_links(result, folder_name)
end
println("Updating links of \"Datasets/$(folder_name)\"")
CSV.write("Datasets/$(folder_name)/links.csv", links)
endThese four lines create a global dataframe variable named links out of the links.csv file within the specified folder name. The path to it will be Datasets/cat/links.csv in our example:
types = Dict(
:link => String,
)
global links = DataFrame(CSV.File("Datasets/$(folder_name)/links.csv"; types))This line will iterate through each result:
for result ∈ resultsLet's declare a specific set of filenames to be picked from the results so that it won't cause a problem when downloaded and loaded to the model:
accepted_filetypes = [".bmp", ".png", ".jpg", ".jpeg", ".png"]If links is not empty and result has the specified conditions, append it and its folder_name (Ex. ["https://image.com/cat.jpg","cat"] ) with a function.
length(links[:,:link]) ≠ 0 && result ∉ links[:,:link] && any(x->occursin(x,last(result,5)), accepted_filetypes) && append_links(result, folder_name)Let's dig into how the append_links() function works:
function append_links(result, folder_name)
result_row = DataFrame(Dict(:link=>result))
append!(links, result_row)
append!(images_to_be_requested, [[result,folder_name]])
endMaking a dataframe row out of the result and adding it to links dataframe will keep track of the uniqueness of URIs to be requested. images_to_be_requested is a global array declared within the main make function which will be revealed below. In the end we will end up with [["https://image.com/cat.png","cat"]...] as our images_to_be_requested array.
If the links array is empty, result and folder_name are directly appended in same structure:
length(links[:,:link]) == 0 && append_links(result, folder_name)When the links are ready, we write them to our links.csv
CSV.write("Datasets/$(folder_name)/links.csv", links)Up until this point; an array full of links and their corresponding folders have been fed into a global array, namely images_to_be_requested. All the links in this array has been appended to links.csv inside each corresponding folder without creating duplicates. Now comes the easy part, to download images into their corresponding folder:
function download_images()
println("$(length(images_to_be_requested)) images to be downloaded...")
for image ∈ images_to_be_requested
uri = image[1]
folder_name = image[2]
filename = define_filename(uri, folder_name)
println("Downloading into \"$(filename)\"...")
HTTP.download(uri,filename)
println("---------------------")
end
println("Downloaded all images!")
endThese lines iterate through images_to_be_requested, and downloads individual images to their corresponding folders:
for image ∈ images_to_be_requested
uri = image[1]
folder_name = image[2]
filename = define_filename(uri, folder_name)
println("Downloading into \"$(filename)\"...")
HTTP.download(uri,filename)
println("---------------------")
endLet's break down define_filename(uri,folder_name) to understand the process:
function define_filename(uri, folder_name)
filename = readdir("Datasets/$(folder_name)")
deleteat!(filename, findall(x->x=="links.csv", filename))
if length(filename) == 0
filename = "1"
else
filename = [parse(Int, split(name,".")[1]) for name ∈ filename]
filename = maximum(filename) + 1
end
extension = last(split(uri,"."))
filename = "Datasets/$(folder_name)/$(filename).$(extension)"
return filename
endThis function uses folder_name to check if there are any images previously downloaded to give the image a number. It starts from 1. For example, maximum number a file has is 5, the name to be picked will be 6. uri variable is used for giving the proper extension to the file. Resulting filename will be the full path to be downloaded. It will be fed back into download_images().
Let's call the module from another file for further improvements in the future.
include("./DatabaseMaker.jl")
using .DatabaseMaker
DatabaseMaker.make()
This concludes the task to build a custom Image database maker using SerpApi's Google Images Scraper API.
Here's a showcase of how it works:
Conclusion
SerpApi is a powerful tool for a variety of tasks including creating databases with customized datasets.
This is only one use case of the tool which could be expanded with other features of SerpApi, and be used for machine learning projects.